


This Blogpost is about the logic behind the Fuzzy Matching tool. Understanding the logic helps to optimize the matches of the tool. If you have not used the tool before I recommend reading my previous blog post explaining the tool or an Alteryx community post, explaining how to input data into the tool.
Order of the Matching Steps
In Alteryx, the Fuzzy Matching tool uses multiple steps.
1. Preprocess
Here you can define how to transform the incoming string before the fuzzy matching is done. I would not recommend using this, as you can do this with classic Tools before, and there you can see what is happening and change it if something isn’t going as expected.
2. Generate Keys
Based on the defined algorithm Alteryx will generate a key. If you specify it to be “None”, this step will be skipped. I will explain the key-generating algorithms later. Here you can also exclude certain words, e.g. “AND OF THE CO CORP INC SVC MD CTR”, which could be a valid option for the comparison of company strings.
3. Match Function
Here the actual matching happens. Dependent on the key, or if u specified none, on the actual string, you can select between abbreviations of two algorithms (Levenshtein and Jaro), explained below.
Fuzzy logic, unlike the classic Boolean logic (used in Joins), is not a yes or no match, but rather gives you a percentage, of how well two strings match.
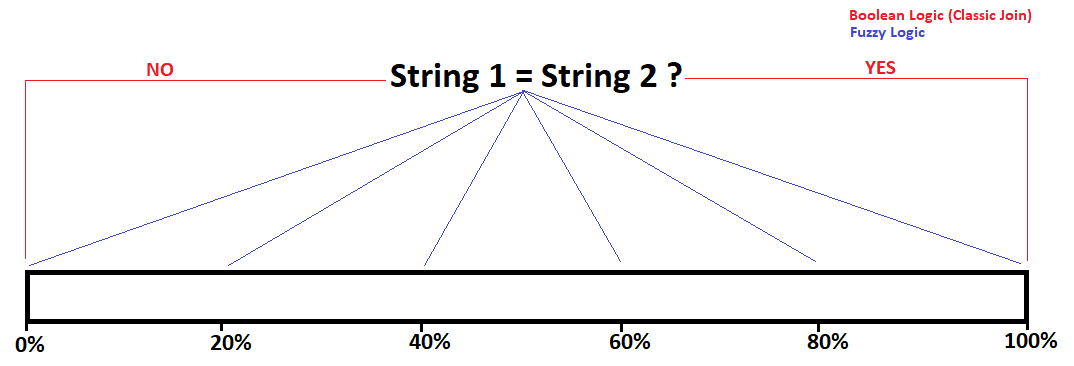
Fuzzy Matching is not Alteryx-specific. These algorithms to match strings have been in use for decades and can be used with many different Tools. In Alteryx they are easily accessible, but understanding them is key to optimizing fuzzy matching.
Generate Keys
Alteryx Fuzzy Matching allows you to generate keys, which will then be used in the following matching process. There are two major algorithms used for this, both are based on how a word sounds.
Soundex
The Soundex algorithm is dependent on how a word sounds (phonetic algorithm). It is useful for the matching of words that are pronounced similar, e.g. the use case it was designed for was the matching of family names. [1]
The Soundex algorithm generates a key consisting of one letter, followed by three digits. Since this algorithm is dependent on the language, this differs in other languages. Only the English spelling is included in Alteryx, for matching, words in other languages might lead to problems.
The algorithm follows a simple logic. The first letter is always the first letter of the string, the following three digits are generated using table 1. Any vocals and h, y, w, which don’t appear in table 1, are eliminated.
|
letter |
Number |
|
b, f, p, v |
1 |
|
c, g, j, k, q, s, x, z |
2 |
|
d, t |
3 |
|
l |
4 |
|
m, n |
5 |
|
r |
6 |

The Soundex-Algorithm is extremely sensitive to the start of a string, while only the first few letters matter. When you compare long strings, this means that you lose a lot of information in the key and your results may get worse.
The Alteryx implementation is also not able to use the tables of other languages, therefore this isn't the best algorithm for strings in other languages.
Double Metaphone
The Metaphone algorithm is younger than the Soundex algorithm, and it is still being developed, to improve it constantly.
The Metaphone algorithm is much more complex. It follows a certain set of rules (see Wikipedia). The Double Metaphone version is an improved variant of it, a third version, Metaphone 3 also exists but is not implemented in Alteryx.
The problem with this algorithm is, that it’s not intuitively understandable, since it includes hundreds of different rules. Due to this, it is a good default choice as the key in Alteryx but may also be annoying when you manually want to change how these things work.
The same problem as with the Soundex algorithm applies here as well, this is an English-only algorithm, and it may not work very well with other languages.
Matching Algorithms
Let's get to the matching algorithms. They are non-vocal algorithms that use the keys or the original strings if no key is selected, to compare them. There are two algorithms implemented in Alteryx and some abbreviations of those.
Levenshtein-Distance
The Levenshtein Distance is measuring how different two strings are.
The Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other. [2]
This approach is pretty simple and easy to understand when you compare the strings:
- car & far – One character differs from the other, meaning the Levenshtein-Distance is 1.
- car & for – Two characters differ, therefore the Levenshtein-Distance is 2.
- car & fame – Three characters differ, therefore the Levenshtein-Distance is 3.
Here we can already detect a possible problem with using the Levenshtein Distance, different word lengths are affecting the algorithm strongly. Especially with common additions to strings, like “inc.” for companies, this can be a big issue.
E.g. “Apple Inc.” & “Apple” has a Levenshtein-Distance of 5, while “Dell” & “Apple” would only have a Levenshtein Distance of 4 and would therefore be the match found with fuzzy matching using Levenshtein Distance.
Jaro-Distance
The Jaro Distance is the alternative choice you can pick in Alteryx. It also takes into account whether the characters of one string are also within the other string, but at a different place. The result is the similarity of the string as a number between 0 (no similarity) and 1 (same string).
The Jaro similarity can be determined using the following formula:
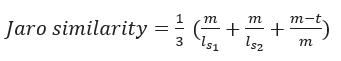
With:
lsn= length of string 1 or string 2; m= Number of matching characters; t= Half the Number of transpositions (The number of matching characters with a different sequence order)
Let’s take a look at earlier examples:
- car & far – m=2, t=0, ls1=3, ls2=3 → 0.78
- car & for – m=1, t=0, ls1=3, ls2=3 → 0.56
- car & fame - m=1, t=0, ls1=3, ls2=4 → 0.53
We can see, that the impact of the string length decreases, the Jaro similarity in examples 2 and 3 is much higher than with the Levenshtein Distance.
With “Apple Inc.” & “Apple” we get m=5, t=0, ls1=10, ls2=5 which leads to a score of 0.83 and “Dell” & “Apple” leads to m=1, t=0.5, ls1=10, ls2=4 → 0.075.
Here we see that there is nearly no match with those two strings and we get the correct Assignment, unlike with the Levenshtein Distance.
Both matching algorithms have some advantages over the other, but it’s hard to say which one performs better in a specific case. As the default usage, I would recommend the Jaro algorithm, but of course, trying out both (or the combination of both) and comparing the results is always the best idea.
Picking the correct key-generating algorithm and then a fitting matching algorithm is quite complicated. Understanding them is crucial for this purpose. Feel free to always try out multiple combinations to find the best matching settings. If your dataset is big and it takes a long time to run the tool, use smaller subsets to minimize the time for the testing of multiple algorithms.