


Background
Before joining the Data School, I worked as a Pricing and Revenue Analyst for a car rental company. The job title was fancy, and the advert intriguing. Promising analysis of previous and current market trends, development of competitive pricing strategies and much more, I was eager to apply. My excitement stalled somewhat during interview when asked if I minded repetitive work.
My job turned out to be an 8-hour trawl through car rental comparison websites on one screen whilst updating prices in an excel spreadsheet on another. This mind-numbing process of ensuring we led the market usually took until lunchtime. I would then repeat the same process after lunch in case any competitors had updated their prices. I could typically price for about a month into the future and was part of a 4-person team with different sites split between us.
It struck me that the whole process was inefficient, costly considering the size of team and prone to human error. I took the job to save some money to go travelling and would often day dream about automating the process and selling it to the CEO instead. I however lacked the technical know-how and learning to code from scratch in order to automate myself out of a job just didn’t seem reasonable in the short time I had before I planned to go travelling.
Fast forward a year and I’m in the Data School learning how to web scrape with Alteryx. We were given a web scraping project with the freedom to go in whatever direction we wanted. I knew my direction. I wanted to compare the prices of low-cost rental cars across the UK.

Context
To understand a bit more about what I wanted to automate I’ll explain more of what my job entailed. There were different car types, such as Compact, Mini, Standard, each with unique limits on how low we could go. Therefore, whilst the goal was to try and lead the market by having the lowest price, this was not always possible if competitors were priced below the minimum price threshold for that vehicle type. These thresholds would have to be included as a customisable option in the automated system. It could also be useful to have these limits customisable by location as pricing in Heathrow may differ from Wigan.
The focus on accurate pricing was usually on 1, 3, 5 and 7 day rentals, but this seemed like a human limitation to me, something a machine need not consider.
Some car types would have multiple versions but only the cheapest needed to have their prices looked up as the others were formulated using the first versions price.
The spreadsheet would have all the locations on with prices for all dates for about a year. This spreadsheet would be uploaded, and the actual prices would update accordingly. The prices didn’t actually translate across perfectly from the spreadsheet as there was some kind of formula in-between. I can’t remember exactly how this worked so didn’t try to account for it in my project, but the formula tool in Alteryx could easily do this. The structure of the spreadsheet which I would need Alteryx to spit out was something like the picture below:
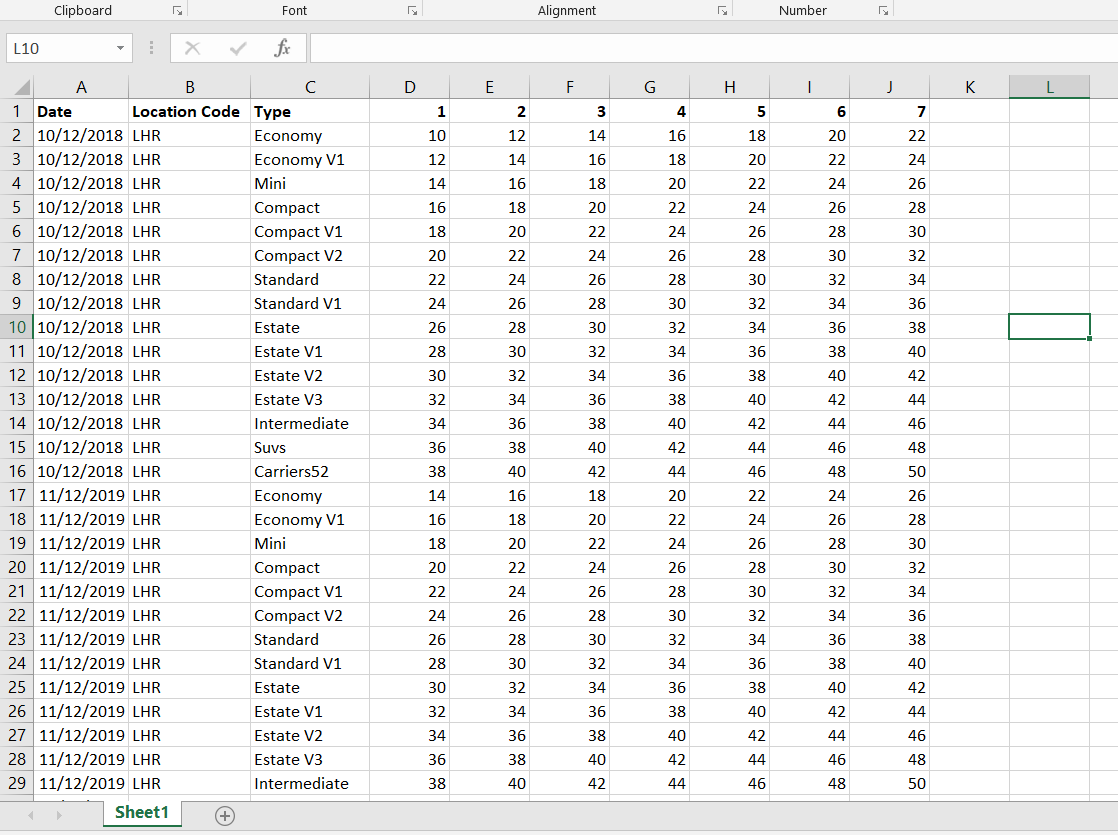
This spreadsheet would continue with a range of dates and different locations.
For the purposes of this blog I’ll refer to my old company as BargainCars.
Getting and Cleaning the Data
To web scrape in Alteryx a text tool containing the URL of the site to be scraped needs to be used as the input. I used a text tool with the Rentalcars.com URL’s for 1-7 days rentals on the 10th of January from London Heathrow Airport. These were used initially to make the workflow and test it could produce a spreadsheet in the correct format for one date in one location.
The text tool was connected to a download tool which took the URL’s from the URL column and outputted to a field as a string. This was all that was needed to scrape the data from Rentalcars.com, and so the workflow was cached and ran to avoid repeated scraping.
Every URL (one for each length of rental, 1-7 days) now had a single row in the Downloaded Data column which contained all its HTML source code. Inspecting this source code in a text editor led me to believe that splitting it into separate rows at every “<” was the best way to isolate the key bits of information I needed; the date, location, vehicle type, price, brand and what car it was. This was done using the text-to-columns tool.
The workflow was then split into 6 separate streams, one for each of the key bits of information I needed. Something unique was found about the line this information was on in the HTML code and this was used in a filter tool set to contains “…” The stream coming out of true as a result only contained the lines I needed. The replace function in the formula tool was used to get rid of useless text, data cleansing to remove punctuation and white-space and text to columns to split parts up when needed.
Each separate stream for brand, car, vehicle type and price were given record ID’s using the record ID tool and were joined using these ID’s and the URL’s (as the lines would be in the correct order). The date and location columns were joined using the URL column. This resulted in the complete cleaned data set which was subsequently sorted by vehicle type, days of rental then by price. The data now needed to be transformed and shaped into the format required for the pricing spreadsheet.
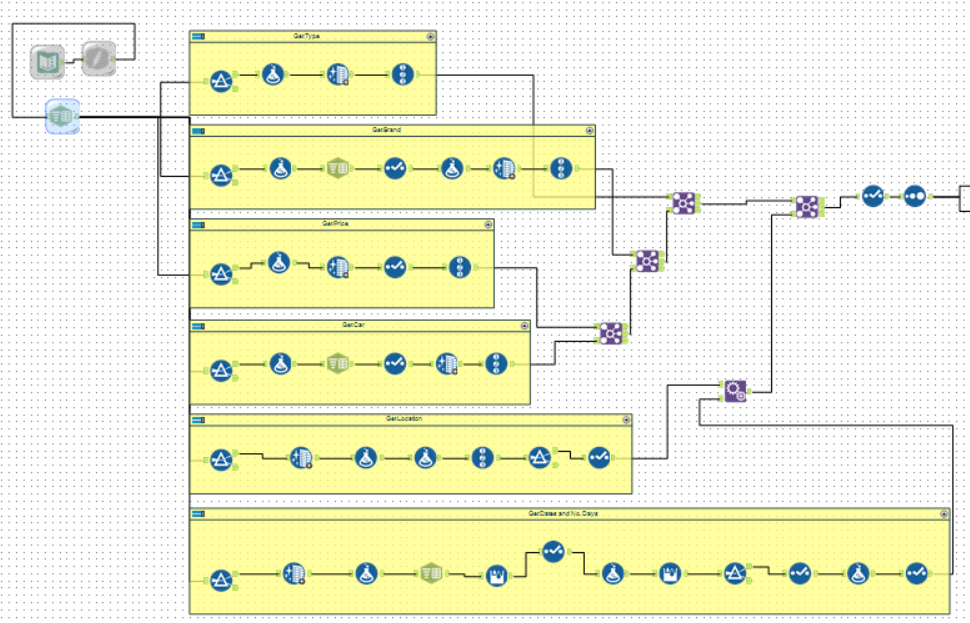
Transformation/Formatting of the Data
The workflow stream was then connected to a filter which was used to break down the data to one vehicle type, for example “Economy.” This led to a multi-row formula tool which created a new record ID column using the formula:
“IF [Days] > [Row-1:Days] THEN 1 ELSE [Row-1:RecordID] + 1 ENDIF”. This essentially ranked each row (car rental) by price, starting again for each extra days length of rental.
The stream was then connected to another multi-row formula tool which created a yes/no column using the formula:
“IF [Row-1:RecordID] = 1 AND [Row-1:Brand] = “BargainCars” THEN “Yes” ELSE “No” Endif”.
This was to allow the breakdown of the dataset to whichever brand was priced cheapest (record ID 1) and BargainCars, or BargainCars and whichever brand was second cheapest if BargainCars was first. This was done using two filter tools. The first filtered using the custom filter “[RecordID] = 1 OR [Brand] = ‘BargainCars’.” As a result, the true stream gave whichever brand was priced cheapest and BargainCars. This would be enough if BargainCars was not the cheapest, but in case it was the false stream was connected to another custom filter “[RecordID] = 2 AND [BargainCars 1st?] = ‘Yes’.” This would only filter the second cheapest brand through when BargainCars were the cheapest brand. Unioning the two true streams from the filters therefore resulted in the required rows.
The stream was then connected to another multi-tow formula tool which updated the price column using the formula:
“IF [Brand] = ‘BargainCars’ AND [RecordID] = 1 THEN ([Row+1:Price] – 1) ELSEIF [Brand] = ‘BargainCars’ AND [Days] = 1 AND [Row-1:Price] >= 10 THEN ([Row-1:Price] – 1) ELSEIF [Brand] = ‘BargainCars’ AND [Days] = 1 AND [Row-1:Price] < 10 THEN 9…”
The first line IF statement ensures that if BargainCars are leading then make sure it is only by one dollar. The following two lines make sure if BargainCars isn’t leading for 1-day rentals then be cheaper than whoever is leading down to a minimum threshold of £10. The second two lines were then repeated for all 7 days of rental with different minimum thresholds for each.
Dummy rows were added and the use of the formula and multi-row formula tools ensured that if a car type was repeated it would be given the V1 suffix or V2 etc. depending on how many types. These would then have their prices set to 1.25 times higher than the version before. This completed the pricing part of the job, the data now just needed to be structured correctly for the spreadsheet.
The stream was then connected to a filter tool and filtered on brand so that only BargainCars’s data remained. A transpose tool then grouped by the Date, Location Code and Vehicle type, and the Days became the new column headers with the Price as the values. This filtered out what was not needed resulting in a correctly structured row for the vehicle type filtered at the start.

This stream was made into a batch macro which replaced the filter value (car type) with the types from a new stream broken off earlier which filtered to BargainCars only, and summarised to car type. This meant the stream would repeat for each car type that BargainCars had data for. However the possibility of BargainCars selling out resulting in no scraped data, and therefore no prices, had to be accounted for. To ensure these still had values in the spreadsheet a separate batch macro output was added which spat out just the date, location car type. This was joined with a text file containing all the available car types with standardised values. The stream was then unioned with the batch macro output and sorted. A multi-row formula tool was then used to generate an ID column which could be used to filter out and duplicated car type rows, leaving only the car types from the batch macro and the standardised car types not included in the macro. This resulted in the completed data set which needed only to be cleaned and ordered correctly using the formula, sort and select tools.
Running the workflow produced the spreadsheet below:
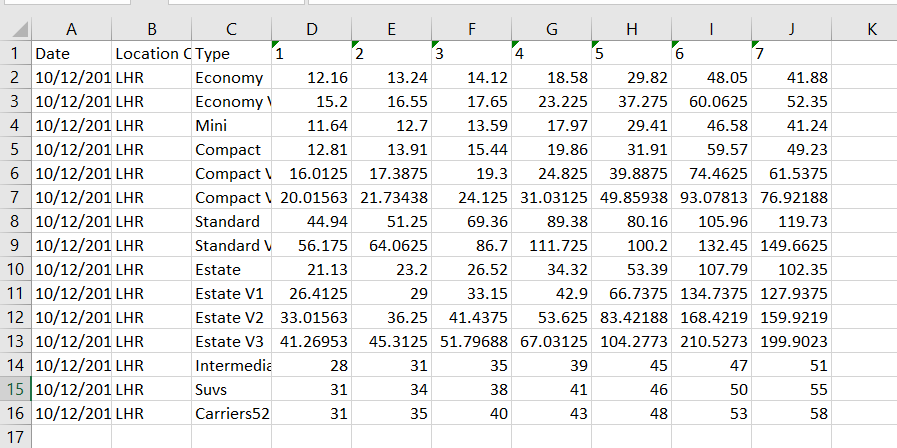
The bottom numbers look out of place due to my poor estimation of the standardised values, but these defaults can easily be changed.
The spreadsheet was correct for a single date in a single location. This was as far as I got in my project. Not quite ready to function as a Pricing and Revenue Analyst but a good proof of concept. Join me in part two where I will add customisation to the workflow using macros, add additional outputs to Tableau and ensure the spreadsheet works for all locations and dates.