So, day 4 of #DashboardWeek consisted of Andy wanting to punish us more by getting us to pull nutritional data from the USDA’s website regarding a specific food product – I was landed with ‘Waffles’, a not so traditional dish in England but interesting nonetheless.
The kick-off.
The first issue came regarding this data set came from the pagination of the search results – 50 results per page for 15 pages. As the API was only accessible after a lengthy sign-up and confirmation period, I had only 2 options left to me:
- Either manually trawl through each page and copy + paste into Excel for cleansing, or;
- Use an app to pull all the relevant links and then batch macro these URLs followed by parsing the relevant HTML from the resulting query in Alteryx.
I opted for the latter option; as I felt it was more robust and less time-consuming.
I used a Google extension called ‘Link Klipper’ to pick the relevant page links through each of the 15 search page results – I then imported these links via a text file into Alteryx for parsing.
Parsing the data.
HTML parsing is something that I am still getting to grips with, as Regex is something that is not necessarily intuitive, but can be learned. Regex, for those not aware, stands for Regular Expressions – and is a way of telling Alteryx to return only phrases/words/characters that meet certain stipulations. It is a very handy way, as in this case, of cutting through reams of HTML to get to the necessary data you require.
The parse was a bit tricky – as we had a lot of foreign characters appearing in strange places in the HTML that were being pulled from the website, but I persevered through many iterations until I nailed it.
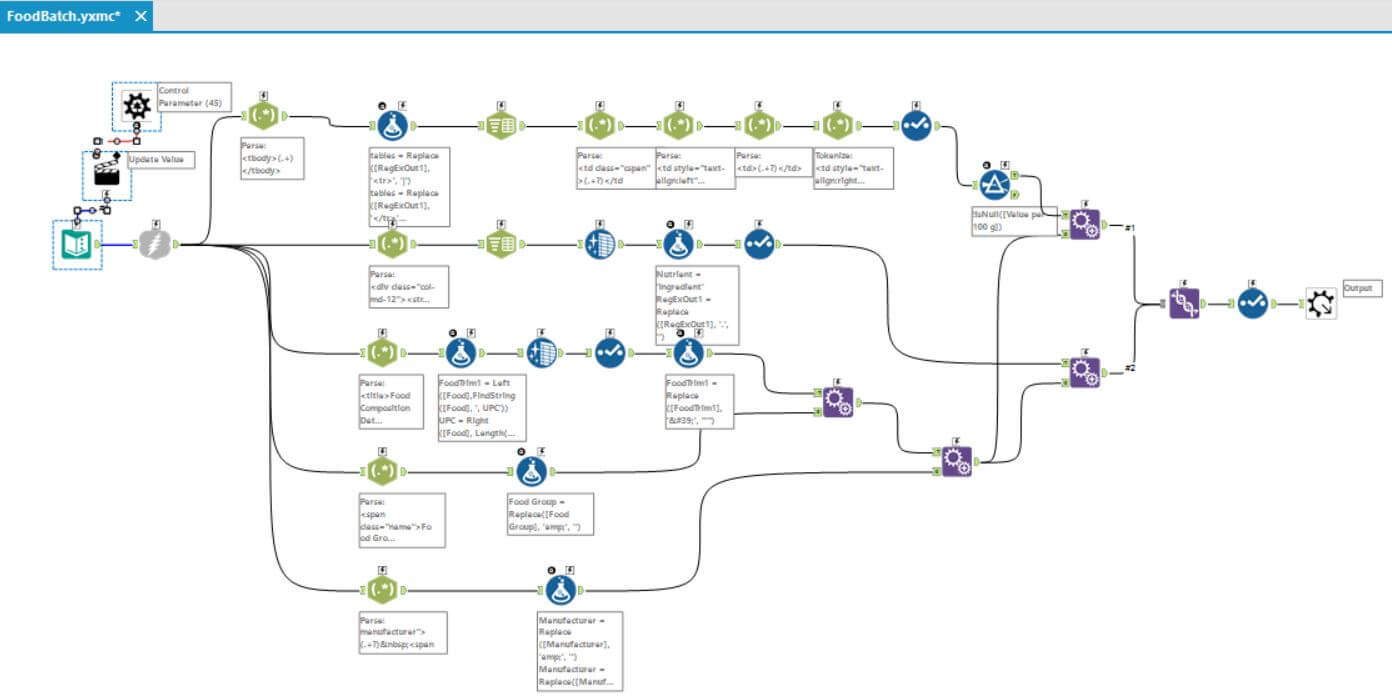
In fact, I had to run the parse several times to pull different sections of the HTML – such as the product name, manufacturer, nutritional information, and product ingredients. You can see from my workflow below – that I managed this and then had to append the data back together and do a final union with the ingredients to include them in my result as an extra item:
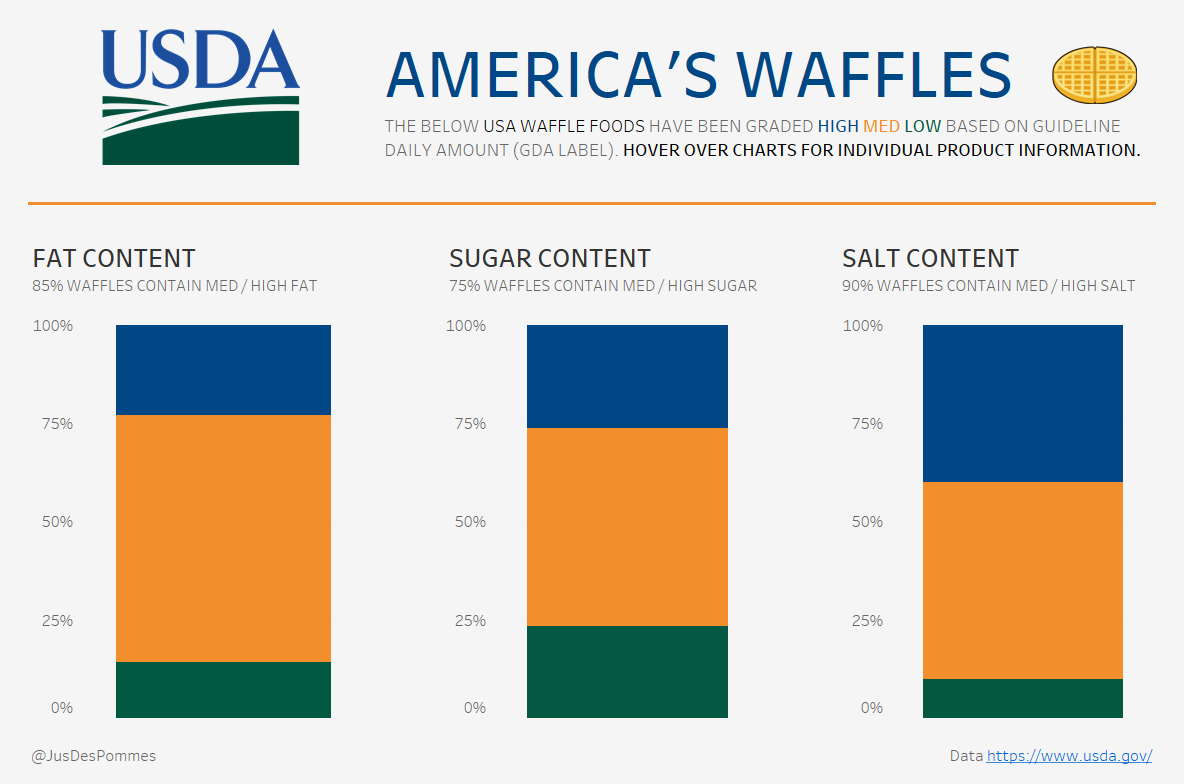
With the data in a suitable format, I set about thinking about a final viz. My usual workflow is to think about this before preparing the data – however, in this instance, I hadn’t done this. It was nice though to have had my vacation time apart from the data to mull over ideas. As the data was not the most exciting, I settled upon a simple plan of 3 stacked bars that highlighted the General Daily Allowances (GDAs) limits of each of the waffle products – i.e. fats, sugars, and salts per 100g in terms of being high, medium, or low. Here were my original ideas:
Developing the viz.
The viz made use of the USDA colour scheme and provided the macro picture using descriptive headers and a percent of total across each 3 of the measures – whilst also showing micro information across the measures if a user hovered over a specific product. An interesting insight that was borne out of looking at the products this way was that if a waffle product was deemed high in either fats, sugars, or salts – it would often be much lower in the other areas. I wondered whether this was due to taste – for example, if something had a lot of sugar in it then it would not require so much salt for flavour.
Anyway, here is the resulting viz – smart, simple, and straightforward – but there’s some insight there: