Web scraping is a powerful technique that enables you to programmatically extract relevant data from websites, making it easier to perform analysis for a wide range of purposes. For instance, you can gather competitor information to support pricing strategies, collect product reviews for sentiment analysis, or extract product details for market research.
However, it's important to ensure that web scraping is permitted before proceeding. This can typically be done by reviewing the website’s Terms and Conditions, performing a quick legal check via Google, and consulting with colleagues or legal teams if unsure.
To get started with web scraping in Alteryx, use a Text Input tool and provide the URL of the site you want to scrape, for example:
https://books.toscrape.com/index.html
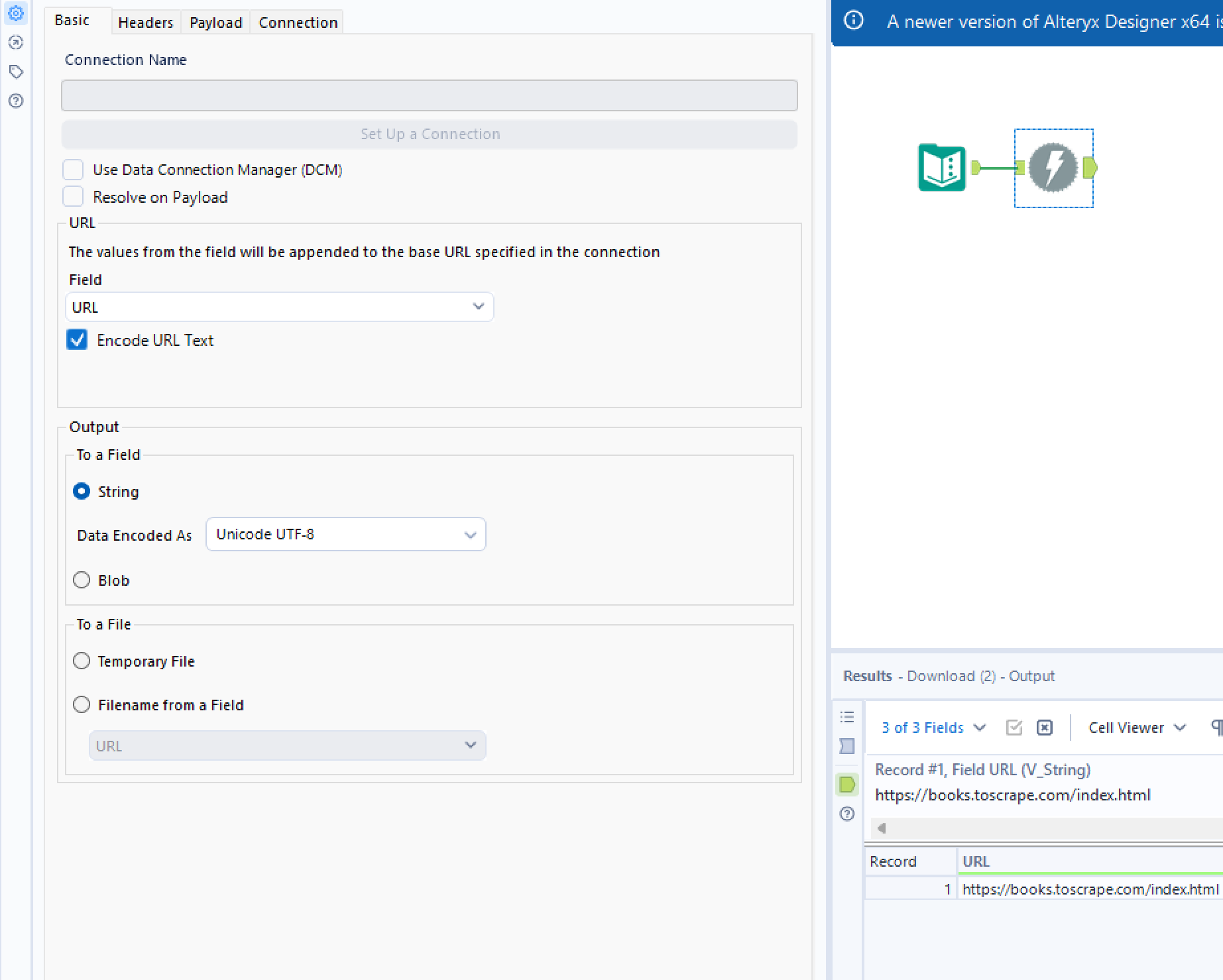
A download tool is needed to extract the information from the URL and is configured as so:
If we add a browse tool and double click on the 'Download Data' field we can see that we have successfully downloaded the HTML for the website.
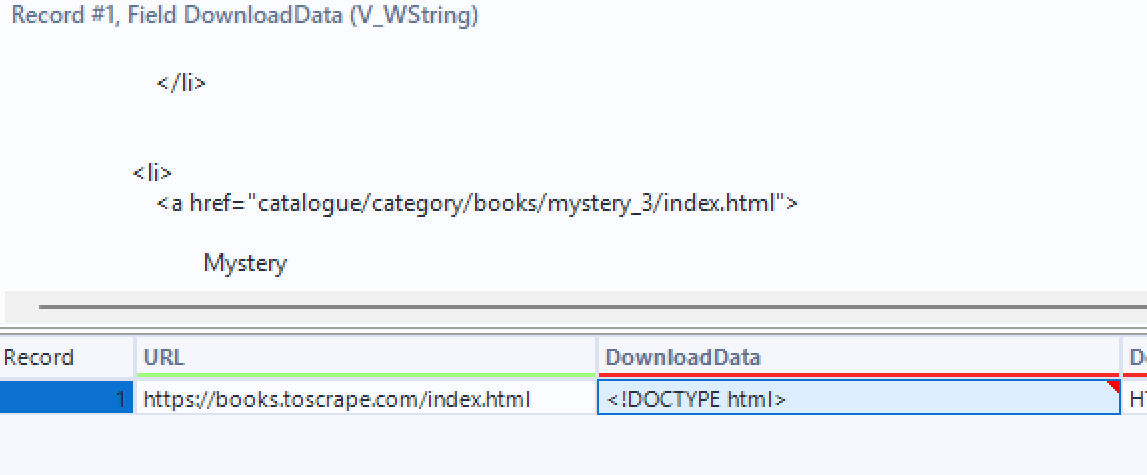
If we want to find specific information from the website we need to inspect the HTML from the website to find what it looks like:
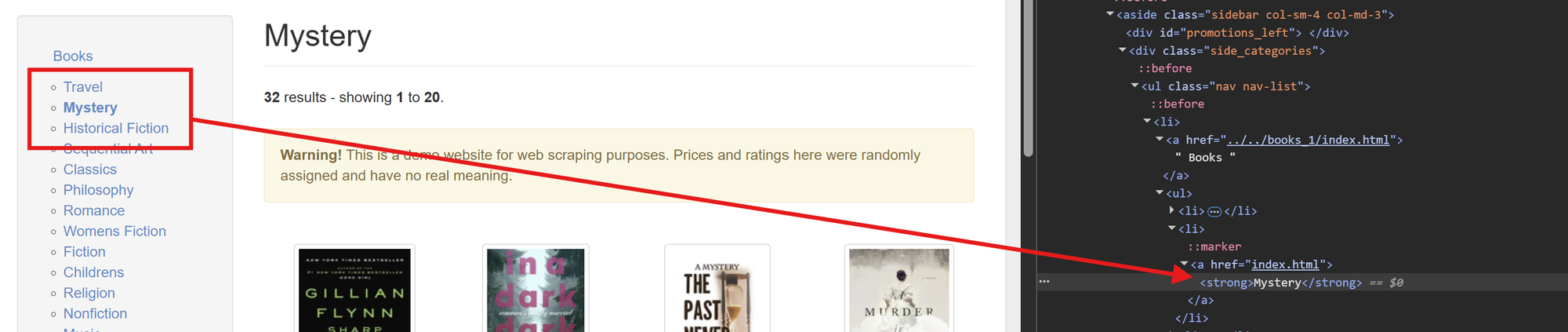
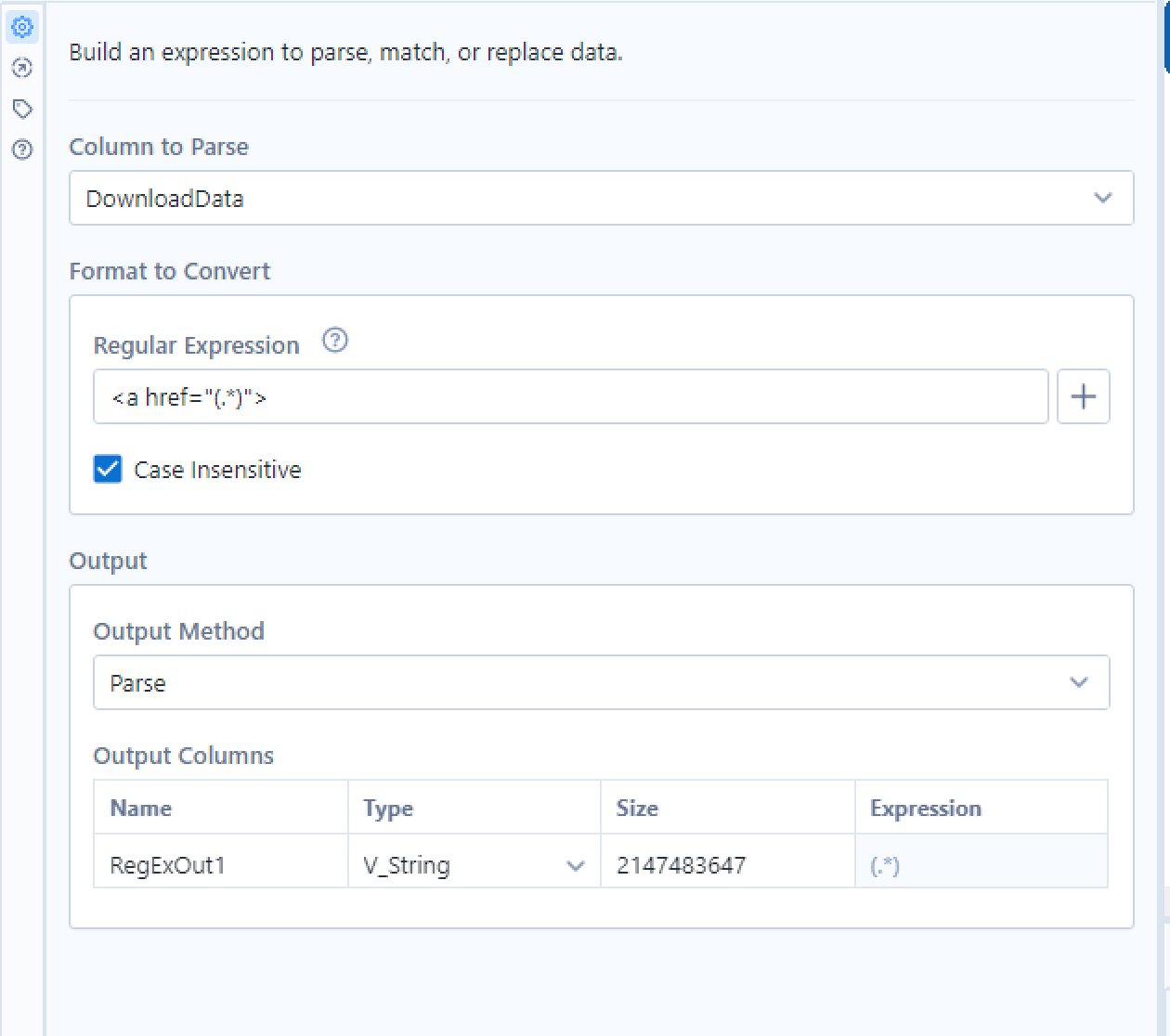
For example if we want to extract all of the book categories from the website we can use the reference <a href that sits before each book category in the HTML.
Using the Data Cleansing tool to remove all leading and trailing spaces, and the Filter tool to remove empty records will leave us with a new line of HTML in each row. We can now search for <a href and gather the lines of HTML we need. The lines we are looking for end in html"> so we can add this to our filter tool:
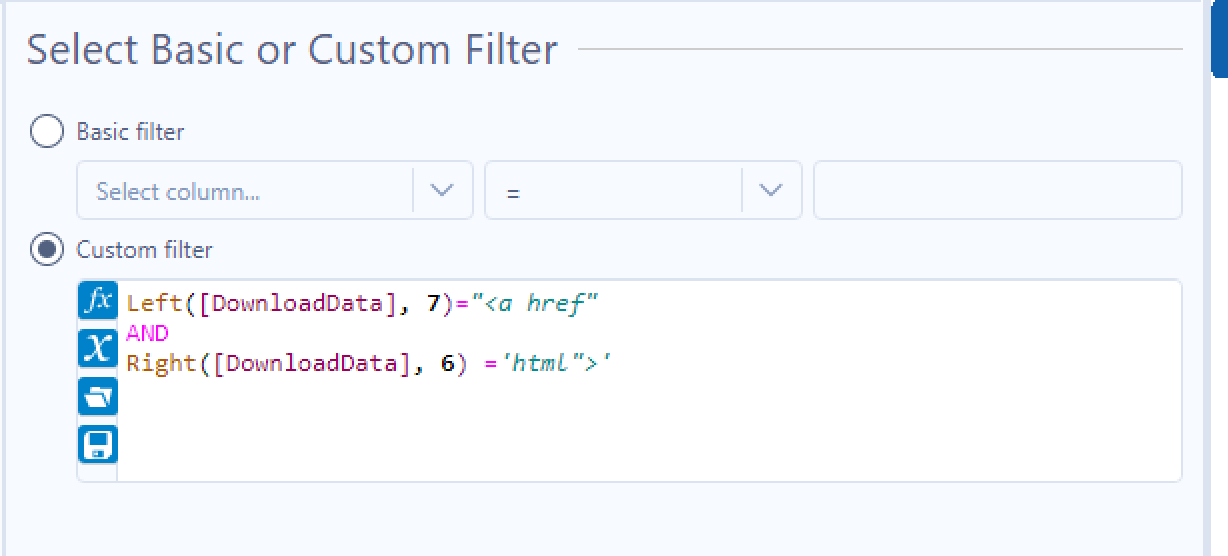
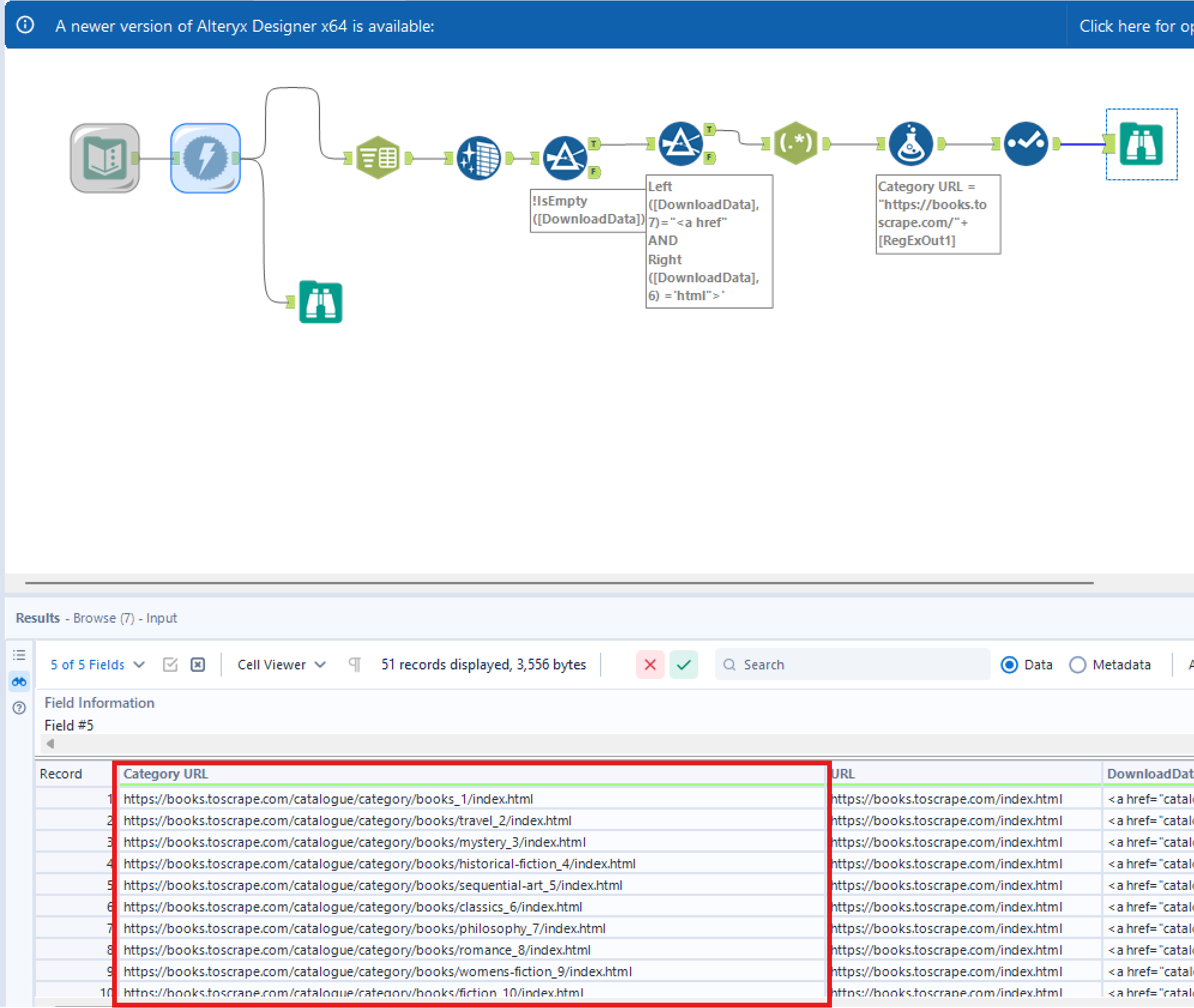
Leaving us with the records of the 51 book categories. But what if we want the URLs of the book categories so we can download further information on the books within these categories? We need to use RegEx to parse everything inbetween <a href and html"> before adding a Formula tool to add https://books.toscrape.com/ before each category URL to get the completed URL of each book category.