In Data world, Slowly Changing Dimensions (SCDs) refer to columns of data which don’t change as often as one could expect.
Think about your classic generic example of customer data:
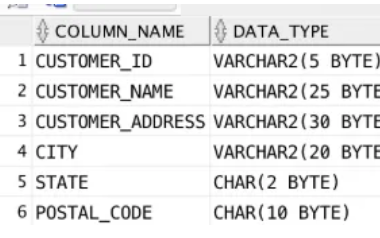
Normally, you’d expect to see one customer ID for each person, their address, city, state and postal code. You don’t expect those details to include many changes (excluding when business starts getting new customers, of course).
But what is one of your customer moves? or changes names? How does that affect your customer lookup table?
Well, you could probably say that the best way to go around it is simply update the table with the new name/address, right? That probably works for a lot of scenarios - but what if there’s value in keeping the historical data as well? Maybe you’ll need to keep track of past addresses in case someone will be interested in looking at the spatial analysis of old orders?
This is where the concept of SCDs comes in! Each dimension with attribute values that can change gradually over time require some kind of a specific approach to track (or not) those changes, all that while maintaining data integrity and query performance.
Each situation is different and depending on the business context, the way you approach SCDs might change. The following are the 5 main strategies normally used to deal with this type of data:
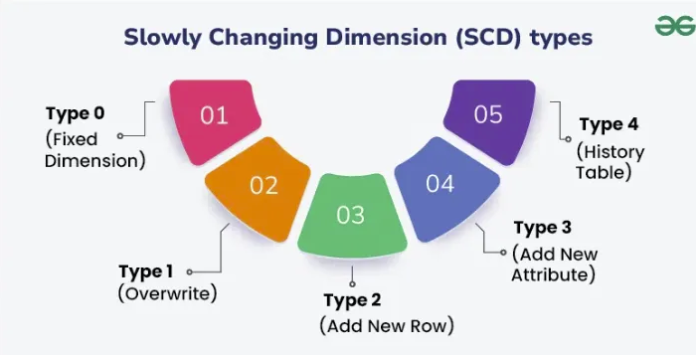
source: https://www.geeksforgeeks.org/software-testing/slowly-changing-dimensions/
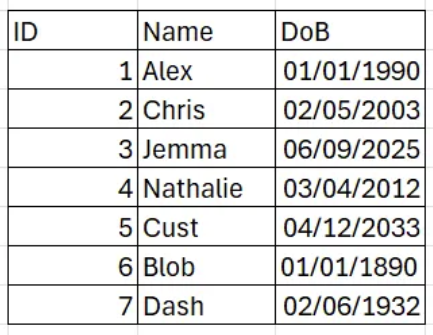
- Fixed Dimension Those refer to cases where the SCDs never change (contrary to their name). This means that they should always stay the same and any change happening to those might be a sign of a data issue. Example: Date of Birth
- Overwrite Simplest solution - the customer changed their last name and you don’t care what their old name is. You simply overwrite it in the orders table and move on! This approach only works if you definitely don’t need to store any historical information.
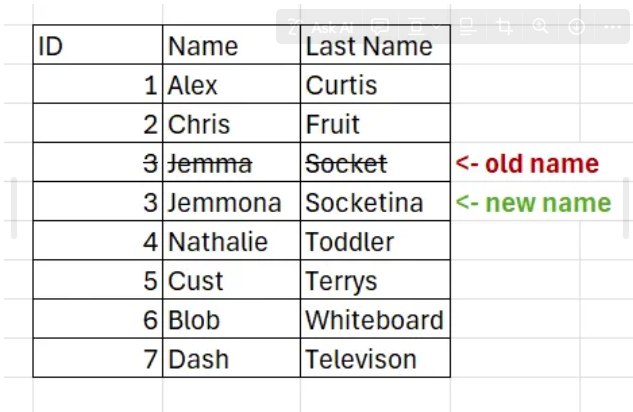
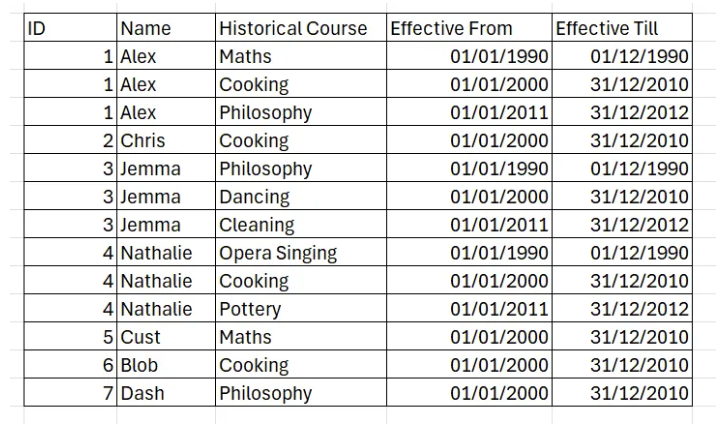
- Add new Row (Same table historical tracking) Each time a change happens, you can simply add a new row of data (changing the granularity of the table from one row - one ID to multiple rows per ID). This normally also requires some kind of an indicator of date range where each row is/was active or at least if it is currently active. Example: An employee table with their work titles. Whenever someone gets promoted, a new row is added with an ‘Effective From’ column informing when the change happened. The old row stays as well.
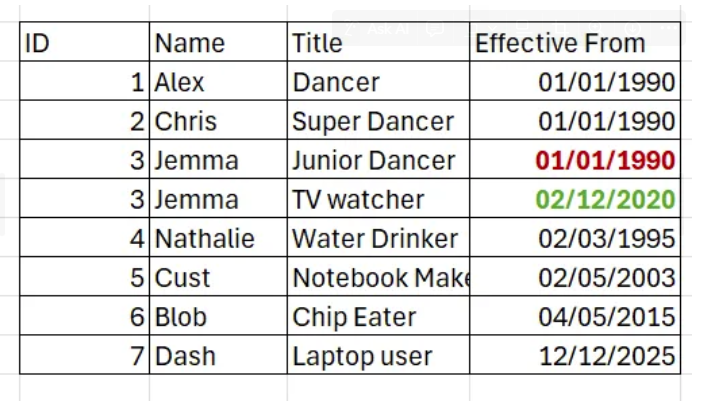
- Add New Attribute (Limited History in the same table) This approach allows you to store limited amount of historical information. It relies on adding an extra column which informs of the ‘previous’ status (with or without timestamps). Example: A student detail table with details on the courses they’re currently signed up to. An extra column informing of the courses they did in the previous term.
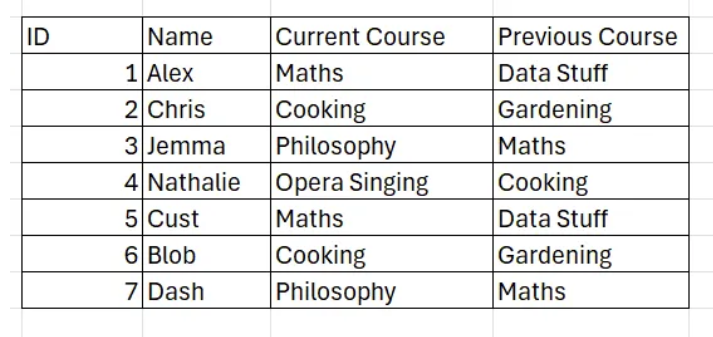
- Separate History Table This is probably one of the most robust ways of tracking changes, especially useful if you need all the details on the data changes. It entails creating a separate table which contains exclusively the historical versions of the data, with explicit timestamps as to when each row was active. At the same time, your lookup table maintains each initial granularity (e.g. one row per ID), ensuring no duplication occurs during data manipulations. Example: ****Currency exchange rate changes - One table with the rates currently ‘active’ and one with historical ones!