


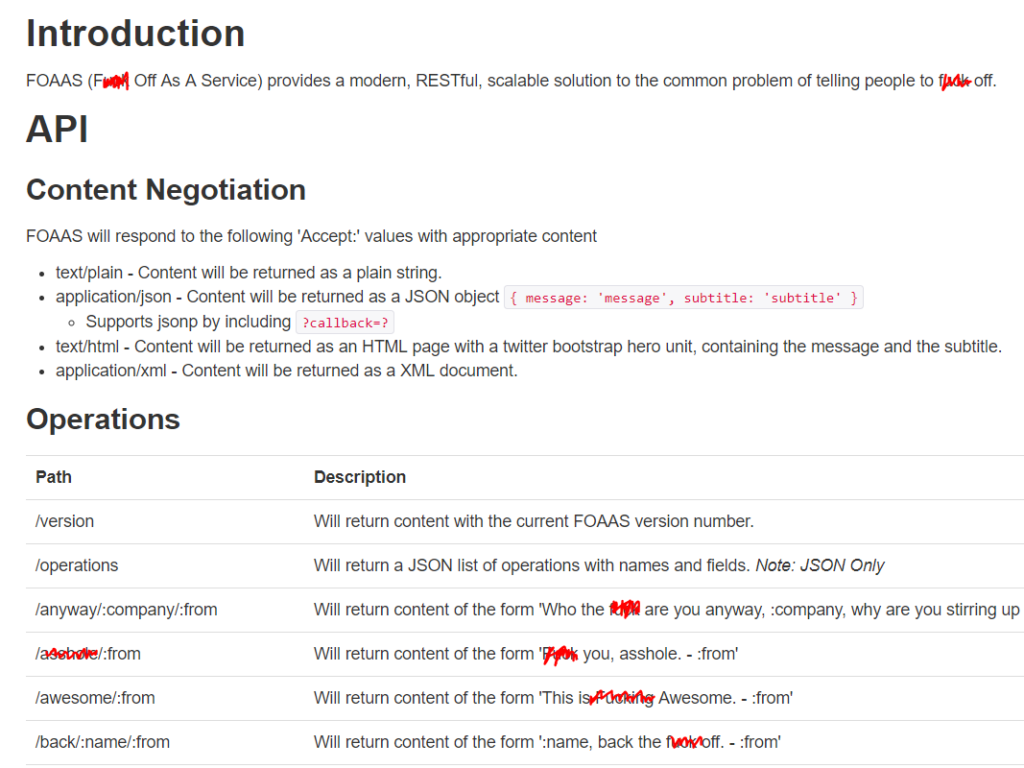
On day 1 we were tasked with obtaining data from an API called “F**k of as a Service”, whose descriptor is “a modern, restful, scalable solution to the common problem of telling people to f**k off”. This API will return you an insult based upon the calls you make (see below).
For example: https://foaas.com/you/andy/ellen” and that would return ‘F**k you, Andy. – Ellen’.
Our aim was to bring back as many of these insult strings as we could, separate out each word, and see which words were most commonly used.
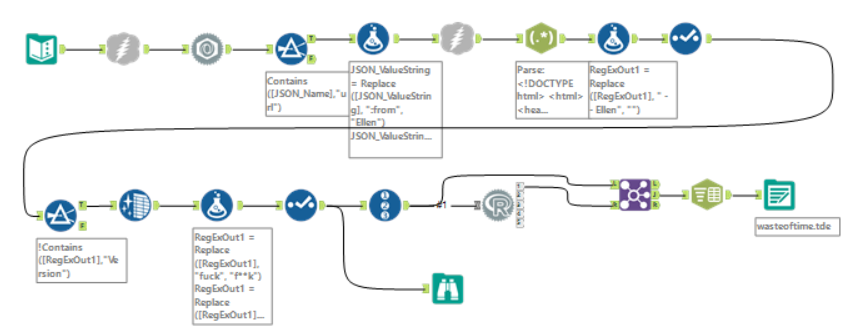
This the finished workflow:
- Firstly, we entered this link into our text input: https://foaas.com/operations
- Adding operations at the end of the URL will return the full list of JSON list of operations with names and fields.
- Next, we used a download tool to retrieve information.
- Then we used a Json Parse tool – (this allows us to access the meta data of an object in java script). This returned us the json name and the json value string – the Json value contained our list of operations.
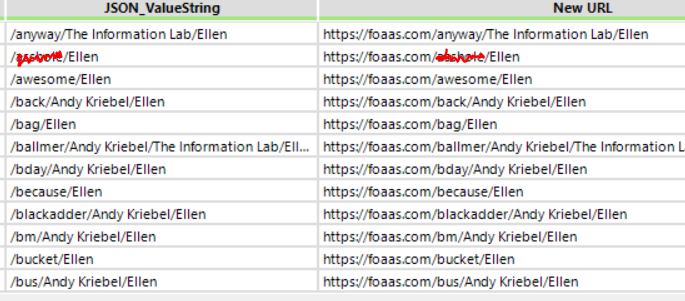
- We then filtered to obtain the json values which contained URLs – as these were the list of operations which gave us the variables for the required suffix format for each of the calls (see below).
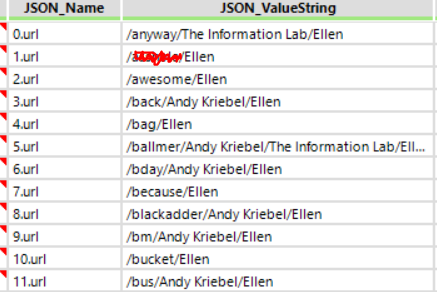
- We also updated the values to personalise each insult.
- Accordingly, we took the updated value strings and added these to the end of the generic URL used to call the API, to create a spectrum of links required to receive all the generated insults that the API provides.
- Thus, a second download tool was used to get the html from the new URLs.
This URL
+ the value string, creates the new URL for our API calls
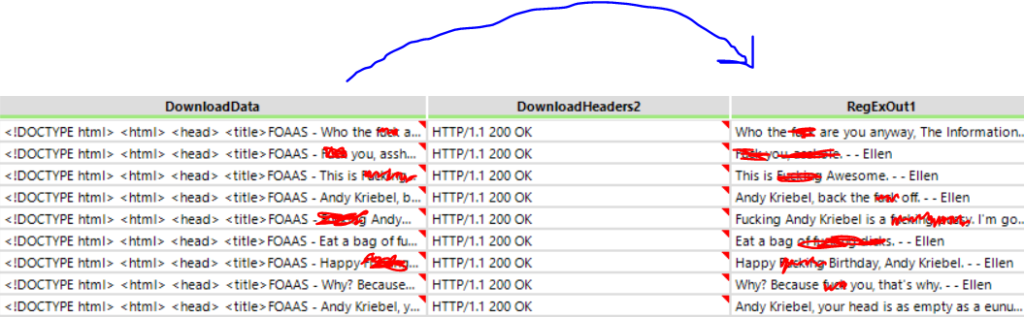
- The resulting download data included the generated insults, alongside many tags and other information we didn’t require – accordingly, we used regex to retrieve the insults from these long strings. In the picture below, you can see the beginning of the sentence in the download data, and the output of these insults following regex.
- next was some overall cleaning and some data cleansing to remove punctuation and make case consistent, allowing for comparison, alongside adding a Record ID. This ID will allow us to match up our words and phrases later on in the work flow.
- Next we used some R. This tool created bigrams, which grouped the words up into pairs (this didn’t really achieve anything, but I at least tried using R for the first time. This kind of process can be used within sentiment analysis, however, we couldn’t achieve that here).
- We then joined these bigrams back to the original phrases we pulled them from, so we know where they came from.
- Then split the bigrams into two words, to see which words were most often on the preceding the pairs and which were often following (again, not much utility in this).
- Then we output it.
- With this I created a simple word cloud – as I couldn’t think of much else. I’m not proud of myself.

My viz – I apologise in advance.