


For this week's Friday Project DS23 were tasked with attempting 2021 weeks 1-4 of the Preppin Data Challenges.
This was just one day after our first SQL training and despite Coach Carl being impressed at our ability to pick it up, this project was no walk in the park.
Week 1 Challenge
This is the starting data for the 2021 week 1 Preppin Data challenge.

The challenge is as follows:
- Split "Store - Bike" into two columns
- Fix the spelling errors in the "Bike" field
- Create a Quarter and a Day of Month date field
- Remove the first 10 rows as they were just test values
First this had to be loaded into the Information Lab Snowflake Database of choice. This was done using Tableau Prep and was the only thing done using Tableau Prep, to my frustration.
This was the final SQL required for a good view.

Let's go through the challenge requirements in order.
Splitting the "Store - Bike"
My first thought was surely snowflake has a split function, right?
Yes! They do! Well then this should be easy, right?

I put in my SPLIT function and this is what I am met with. This is not in two columns like I wanted, this is the two values in double quotes separated by a comma wrapped in square brackets. RATS!
Okay well when looking up SPLIT I also found SPLIT_PART which returns the part of the split you specify. So I could do two split parts to get both parts as separate columns and then rename them with an AS "Bike" and AS "Store".


Ah there we go. That took far longer and required more help than I would have liked but nonetheless it's looking good.
Fix spelling errors in "Bike"
The three Bike Types were 'Gravel', 'Road' and 'Mountain'. These had all been misspelled in various ways. I knew to replace these misspelled values I would have to be able to recognise each misspelling appropriately.
Which means pattern matching which means REGEX, everyone's favourite.
So how about a REGEXP_REPLACE? Sure makes sense to me. Find from "Bike" this matching pattern and replace the value with the correct spelling.
But we had three values that needed finding and replacing but we did not want three columns outputted at the end. So this had to be done within one single long nested function.
Behold.
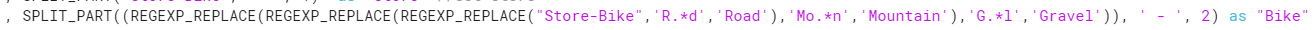
SPLIT_PART((REGEXP_REPLACE(REGEXP_REPLACE(REGEXP_REPLACE("Store-Bike",'R.*d','Road'),'Mo.*n','Mountain'),'G.*l','Gravel')), ' - ', 2) as "Bike"
This line does about 4 things at once. The REGEX_REPLACE actually happens before the SPLIT_PART. So it is searching through "Store-Bike" for the 3 different REGEX patterns and then splits the column to only have those Bike Types.
Making the Date Fields
Making the Date fields was quite straightforward if you're familiar with calculations in Tableau. With each date type as a function QUARTER("DATE") as "Quarter" and DAY("DATE") as "Day of Month" was all that was needed here.
Removing the first 10 rows
There was a few ways to do this, so be sure to check out other blogs from DS23 to see some more.
The way I went about it was to select only the top 990 of the 1000 rows and order it in reverse so that those first 10 would be omitted.
SELECT TOP 990
Up top with
ORDER BY "Order ID" DESC
at the bottom to make sure it's the first 10 not the last 10 that is omitted.
Final View

This was my final view.

This was the SQL.