This is the final post in my Statistics Series and it will be focusing on classification. Previously in the series I’ve shown how to generate clusters in both Alteryx and Tableau, as well as describing Time Series analysis and how to do it in Alteryx.
Classification
The example here is using a Iris flower data set with width and length of petals as well as width and length of sepals.
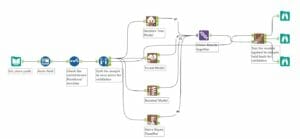
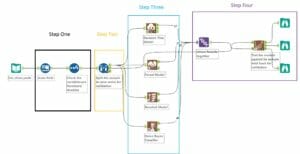
See the image at the bottom for an annotated work flow.
Step One: Prep the data
Run the auto-field tool on the data. This is a quick way to determine that the contents of the fields are assigned the correct field types.
Use the select tool to then double check and ensure the variables are ‘doubles’, because as with any analysis, the process runs a lot quicker using numerical values rather than strings.
Step Two: Create a sample
The sample needs to be split to allow us to validate the our models later on. The Sample tool helps us split the data on an 80:20 ratio.
Our sample is the 80 ratio and the population is the 20. The validation process on the population is to see if the model applies to ‘new’ data.
Step Three: Model the data
There are a few different types of models you can use in classification. I’ve very briefly described them here but for more information click on the links as the Alteryx Documentation is amazing.

Boosted Model – generalised regression models using Gradient Boosting methods

Decision Tree Model – looks at routes of connections. Often used when one or more variable fields that could predict the target field

Forest Model – essentially a set of decision tree models, using randomised parts of the data (a sampling method called bootstrapping)

Naive Bayes classifier – binomial or multinomial probabilistic classification model that looks at the relationship between the sets of predictor variables
Note – you may need to downgrade the models so that they are all on the same ‘grade’ to allow for comparison in the model comparison tool (NB see Nick’s post on model comparison)
It’s best practice to use a few different types of model on the data, and then you can find the one that works best.
Step Four: Compare the models
Union the results of all 4 models together and use the Model Comparison tool. This tool is not included in the Alteryx predictive tools package so you’ll need to download it from here.

The model comparison tool runs various tests on the model results, to determine which is the most accurate – i.e. has the least error, primarily the root meet squared error.
sdfsdf
Chose the model with the accuracy closest to 1.

Therefore the Boosted model is the best model to use in this case, predicting Iris class with the highest accuracy.
sdfsdf