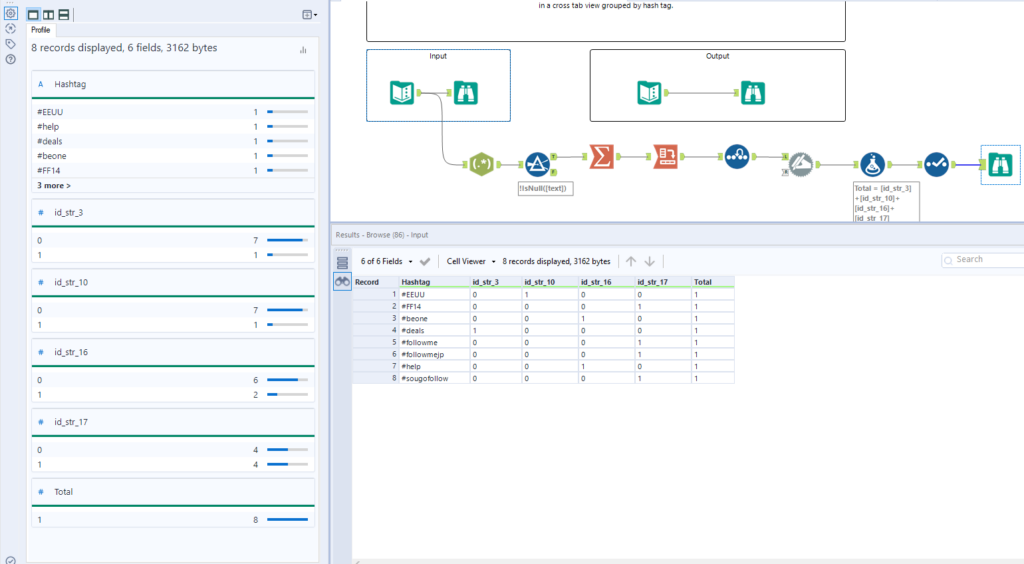
On Tuesday Louisa gave us an introduction on how to use Transpose and Crosstab tools, and when it is useful to do so. To demonstrate this, I have chosen to take on weekly challenge 56, which also involves a little Regex. In this challenge we are given some data with text from social media sources, and are tasked with determining what hashtags are used and by which users. The input and output we are given is shown below:
Use Regex to identify hashtags
The first thing I tried to do was identify and parse out the hashtags in the text column. I did this using the Tokenise output method in the Regex tool, splitting to rows. To identify the hashtags, I used the expression (#\w+), which tells Alteryx to parse out anything that starts with a hashtag, and is followed by 1 or more alphanumeric values.
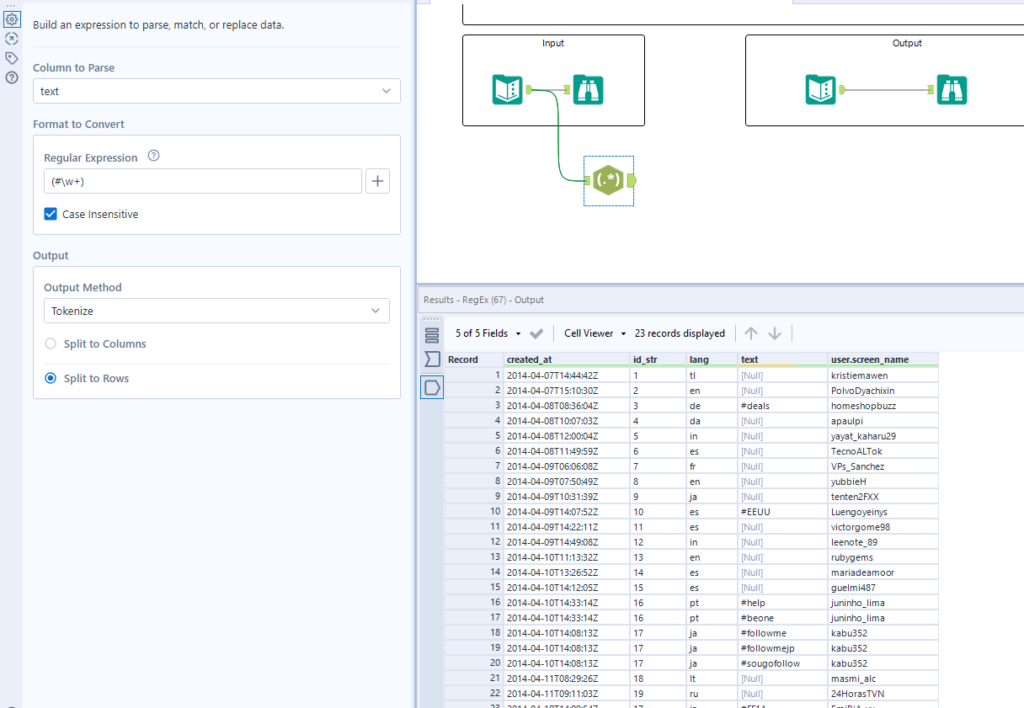
This leaves us with a nice output that replaces all text without a hashtag with a Null. We can simply use the filter tool to get rid of all the id’s without a hashtag.
Count and Crosstab
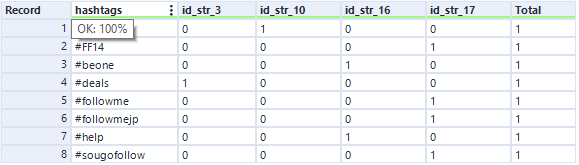
The desired output displays a count of which hashtag is in which id, which is easily obtained using the summarize tool. If we group by both Hashtag and id, and also count id, we are left with the following output:
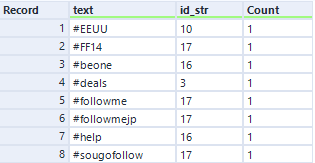
To get the id’s as column headers, we use the cross tab tool.
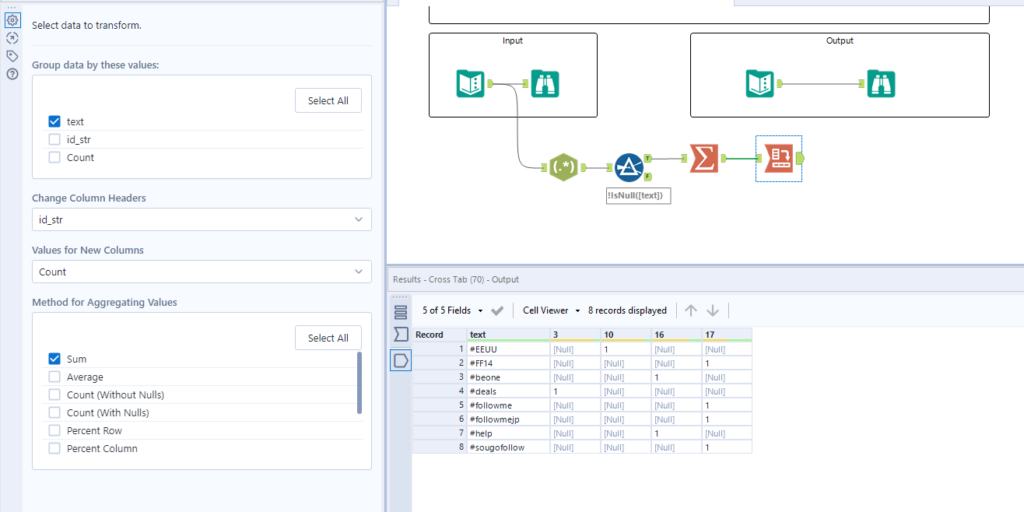
We group by the Hashtags (still labelled text) and change the column headers to the id’s, with the values being the count we calculated previously. We now have an output in the same form as the one we desire, all that’s left to do is tidy up.
I used the imputation tool to replace all the Null values with 0, and then used dynamic rename to add prefix’s to the field names. This could alternatively be done using an if statement in a multi-field formula tool. Finally, I used a formula tool to add up all the field values for each row to create a totals column. Voila!