


Last week, DS19 worked on a client project regarding National Student Service and university rankings. Part of what I had to do I had done it a few weeks ago for another client project. This time however, the data is public and therefore I can share my experience more accurately, hence the blog post.
The “issue”
The issue I had to work with was joining two datasets together. Sounds simple enough. In this case, I had to join a list of UK universities with different rankings and a list of postcodes and groups for each university.
The list of UK universities was at a subject level, meaning each row was a subject in a specific university. So there are several rows corresponding to each university depending on the courses they provide. The second data set was down to a university level, so one row per university.
The solution
If I was going to join both inputs on different conditions (as I had to do in the previous client project), there was risk of duplication. In this case, wanted to ensure I kept the first data set unique. Therefore, before I started to join them, I put a record ID tool on the main data set. Then I could begin the joining.
First of all, I tried to join using the university name as the common column. Many of them naturally joined, but not all. Looking at left and right outputs, I realized some of the ones that had fallen out was due to the name being spelled differently, such as King’s College London. In one data set it was spelled like I just did, in the other one it was “Kings College London”, with no apostrophe. This meant they did not match and it was the case for a few others. To solve this, I inserted a data cleansing tool on both outputs to remove any punctuation on the university name and tried to join them again. It worked! But there were still universities falling out of the join.
I repeated the process again:
- What’s falling out on the right and left outputs of the join?
- Is there anything in common between several of those rows?
The answer to those questions led me to use a find and replace tool. It seemed many universities had the word “University” or even “Uni” on the name in one data set but not in the other. It was not following a pattern, sometimes it happened in one data set, sometimes in the other. To solve this, I used Find and Replace where I was getting rid of “University” or “Uni” and replacing them with “ “. In this case it was words like “Uni”, in the other client project I had words such as “plc” spelled with capital P or with “.” at the end. Then I added a data cleansing tool afterwards to get rid of trailing white spaces and then I tried to join again. Many rows joined.
Lastly, I used a formula tool. First I changed all the university names to title case as they were different in both data sets. Then, in this case, as I wanted to have as many rows joined as possible, I also did some manual adjustments to ensure the remaining rows would match. This was because some rows appeared as “Solent” while on the other data set it was “Southampton Solent” so I had to change that manually.
Once everything from the first data set joined, I used a union tool with all the Join outputs (all those that did join) and once merged together, I used a Unique tool on the Record ID that I inserted before all the joins. This way I was ensuring there was no duplication.
Here is a screenshot of my workflow. The first part is the web scrapping to get the main data set ready to use. The second is the process I explained in this blog.

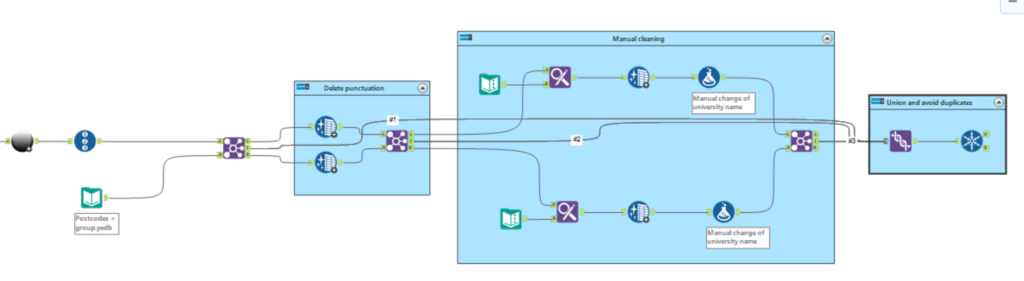
Conclusion
To summarise, I have encountered so far two client projects where joining data sets was necessary but they would not join perfectly at first. To maximise what did join, I had to make adjustments to each data set such as remove punctuation or common words that might be spelled differently. Then union all the joins together. And make sure to take advantage of the Record ID and Unique tools to avoid duplication.
Hopefully you find this interesting and helpful. Thanks for reading!