


So today’s challenge involved a little(!) bit of PDF scraping combined with survey data. The data set was from Harvard DataVerse and we had one table with all the data and then a separate PDF file containing the questions of the survey. The data was an electrical household survey in India.
Using Alteryx I inputted the headers using Ollie Clarke’s wonderful PDF Parsing macro. The headers and formatting were all over the place, so I decided to focus my analysis on the lighting section of the survey,, specifically Kerosene which was question 4. It took A LOT of Regex and to plenty of preparation tools to get the headers in the correct format to union to the table containing the data.
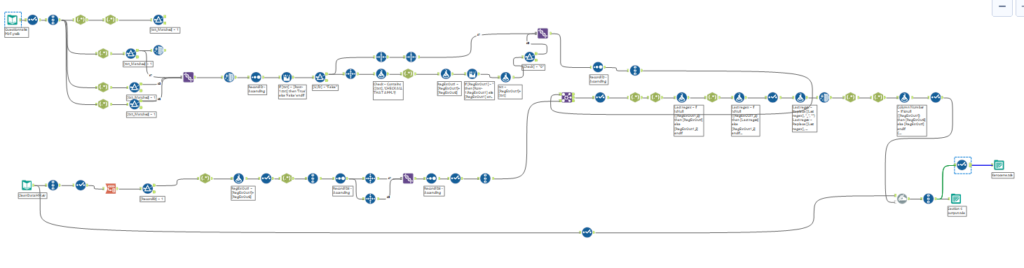
My final Alteryx workflow looked a little like this- I definitely did not need as many tools as I used!
I decided to join a spatial file containing the geometry of the Indian villages, and then focus my analysis on the state of Bihar. I looked into the use of Kerosene and how the amount and price of Kerosene varied.
This was how my final dashboard turned out!

Today was 100% the most stressful day of the week so far, fingers crossed Thursday and Friday are more successful and I can produce a more informative dash!