


Just a quick blog to hopefully demonstrate from my recent experience with an Alteryx weekly challenge how valuable some RegEx knowledge can be when looking to simplify workflows.
I've been looking to improve my Alteryx knowledge recently with placements coming up and decided to do a couple of weekly challenges to sharpen up.
The challenge covered in this blog is linked below in case you want to try your hand at completing it yourself either before or after reading this blog:
Alteryx Weekly Challenge #207: Parsing Video Game Data
 AYXAcademy Alteryx
AYXAcademy Alteryx
Part 1 - A series of Unfortunate Events (First attempt with minimal RegEx):
Firstly i'll give a few examples of my initial attempt at this challenge which used very little regex and is just a very long winded workflow overall. I definitely don't recommend trying to replicate this as im sure there are many better ways of getting to the answer in a more efficient way but this is just a reference to show how regex can help.
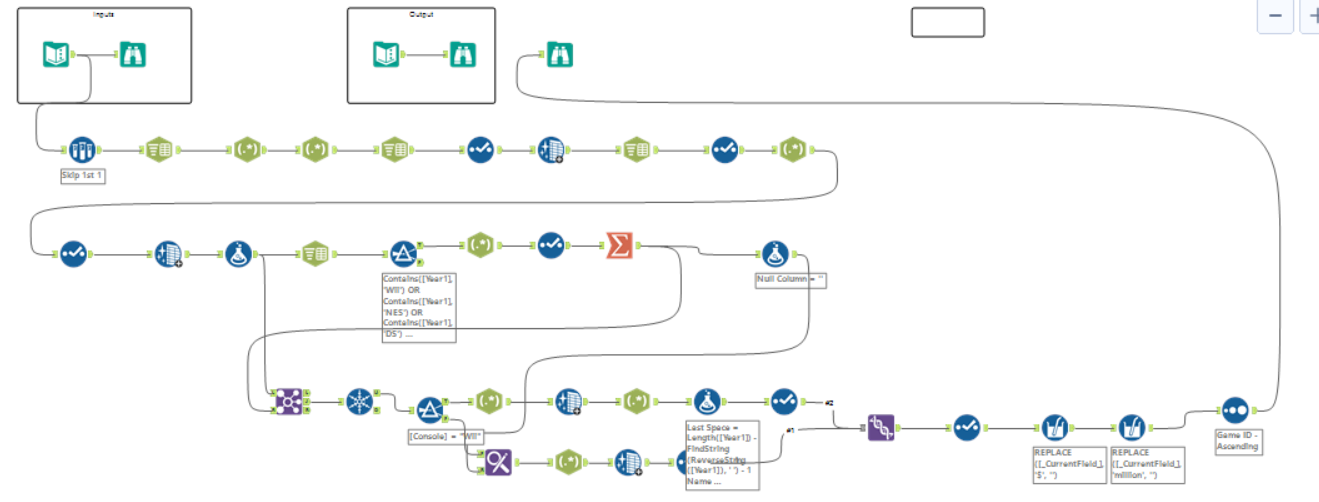
I initially started with parsing things out the more traditional way by splitting to columns on delimiters and then cleaning up the resulting fields that were produced. This was followed by a fairly hard-coded method for getting the gaming platforms (PS4, Wii etc...) out by splitting to rows and grouping by the platform.
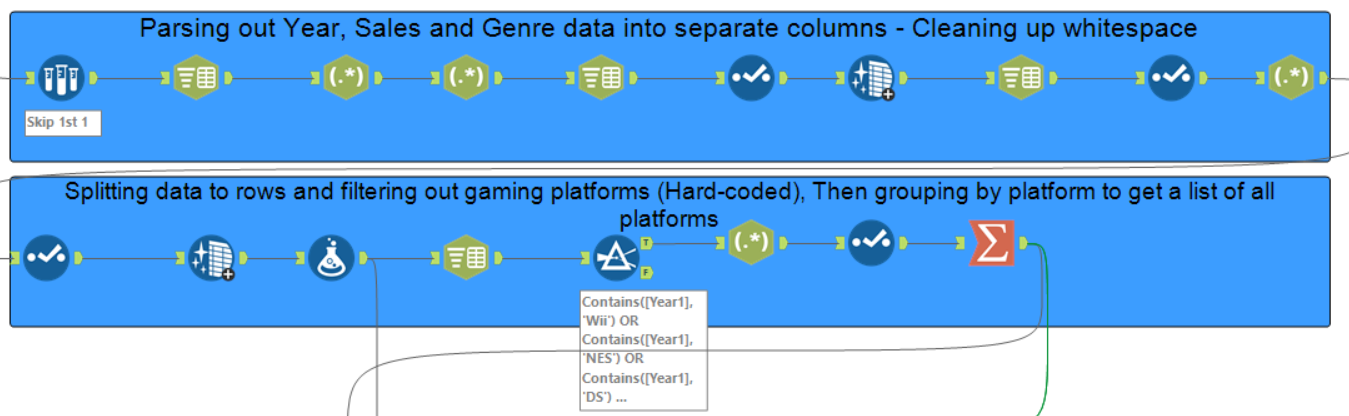
I then did some more prep to parse out the video game names which was quite challenging as most of the Wii game names also containing the console name (e.g. Wii sports). There is some fairly basic regex going on here to parse individual columns at a time and a formula to remove the last word of the Wii games to take the console out of the game name.
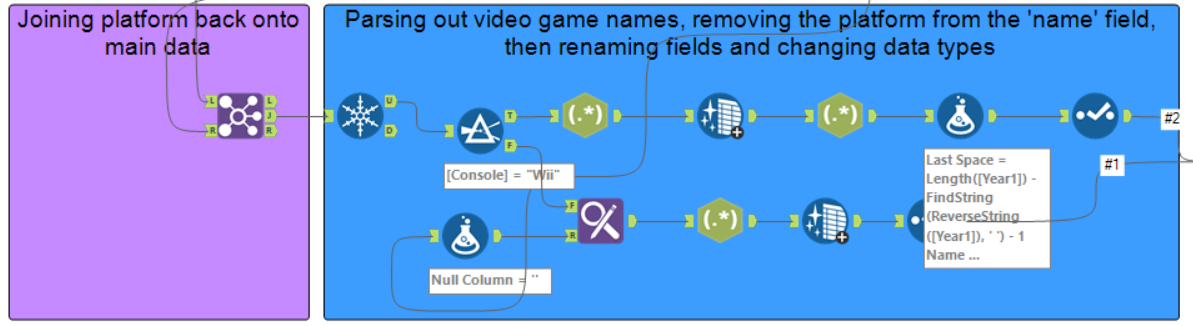
The rest of the workflow is just cleaning things up before getting to the answer (which I did at least manage to get!). However, hopefully you can see it's a pretty long and convoluted solution which is why I won't go into any more detail explaining it. The main point of this blog is to show how it can all be avoided.
Part 2 - RegEx to the Rescue:
I was well are that my solution was far from a clean way of tacjling the challenge so I had a look at what other people had done to solve it. Needless to say there were many better options but I saw some people has solved it almost entirely with regex.
I had another go to try and improve my regex ability as it's been a while since i'd had to use it in training.
A general tip that I would give to anyone trying to improve with regex is to use a regex tester (website which allows you to practice your expressions against test strings to see if they work properly before you try and implement it into you workflow). Regex101.com is the one I would recommend as it colour codes everything which makes it a lot easier to see what you are doing (example below).
It turns out that the entire challenge can pretty much be completed with only regex, without the need for any long winded transformations. It does take a bit of trial and error to find an expression which is where the tester helps enormously but it's still far quicker than trying to create the workflow that I skimmed over above.
To write your expression i'd recommend copy and pasting a few rows of data into your tester to see if your expression is working consistently and then iterate if needed.
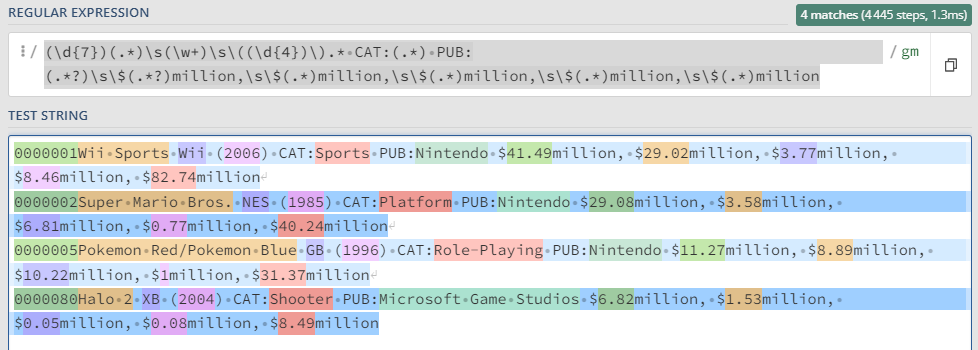
After quite a bit of trial an error I managed to get to an expression which worked for all of the data, see below for the final expression if you want to give it a try:
(\d{7})(.*)\s(\w+)\s\((\d{4})\).* CAT:(.*) PUB:(.*?)\s\$(.*?)million,\s\$(.*)million,\s\$(.*)million,\s\$(.*)million,\s\$(.*)million
This streamlined the workflow down to the point where I could complete the challenge with only a few tools

Hopefully this gives a good overview of the power of regex and how it can be used to parse complex strings of text - it comes in very useful when dealing with issues like parsing PDF's where often you will get all of the data in one long string and you may only want to pull out certain chunks of it!