



This week, we focused on Alteryx. Each day we were introduced to a new tool and learned about its features as well as use cases. I’ll be honest in saying that I still find Alteryx very overwhelming and so this blog post will help me re-affirm my learning and hopefully help others who are new and confused to not give up.
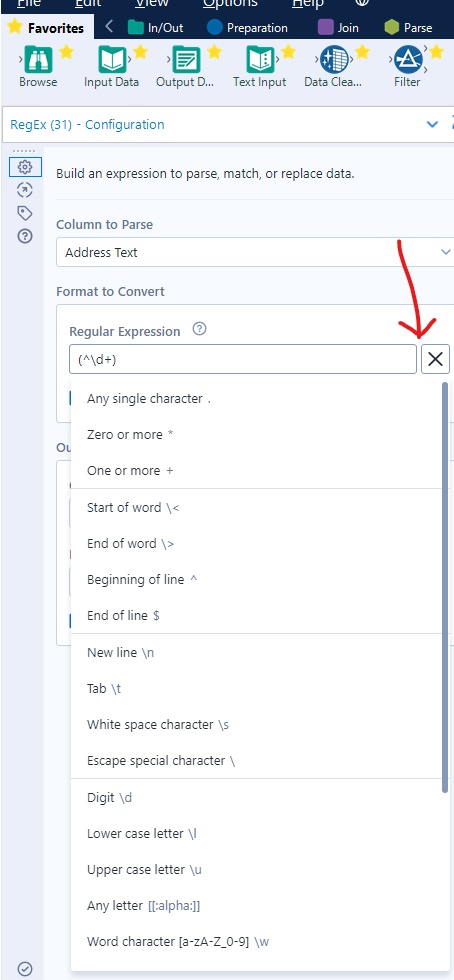
Regex is essentially pattern spotting. It looks intimidating at first but really it is identifying this pattern and using the Regex expression or ‘language’ to take what you want, whether that is to replace, tokenize, parse or match. I’ve used most of these in a weekly challenge below to make more sense of it. But first, what do these mean:
Replace – You’re replacing something, with something new whilst telling regex how and where. This allows you to parse, replace and re-arrange.
Tokenize – This is like a text to columns tool. It takes a chunk of text and splits it into columns or rows. You get to choose what’s split out and what’s ignored.
Parse – Unlike the others, this needs to be in brackets. This allows you to extract a set of information from a block of text. It comes with a mini select tool included allowing you to rename, change size or type.
Match –This results in a true or false value. I’ve not used this in my example below however, you could ask regex to match all instances where a certain value exists, and it will output this in a new column with true or false.
As for the expressions or ‘language’, I still find this very confusing and it was a lot of trial and error before I got to the outcome. What does help is this + drop down that allows you to see what things mean
Alteryx Weekly Challenge – 54
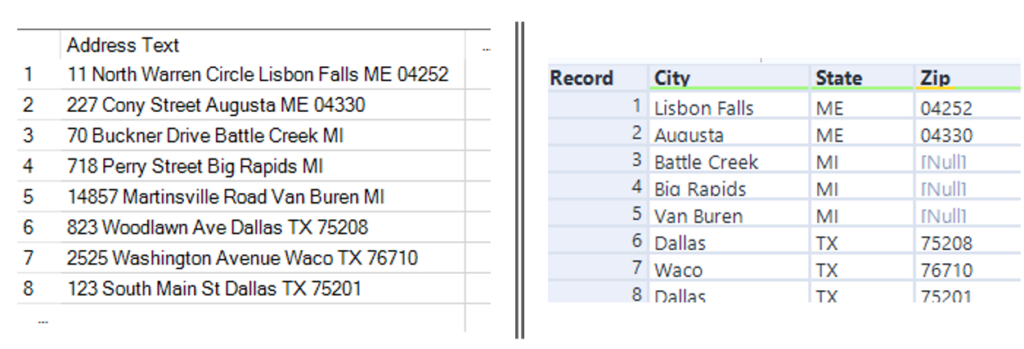
On the left is the data we were given. On the right is what the output should look like. Just to note, there are various ways of getting to this outcome and my solution got me there after much trial and error.
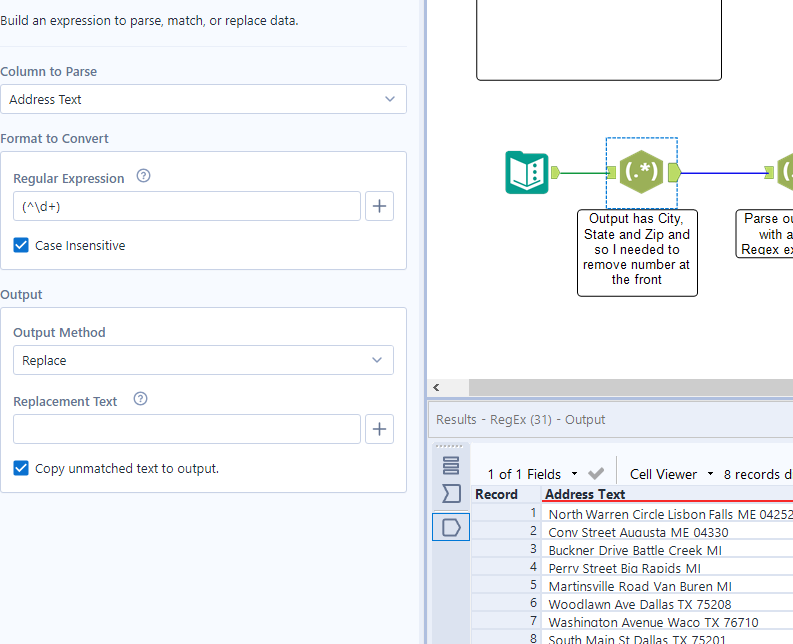
This is my completed workflow which I will run through

Step 1: Removing the number at the front with the output method of replace.
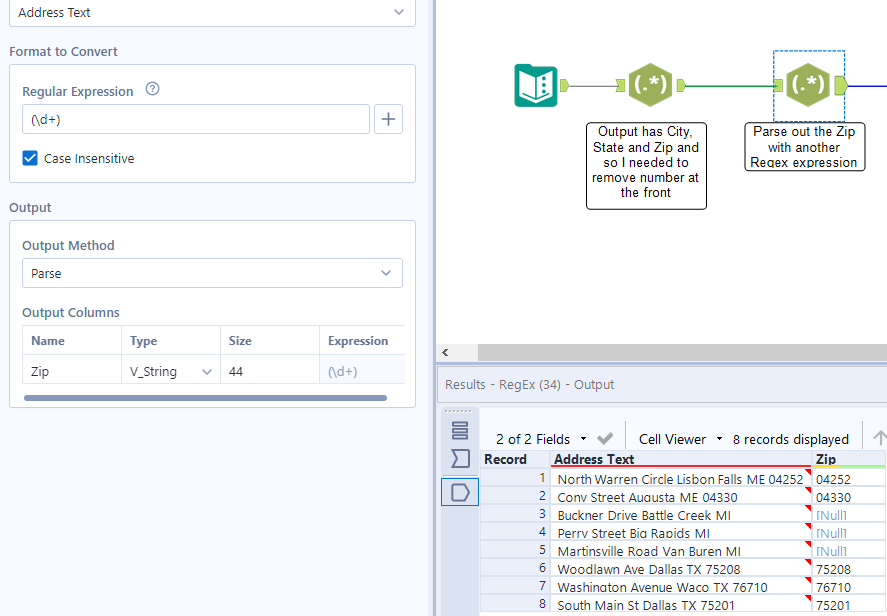
2. Parsing out the ZIP.
3. Tidying up as we go along. Although the output still has nulls, I replaced them with 0.
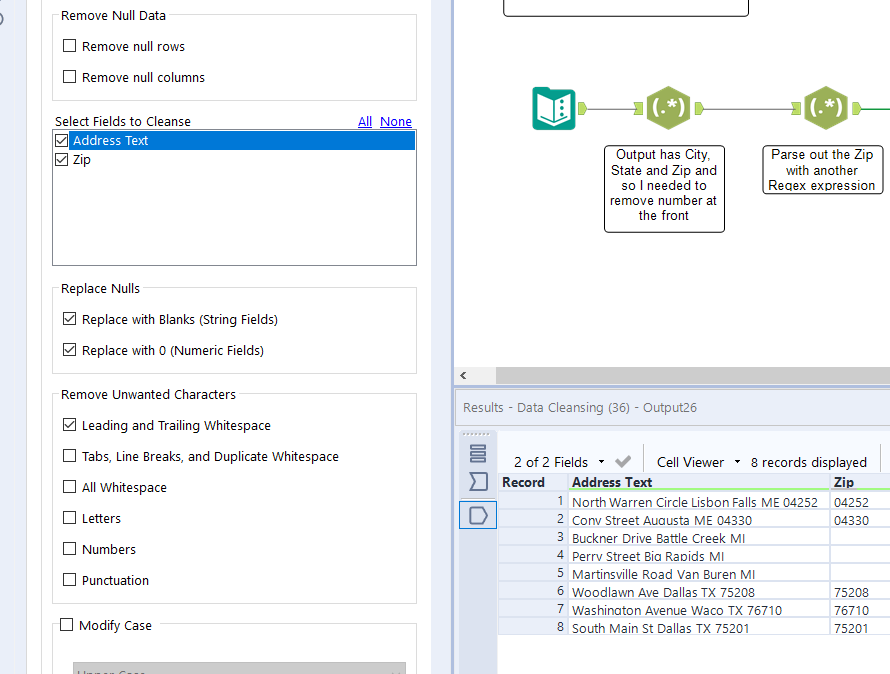
4. Parsing out the State. Make sure you deselect case insensitive as we are after uppercase letters.

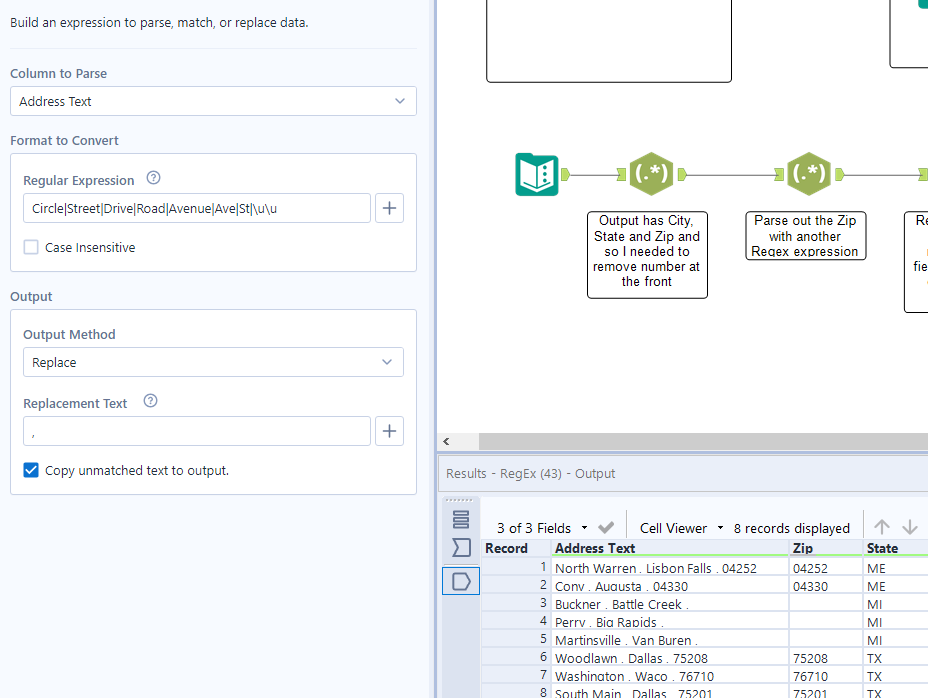
5. Separating the address with commas to make it easy to tokenize after. I spent far too long on this before having to read more into it and then finding a way. The replace output method is very underrated. My regular expression has many ‘pipes’ (‘|’) which represents or. Again, there must be an easier way to get there but my thought process led me here. Make sure you deselect case insensitive.
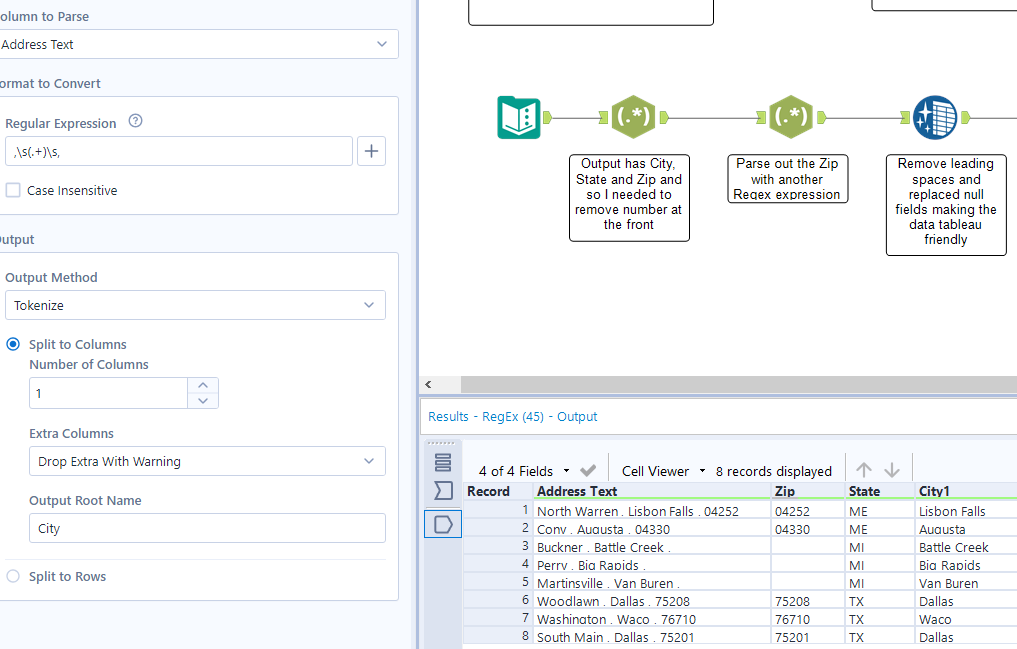
6. Tokenize! The description above makes more sense, I picked what to keep and what to ignore. My Regex expression identifies my keep. Make sure you deselect case insensitive.
7. Finally, a quick rename and reorder to tidy things up!
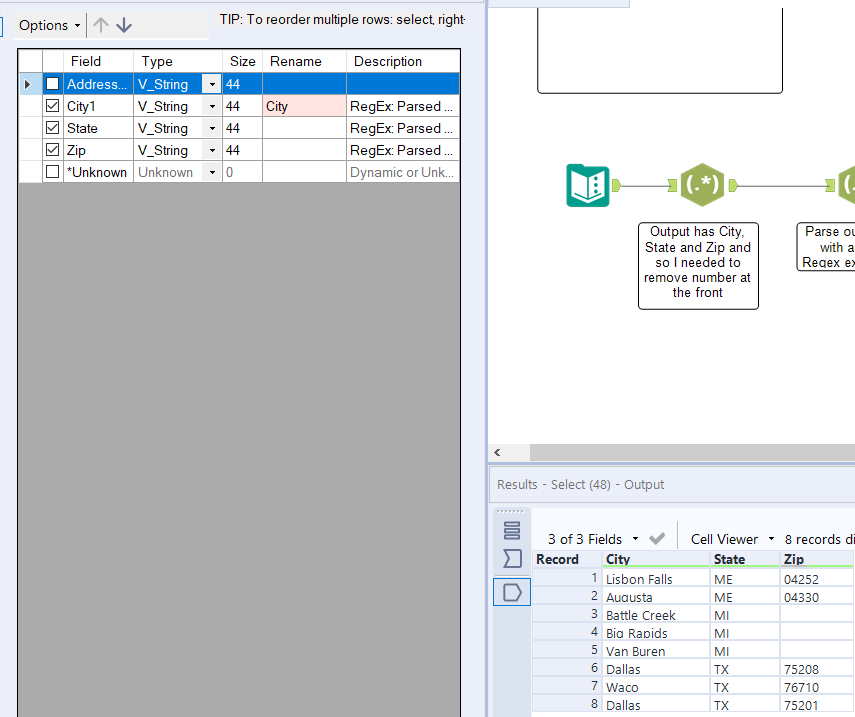
This did take me much longer than I’d like to admit but I got there in the end, even if my method was much longer than that of others or the solution itself. I enjoyed trying expressions even when they were wrong as eventually when it all came together I had the AHA moment and realisation why I went wrong.
If you want to give this a try on your own, you can via this link: