


We’re over half way through dashboard week! Today’s dataset was survey data from the SIPP website here. We each had to choose a topic from the following: economic well-being, family dynamics, education, assets, health insurance, childcare, and food security. I chose to focus on health care for today’s challenge.
The Data
There were a few challenges with the data which seemed to confirm that Andy likes to watch us struggle.
- Where to find the data – there were multiple links to multiple different sources, and no one was quite sure which to go for
- There was a huge amount of data stored in some files in formats that none of us had worked with before.
After witnessing Collin download a huge zip file full of survey data and then try to clean the data in Alteryx with not much success, I decided against using these files.
The Cheating: Data I could actually download
Instead, I looked around the US Census Bureau website to see if there was any SIPP survey data that would be easier to access and prepare as we have very limited time on dashboard week. Luckily, the Census Bureau does keep tables of aggregated survey data and I found some tables from the SIPP surveys.
However, the most recent table for SIPP surveys related to health insurance was from 2011. This data seemed a bit dated so I did some more digging and found this table from the Annual Social and Economic (ASEC) Survey which had data from 2017. The table for this data also included insurance coverage breakdowns for a variety of different characteristics such as age, race, nativity and region – this seemed like a good option for analysis.
More Cheating in Excel
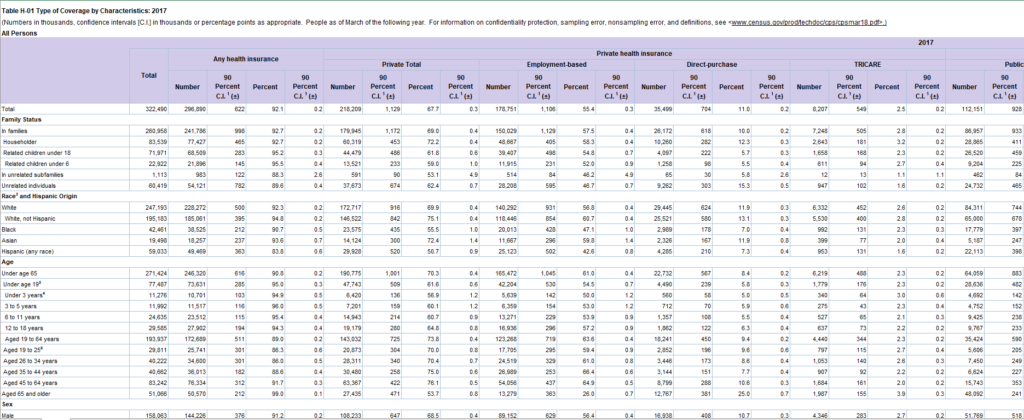
Although this data was in a nicely formatted excel table, these merged cells weren’t working for me. I could have probably tidied this up in Alteryx but thought it would be much quicker and easier to do this in Excel. Once I’d split the table off into elements I was interested in, got rid of the merged cells and drilled down categories I moved over to Alteryx.
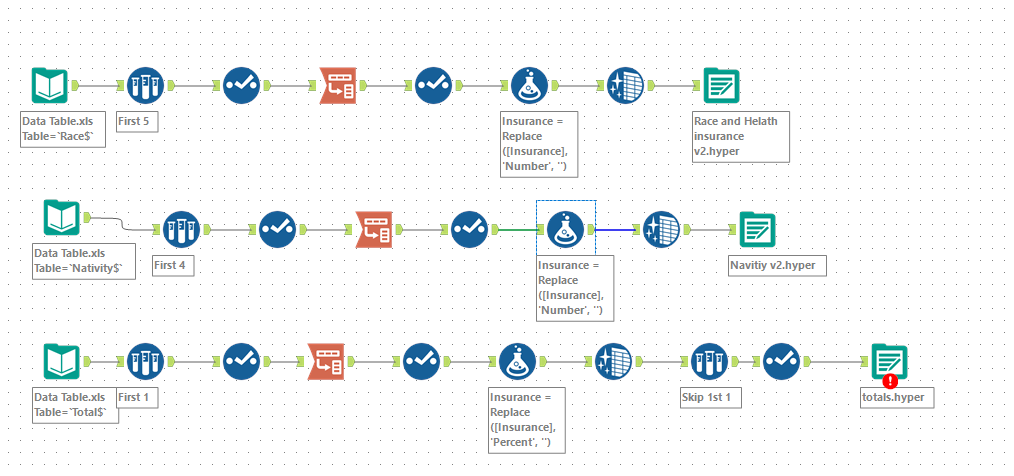
In Alteryx it was simply a case of pivoting the data and some further cleaning, as you can see below:
Investigation and Design
Once I’d prepared and cleaned the data I was left with numbers of people who has reported their different types of health insurance. As I had data for different characteristics and different insurance types but only data for one year of the survey, I thought that a parts-to-whole analysis would be best.
Andy directed us towards Steve Wexler’s survey data analysis as a good example, his stacked bar charts stood out as something that could really work with my data.
For my visualisation, I chose to focus on the disparity of insurance types in terms of nativity and ethnicity with simple stacked bars side by side.
My main insight with this data is that nativity appears to have a big impact on health insurance type with 25% non-citizens being uninsured entirely and another 25% reliant on public insurance.
