The challenge assigned today was to investigate copyright complaints from Google’s Transparency Report.
It did take a few attempts, but eventually the data was downloaded as a team effort (Thank you Collin).
DS17 did however end up taking over the WiFi at the office temporarily.
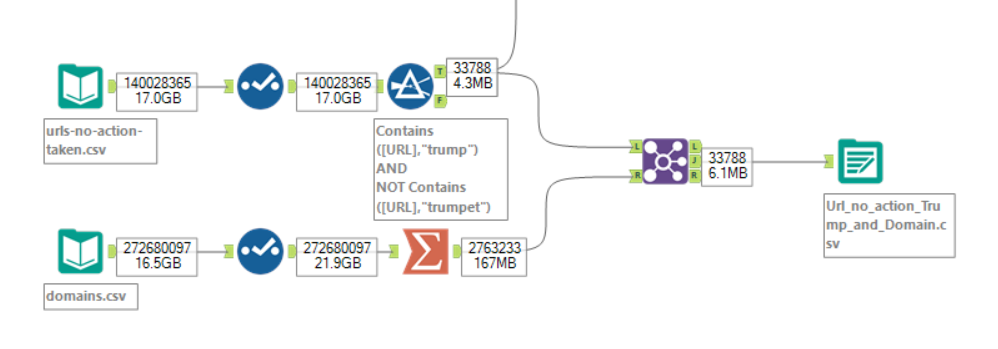
The file was almost 4GB (zipped) and once the CSVs were opened in Alteryx it became very clear that it was a hefty amount of data with almost no hierarchy or category allocation.
So, my method of approaching the data today was to find a topic rather than summarizing the overall statistics of the data.
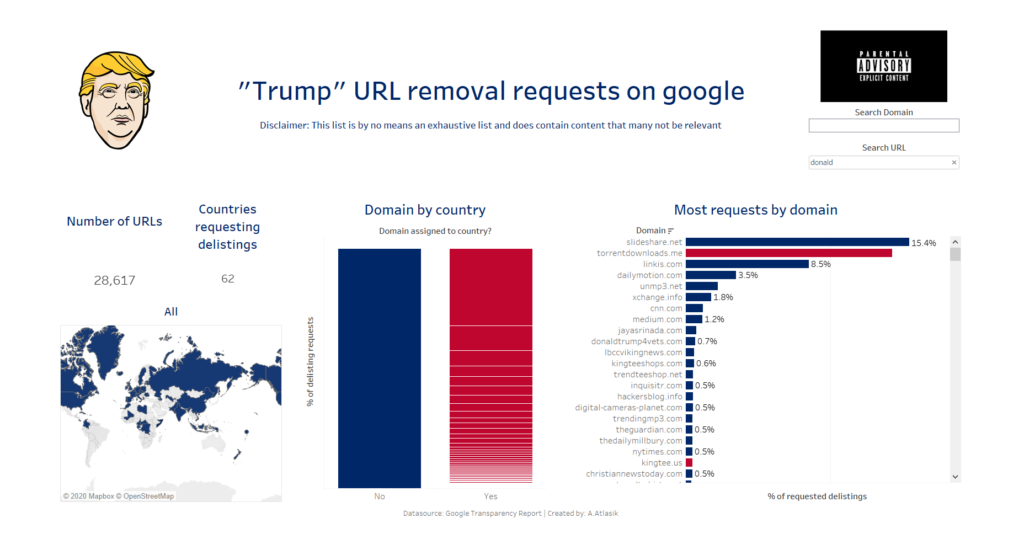
After a few searches related to ‘Tableau’ and other reputable organisations, the keyword of “Trump” returned approximately 33 000 records of data.
Topic decided, the data was prepped in Alteryx.
One of the aims was to extract the more readable “topics” with regex from the URLs, but time was limited so the 80/20 principle was applied with several filters.
With a little bit more time, far more accurate results can be narrowed down to using the regex and URLs.
Adding to this, a dataset of domain names was joined to the data to show a view of which countries (if matched) these requests are being made from.
Given the nature of the data, it was pretty difficult to make inferences on the data so the dashboard today is more of an explorative one.