


Us data school 11 students were given the task of sorting out messy excel based datasets in our first attempt at using Alteryx. Louise and I were given an IMDb dataset which had a column of rows alternating between the film title (and date) followed by the IMDb ranking (and number of positions it had changed).
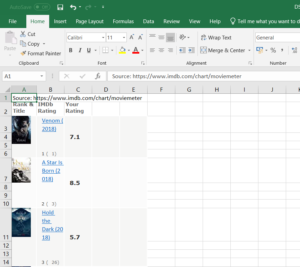
Original unusable dataset
In order to use the data we had to separate these alternating rows into two separate columns. Here’s how we did it:
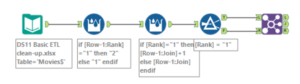
We connected a Multi-Row Formula to the loaded dataset creating a new field with title “Rank.” It had a value of “0 or Empty” for rows that don’t exist and was given the expression:
if [Row-1:Rank]=”1″ then “2” else “1” endif
This meant that an extra column was added with a 1 for film titles and a 2 for IMDb rankings. (If the row above is 1 then you’re a 2, otherwise you’re a 1)
We connected to this another Multi-Row Formula. This too created a new field with the title “Join” and had a value of “0 or Empty” for rows that don’t exist. It was given the expression:
if [Rank]=”1″ then [Row-1:Join]+1 else [Row-1:Join] endif
This meant that column was added where each film title and its corresponding IMDb rank in the row below would have the same numeric value in the Join column (both 1, then both 2, then both 3…). (If the rank value is 1 then add 1 to the value above in the Join column, otherwise be the same as the value above in the join column).
We then connected this to the Filter function using the basic filter “Rank = 1”. This split the data into true and false. The true split contained the film titles as they had the rank value of 1. The false split contained the IMDb rankings as they had the rank value of 2.
This was then connected to the Join function. The true data joined from the left on the “Join” column, and the false data from the right on the “Join” column. As the film titles and corresponding IMDb rankings had the same Join value the data was correctly structured with them on the same row but in different columns. We therefore successfully split the alternating rows into two separate columns.
After completing this (along with some other changes/formatting) we had a usable data set:
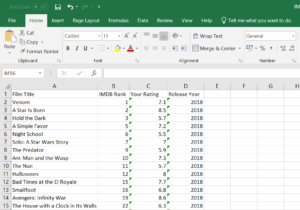
Completed data set with separate columns for Film Title and IMDb Ranking.