


Data Visualisation for Noobs (like me)
Alteryx – Joining Three Files to Make a MegaFile
Last week we had a client project in which we had to make one list of companies, with the attached data, a MegaFile if you will, out of three separate lists of companies, with their attached data. There were several parts to this task, only one of which was the joining of the files, which was my task. There was also the pre-cleansing and the post fuzzy matching. I found that the way I described my joining method was unclear, so thought I’d write a blog post with a graphical walk through, to try to clear up the concept. This is of course a simplified version of the below workflow (which doesn’t even have the fuzzy matching on it yet):

This is the section that I will be focusing on: 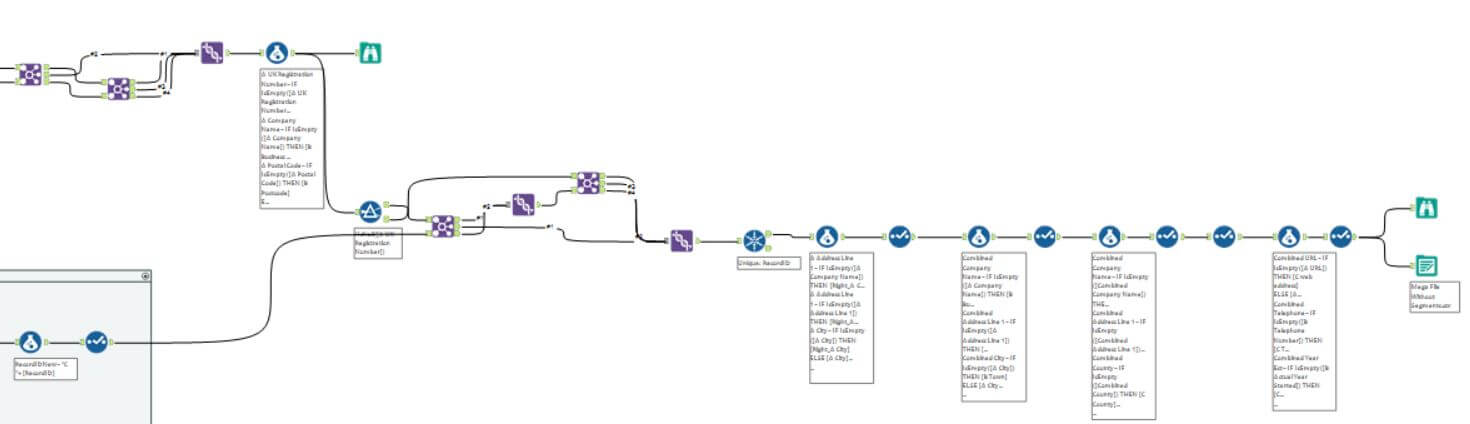
This is the simplified methodology behind joining all three files:
Part 1:
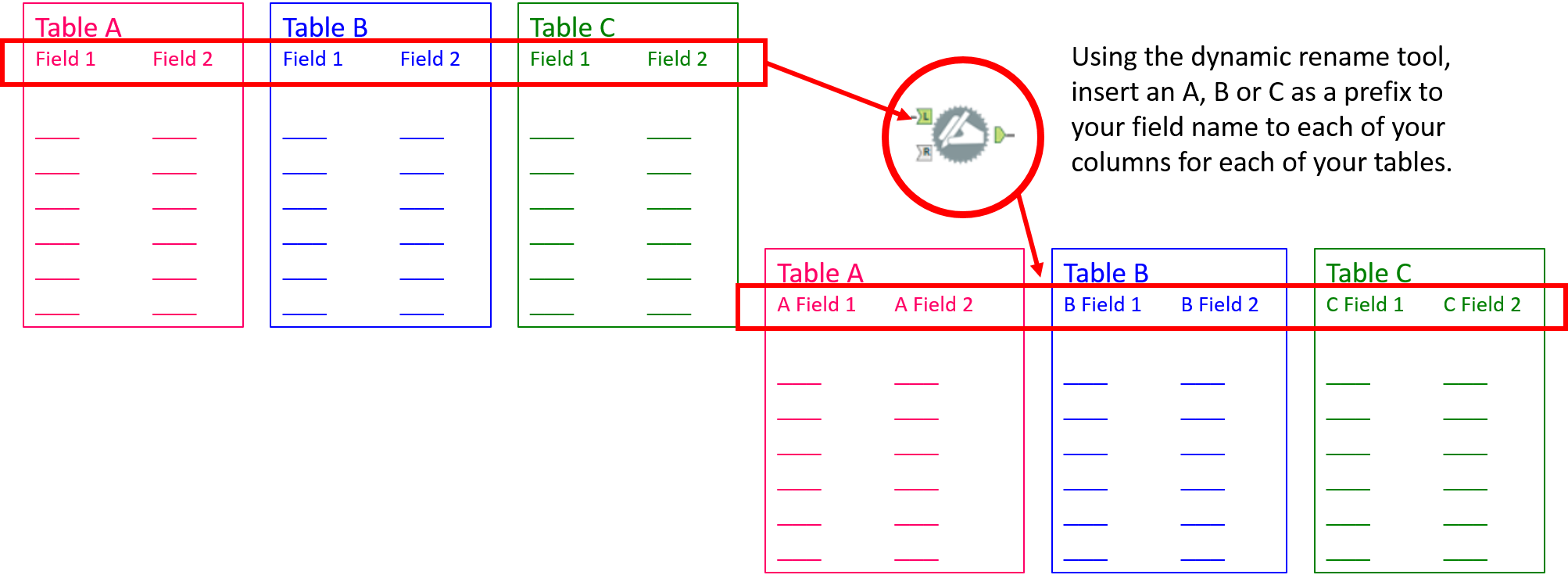
Part 2:
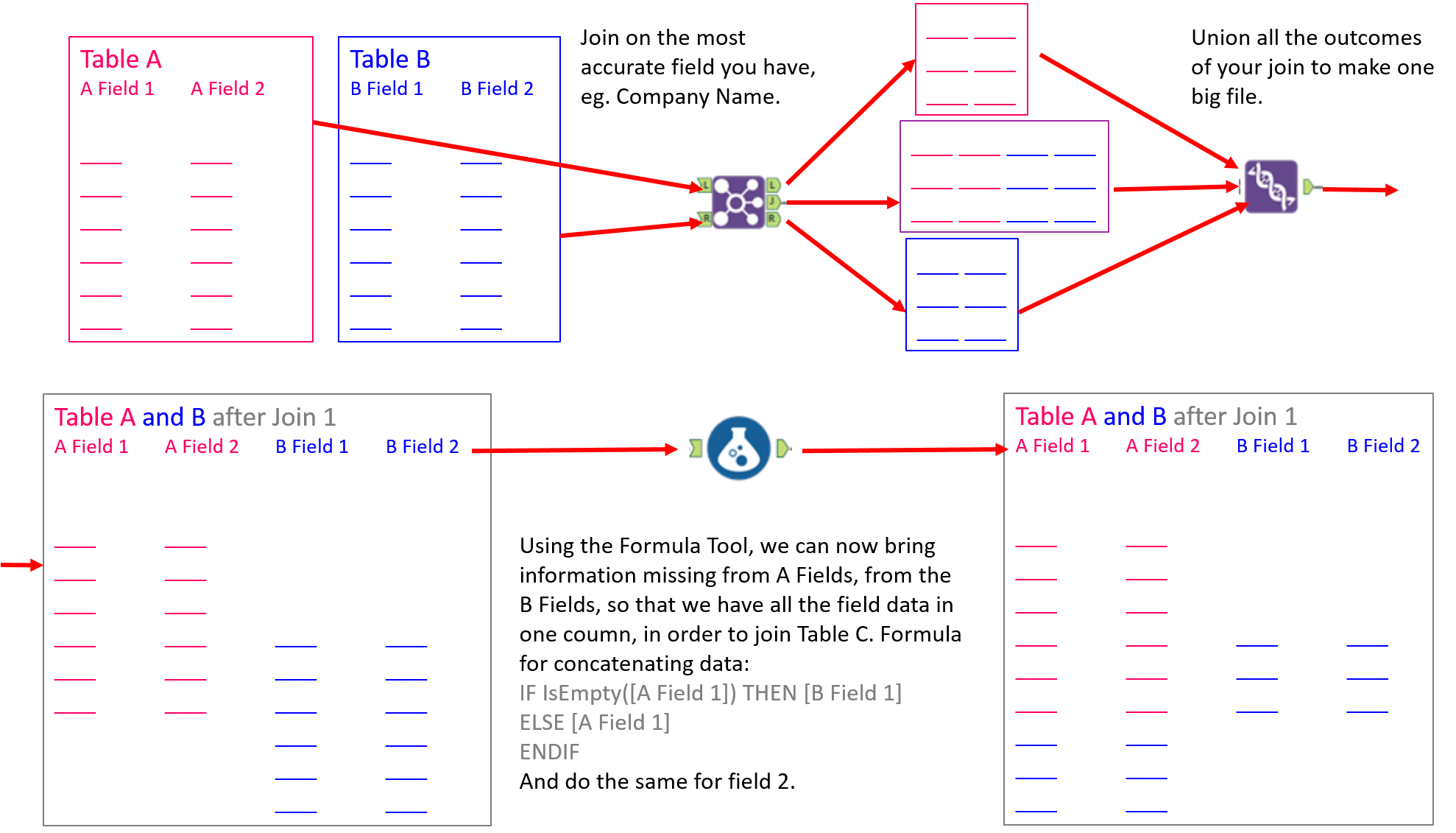
Part 3:
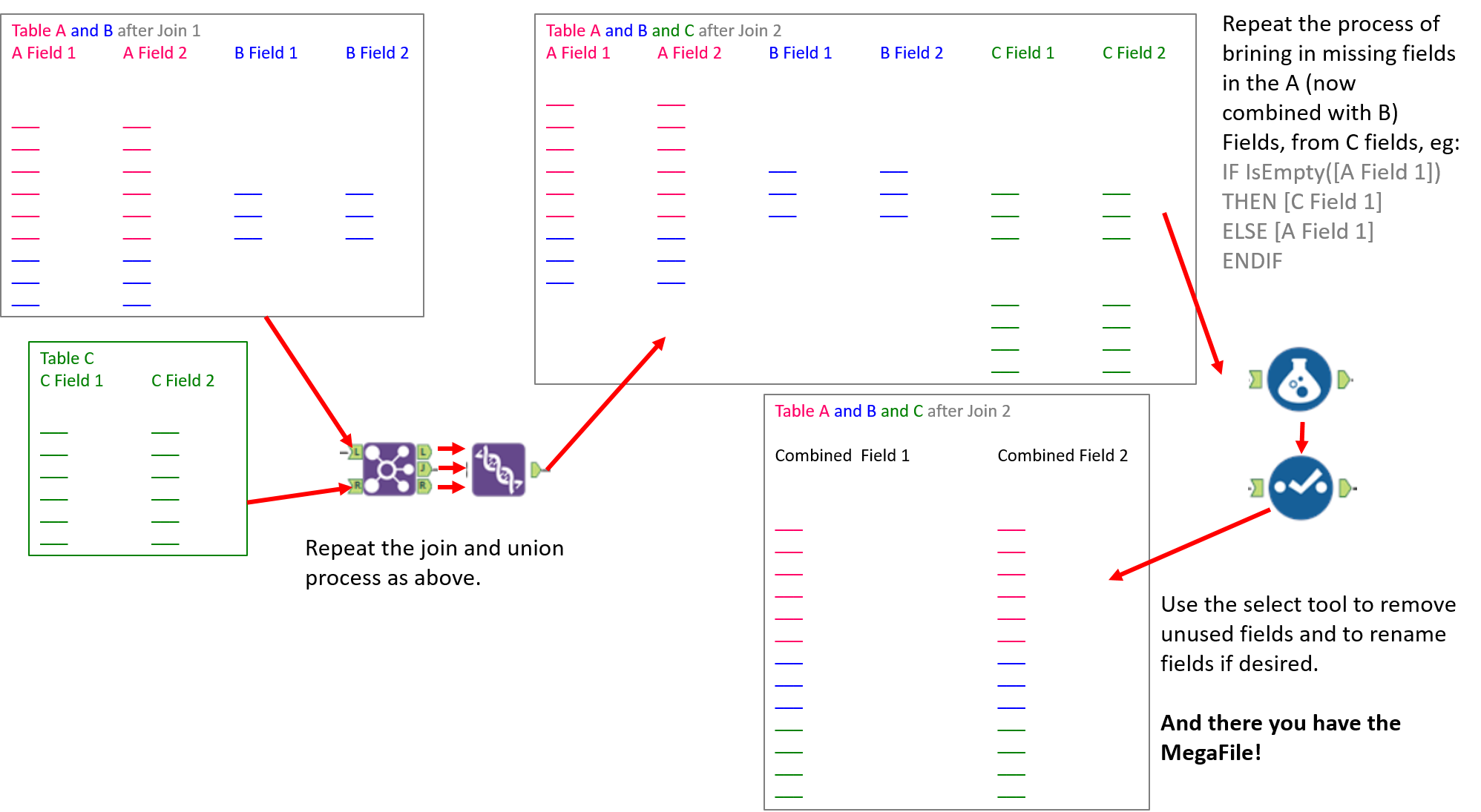
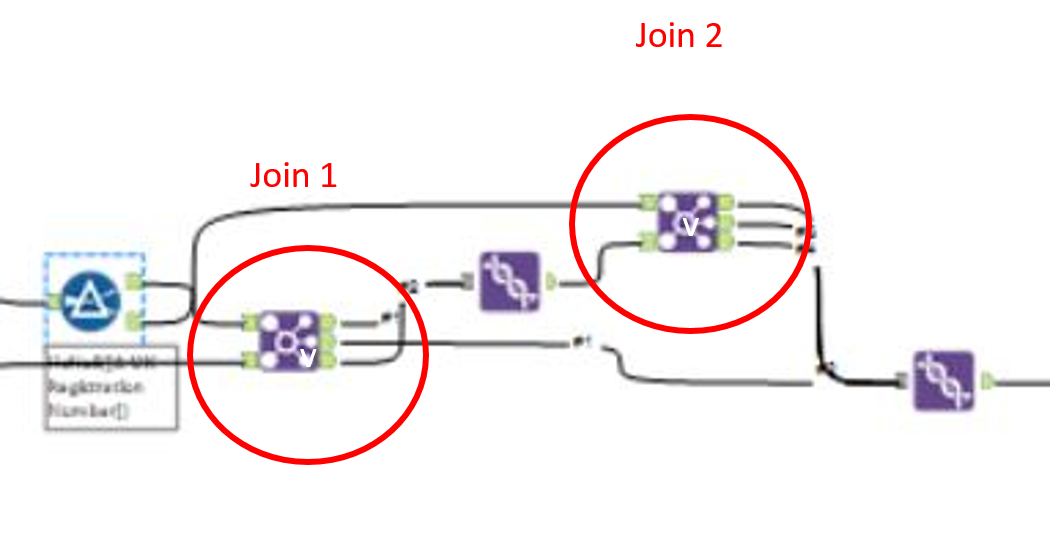
What makes the working example slightly more complicated, is that the most precise field to join on, in our case, the company registration number, is not given for all companies within the data sets. So we have to carry out two joins. A join on the company registration number and then a join on the remaining left and right files, to join on company name and post code, to try to join anything that the first join missed. We can then union both the outputs from the joins and the remaining left and right outputs, to get the completed ‘Table A and Table B after Join 1’.

In the second join, after concatenating the results of the first join, you also have to filter out the nulls in company number, before carrying out the join on company registration number, otherwise you get a huge amount of duplicates, as all the nulls from the Table A and B Combined file, will be joined with all of the nulls in Table C. Because you can only put two inputs into a join, the second join in this case, you have to union the left and right outcomes from this first join and use this as one input for the second join.
I hope this helped!