


A simple example
I've always loved finding patterns and solving puzzles, so Regular Expressions are fun for me! But they're not fun for everyone and are more of an advanced problem solving tool, so it is important to avoid them when you can, so that whoever you are handing your work off to can follow and easily troubleshoot if you are gone.
So in this post, I'm going to explore two ways of solving the same very simple exercise - with RegEx and Text to Columns - in Alteryx.
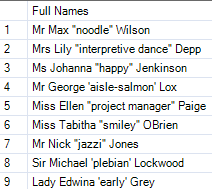
We have a simple table with people's full names, including their nicknames, in either single or double quotation marks. We would like to create three columns for 'Title', 'First Name' and 'Surname.'
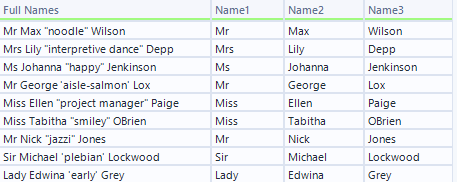
RegEx Solution:
In Regex, we would use the 'Tokenize' output method, because we want to split into columns. We know we only want 3 columns, so we will specify that in our settings.
(Note: Split to Rows is more common in RegEx, because in real life scenarios you may not know how many columns you will get, but in this situation we know exactly what we want and have a predictable outcome)
Our column to parse is 'Full Names.'
Our Regular Expression:
In this data, all Titles, First Names and Surnames begin with a capital letter, while all nicknames begin with a lowercase and are enclosed in either single or double quotes.
So, I've used \u\w*
In other words: begin with an uppercase letter, and take any alphanumerical or _ values that exist.
This takes any word beginning with an uppercase value and any following letters, numbers or underscores following, until it reaches a non-alphanumerical or underscore value: in this case a space. This will go into the first newly generated column. It will do this again with the next uppercase letter in the cell. This will happen 3 times as specified in settings.
I've unchecked 'Case Insensitive' to ensure that the tool is using \u as intended.
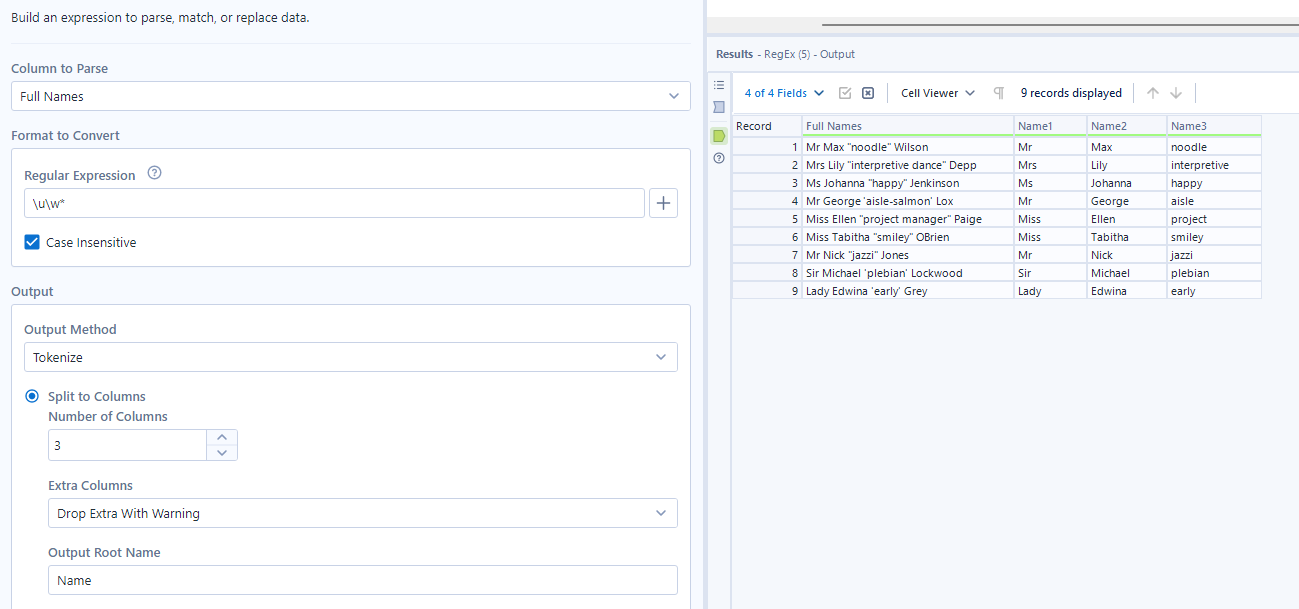
Otherwise, RegEx will essentially ignore my \u, as seen above.
Text to Columns Solution:
Here, the spaces are still significant, and we call them out directly as our delimiters.
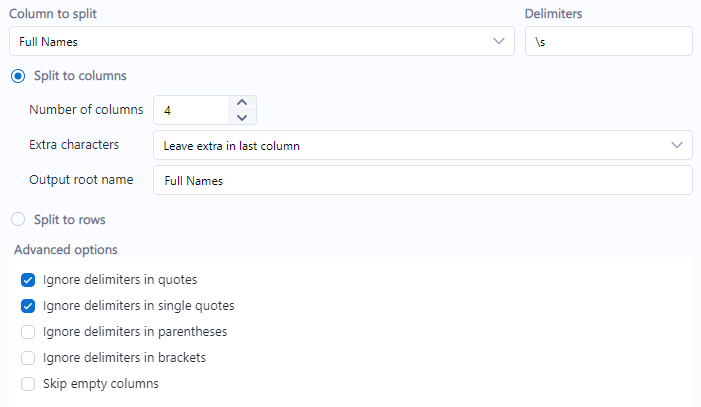
I've specified the number of columns as 4 instead of 3, because we will need an extra step here. I've also specified advanced options of ignoring delimiters in both single and standard quotes, since the nicknames are included in both.
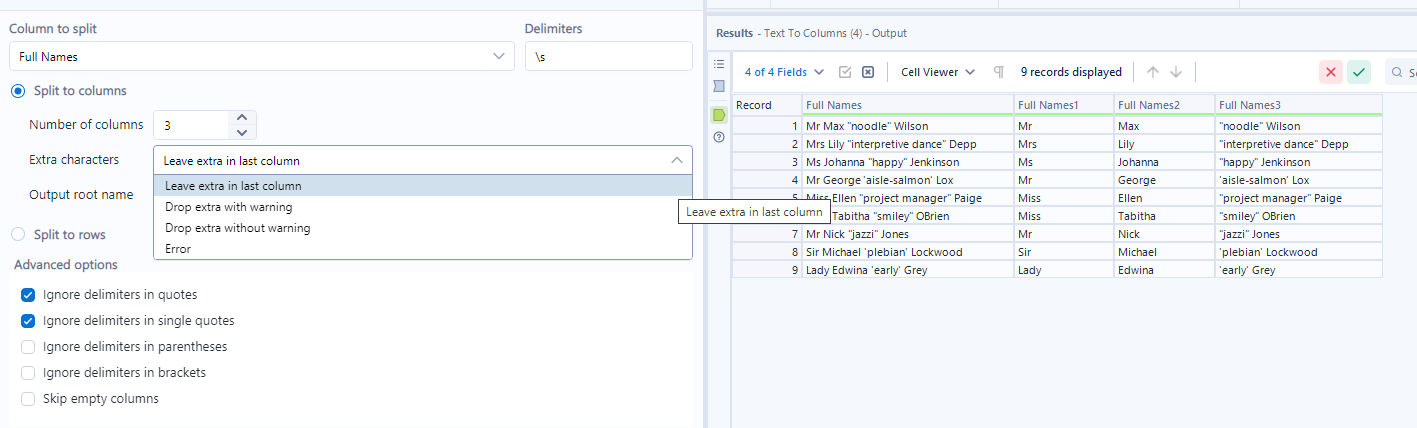
Text to columns will add the information that I initially specified should be ignored to that last column. Not what we want! So it's important to plan and think about your predicted outcome.
Now we can use a Select tool to drop the nickname, if we would like.