Web scraping is the use of automated to tools to extract web data from publicly available websites. Theres will be times where you might want to use data contained in a table on a website but you probably don't like the idea of having to manually input the data into a spreadsheet, this is when web scraping comes in handy.
When Should You Web Scrape?
Here's the golden rule of web scraping: if you can avoid it, do. Web pages can change without notice, and a single update to the site's structure can completely break your workflow. Websites redesign their layouts, change their CSS classes, modify their HTML structure, and these changes can render your carefully crafted scraping logic useless overnight.
So before you start web scraping, always look for alternate data sources first, particularly APIs. APIs are designed for data access, they're structured, documented, and much more stable than scraping HTML. But if an API isn't available or doesn't provide the data you need, then web scraping becomes your next best option.
Finding Hidden APIs
Before we dive into actual web scraping, here's a pro tip that can save you hours of work: sometimes you don't need to scrape at all.
Navigate to the webpage you're interested in, right-click anywhere on the page, and select "Inspect" from the menu. This opens your browser's Developer Tools. Because the entire modern web is built on APIs working behind the scenes, you can sometimes find the actual API call that's being used to populate the data on the page.
Look in the Network tab of the Developer Tools and filter by "Fetch/XHR" requests. Reload the page and watch what API endpoints get called. If you're lucky, you'll find a clean JSON API endpoint that you can hit directly, bypassing the need to scrape HTML entirely. If you find one, refer back to my previous blog on APIs in Alteryx!

Understanding Web Scraping Fundamentals
If no API exists, then we move to web scraping. But what exactly are we doing when we scrape?
Web scraping is essentially pattern recognition. You need to look at the HTML code and identify patterns that consistently mark the data you're trying to extract. HTML has a hierarchical structure with tags, classes, and IDs that organize content. Your job is to find the patterns that reliably point to your target data.
For this tutorial, I'll be using books.toscrape.com, a website specifically designed for practicing web scraping. It's perfect for learning because it won't change unexpectedly and it has clean, well-structured HTML.
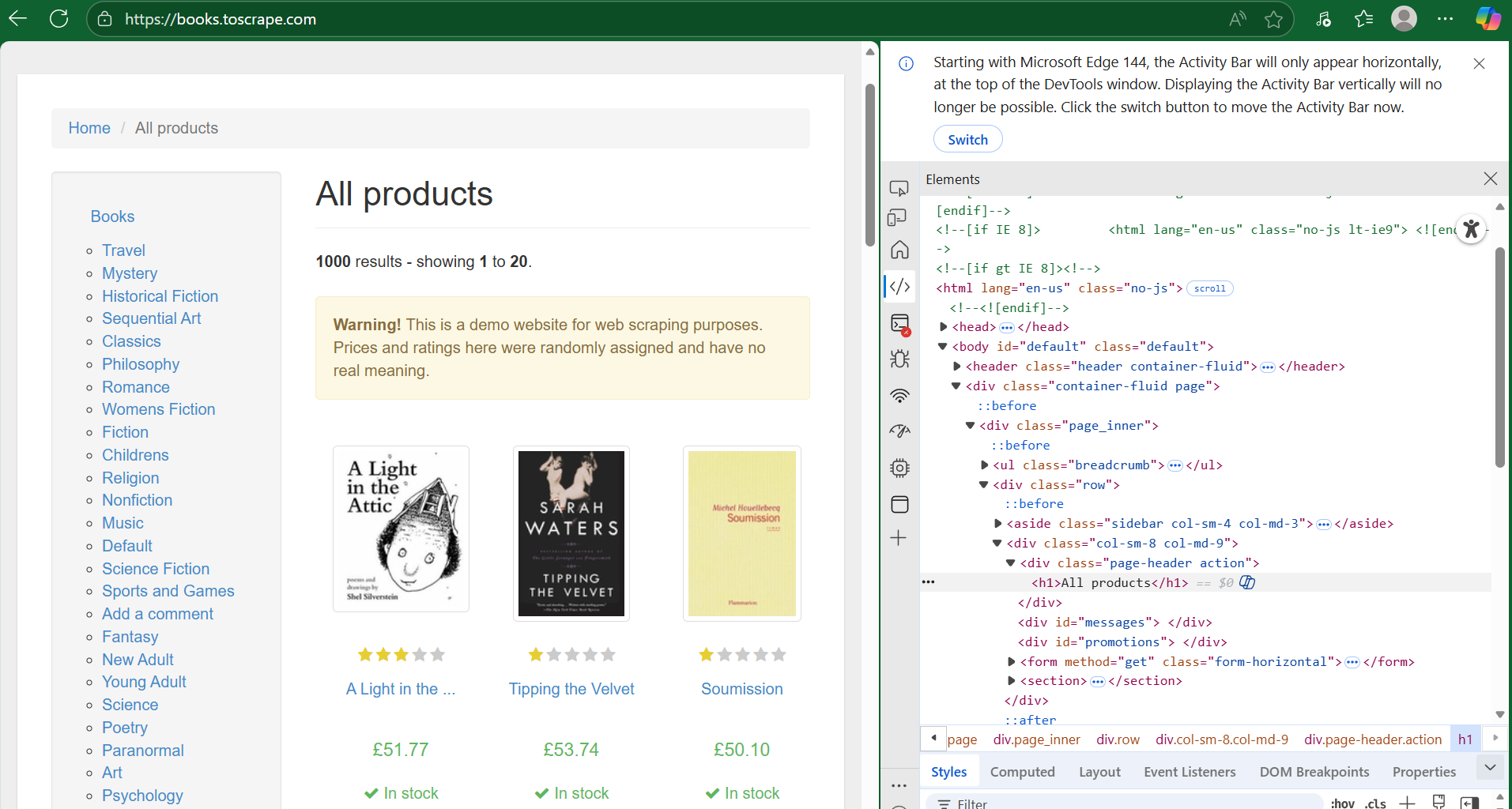
Step 1: Inspecting the Page Structure
Before opening Alteryx, spend time exploring the website:
- Navigate to the page in your browser
- Right-click and select "Inspect" to open Developer Tools
- Click on the Elements tab to view the HTML structure
- Hover over different elements in the HTML, your browser will highlight the corresponding elements on the page
- Look for patterns in how the data is structured
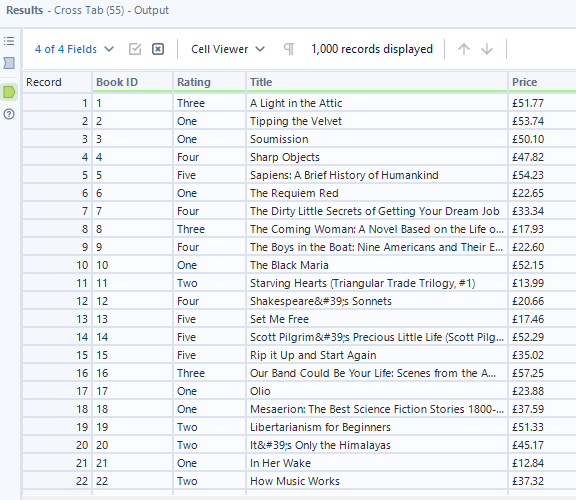
For books.toscrape.com, you'll notice that each book's information (title, price, rating) is contained within specific HTML tags and classes that repeat for every book on the page.
Step 2: Setting Up Your Initial Download
Now let's move to Alteryx and download the page content:
- Text Input Tool: Create a field called URL with your target page:
https://books.toscrape.com/catalogue/page-1.html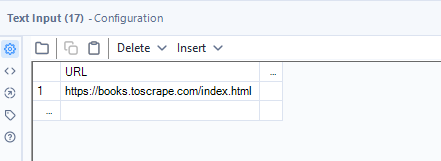
- Download Tool: Connect this to download the contents of the URL. The Download tool will fetch the HTML source code of the webpage. For basic scraping, you typically won't need to modify the Headers, Payload, or Connection tabs, the default settings work fine.
- Run and cache the workflow up to the Download tool. You don't want to keep hitting the website repeatedly while you're developing your workflow, right click on the download tool and cache the results and work from there.
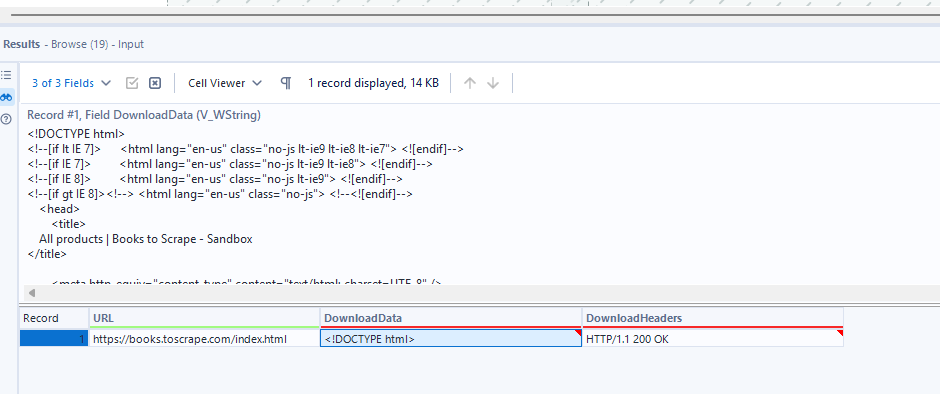
Check if your download was successful by looking at the Download tool's output:
- The
DownloadHeadersfield should read "200 OK"—this HTTP status code means the request was successful - The
DownloadDatafield contains the actual HTML code
You can click on the DownloadData cell in the results window, but you'll only see a truncated preview. To see the full HTML content, connect a Browse Tool—this lets you view the complete HTML source.
Pro tip: Copy the HTML content and paste it into a code editor like VS Code or Notepad++. These editors provide syntax highlighting and better formatting, making it much easier to spot patterns and understand the structure.
Step 3: Preparing the HTML for Parsing
Raw HTML is one long string, which makes pattern matching difficult. Let's break it down:
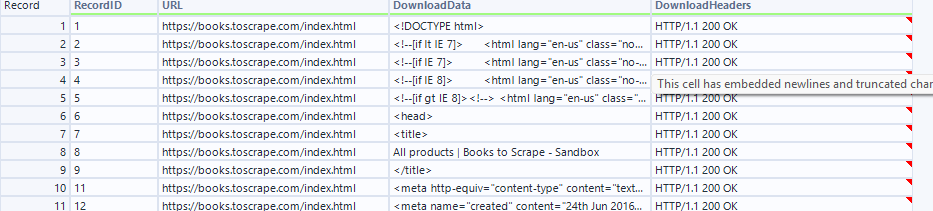
Text to Columns Tool: Configure it to split on newline characters (\n). This transforms the single HTML string into individual rows—one row per line of HTML code. This makes it much easier to target specific patterns and extract data.
Record ID Tool: Add a unique identifier to each row. This is crucial for tracking which line of code you're working with, especially since you'll be filtering out rows later and need to maintain context.
Data Cleansing Tool: Remove leading and trailing whitespace. HTML often has inconsistent spacing and indentation for readability, but these extra spaces can interfere with pattern matching and make your RegEx expressions more complex.
Filter Tool: Remove all empty rows. Many HTML files contain blank lines for formatting purposes, but these just clutter your data and slow down processing.
Now your HTML is clean, structured, and ready for pattern extraction.
Step 4: Dynamic Page Handling
One of the challenges with books.toscrape.com is that books are spread across multiple pages (20 books per page across 50 pages).
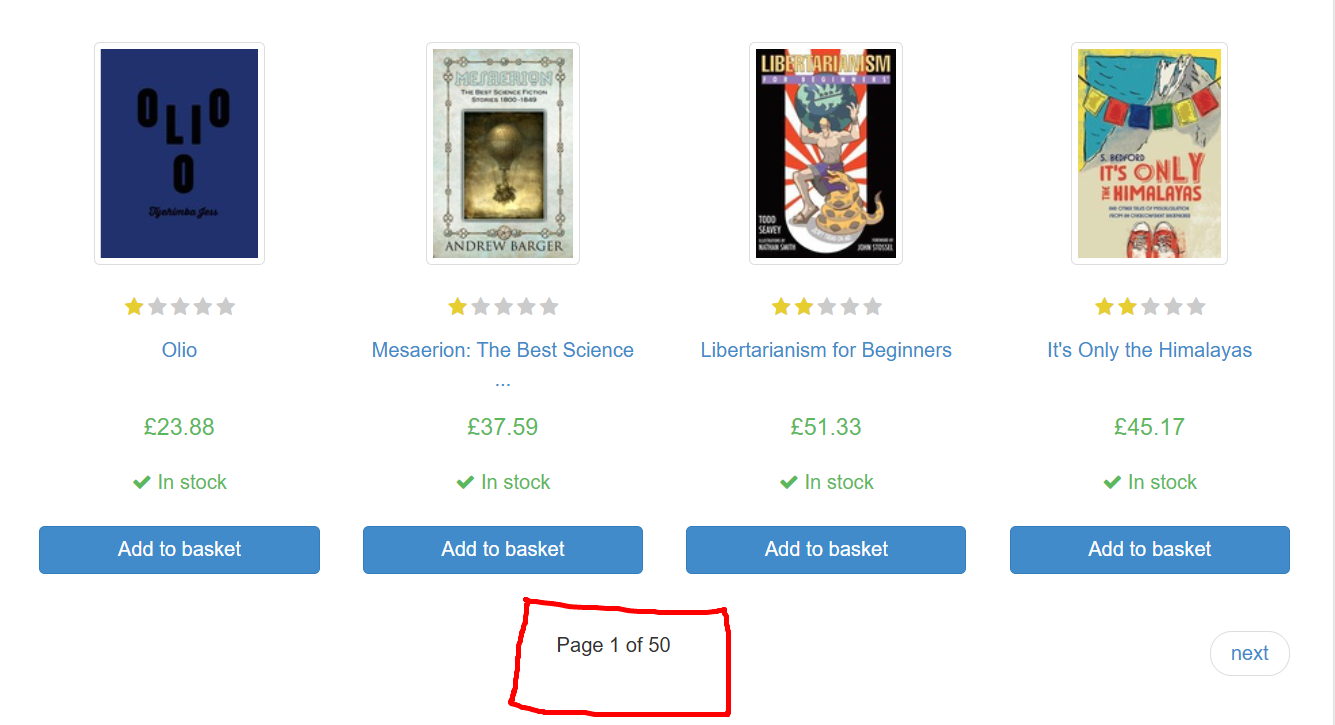
You could manually type "50," but what if more books get added? Let's make it dynamic:
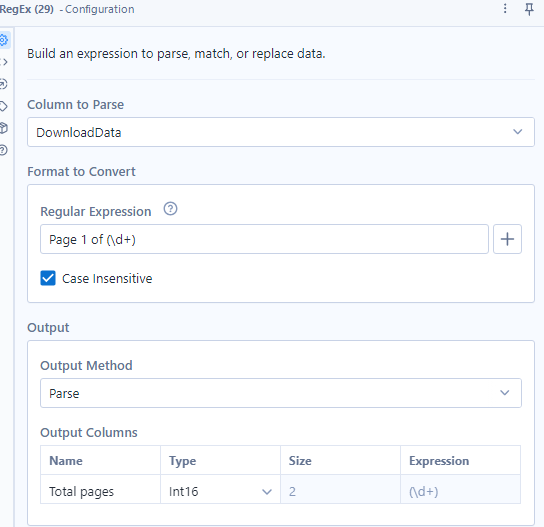
RegEx Tool: Parse out the total number of pages from the HTML. Look for text like "Page 1 of 50" in the HTML and extract that "50" (depends) using a regular expression pattern.
Generate Rows Tool: Create a row for each page number. If there are 50 pages, this tool will generate rows numbered 1 through 50.
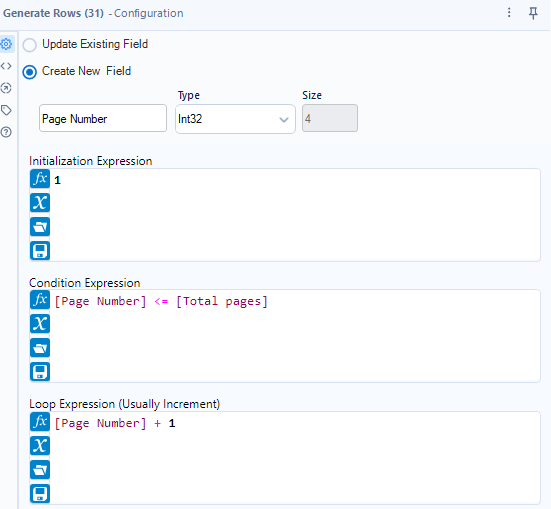
Formula Tool: Construct the URL for each page:
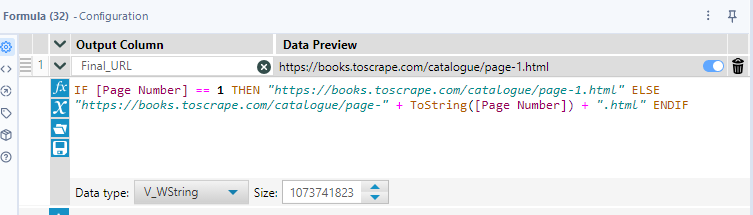
Download Tool: Download all page URLs using a download tool. Now you have the HTML content from every page on the site.
Repeat the cleaning steps: Run the Text to Columns, Record ID, Data Cleansing, and Filter tools again to prepare all the downloaded pages for parsing.

Step 6: Extracting Your Target Data
Before you start writing RegEx patterns, know exactly what you want to extract. For this tutorial, I want three pieces of information for each book:
- Title - The name of the book
- Price - How much it costs
- Rating - Its star rating
Examine the HTML patterns for each of these elements. You'll notice they appear in specific tags or attributes:
- Titles might be in
<a>tags with a specific class - Prices might be in
<p class="price_color">tags - Ratings might be in
<p class="star-rating Three">format
Use the RegEx Tool to create separate expressions for each field. Create three RegEx tools (or use multiple parse groups in one tool) to extract:
- One pattern for book titles
- One pattern for prices
- One pattern for star ratings
You can visit this blog for tips on using the regex tool
Step 7: Structuring the Final Dataset
After extracting your data with RegEx, you'll notice that the title, price, and rating for each book are on different rows. To get this into a usable format, you need to group related information together and restructure it. Use a Multi-Row Formula Tool to create a BookID that identifies when new book data begins (by checking when a key field like Rating appears), then you will need to do some filtering and transformation using BookID as your grouping key. This gives you a clean dataset with one row per book and Title, Price, and Rating as separate columns, ready for analysis.