Today’s brief was a tricky one, using the Harvard data-verse, we were asked to parse out survey questions and assign them to headers in the survey results csv.
Initially using prep to break out the tables I quickly realized for what I wanted I could use Alteryx and a PDF macro (thanks to Ollie Clarke) to pull out the individual rows and filter out the questions that I wanted to use in my viz.
I noted out the questions that looked like they would give the best insight and went about joining these to the appropriate headers in the CSV and filtered those questions/fields down to a smaller much more manageable CSV than the original 500+ column nightmare we started with.
To get the scraped headers into the original csv I cross tabbed the data into headers then swapped the fields into the first row using the field info tool and row ID. Then unioned that together using a dynamic rename to push the new row into the headers and hopefully, in theory, this will be tableau compatible.
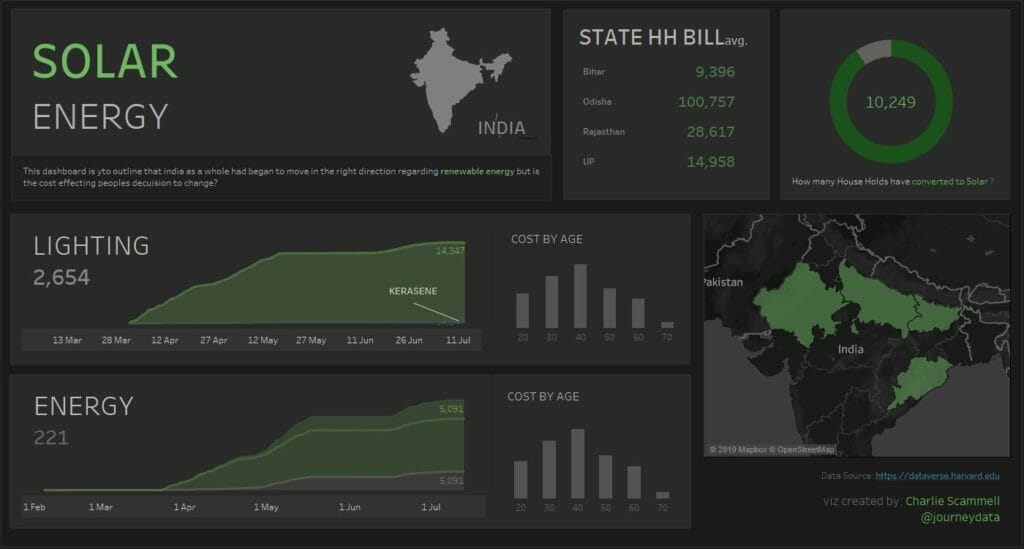
…So that didn’t quite go to plan, but the data was still salvageable, and I decided to look at solar energy in India and how the cost effects people’s decision to use solar energy options. I was hoping for more granular data when it came to the poverty divide in India but I couldn’t find a compatible data set to join with the raw data from the brief, so I stuck with the survey answers. And fleshed that out the best I could.
I made a comparison chart between solar and kerosene/grid energy options and seen a drastic difference between the two, so it skewed the data a little and doesn’t give as clear an analysis as I was hoping for.

Then due to time restraints I simply showed the rest of the data results in simple pie charts and maps to give a brief overview of the data and what the findings were.
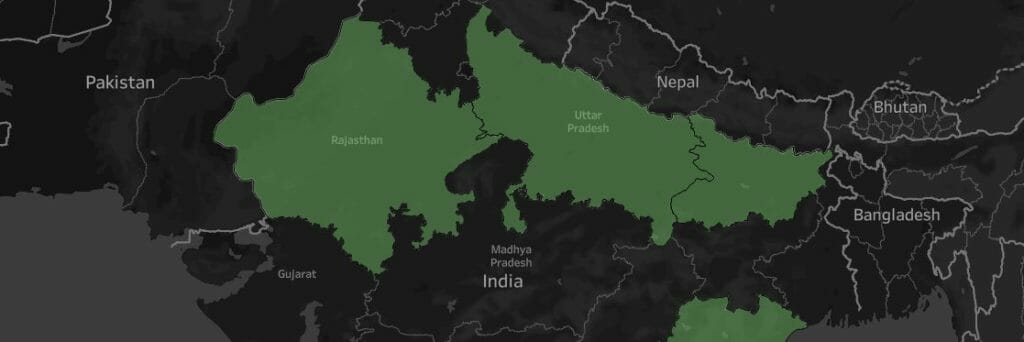
Not my best work again, but I did take some useful findings away from today and again, look forward to tomorrows challenge which hopefully does not involve survey data!
Completed Dashboard: