


I have a script in Python that I want to automatically run every hour, save the contents to an S3 Bucket and connect that bucket to Snowflake. AWS Lambda is a great tool to use for this pipeline. This blog is part 1 that covers:
- Creating a Lambda function
- Preparing the Python script for AWS Lambda, setting up environment variables and layers
- Deploying function trigger
Creating a Lambda function
Log into AWS, go to Lambda, then Functions and select ‘Create function’.
I created my function from scratch. I named it, chose the Runtime Python 3.13 and left everything else unchanged. Then click ‘Create function’.
If you scroll down, you will see the Code source canvas where we can add our Python script. Here is the original python script I developed in VS Code:
import requests import pandas as pd import os from dotenv import load_dotenv load_dotenv() app_key = os.getenv("app_key") base_url = "https://api.tfl.gov.uk/Line/Mode/tube/Status" params = {"app_key": app_key} response = requests.get(base_url, params=params) if response.status_code == 200: data = response.json() retrived_at = pd.Timestamp.now() lines_info = [] for line in data: name = line.get("name", "Unknown") statuses = line.get("lineStatuses", []) if statuses: status = statuses[0].get("statusSeverityDescription", "Unkown") reason = statuses[0].get("reason", "") else: status = "No data" reason = "" lines_info.append({ "Line": name, "Status": status, "Reason": reason, "RetrievedAt": retrived_at }) df = pd.DataFrame(lines_info) print(df) else: print(f"Failed to fetch data")The original script calls the TfL API and creates a data frame that looks at each tube line’s status and the time of day.
However this script won’t work straight away. There are four things that need to change to get the script working in AWS Lambda.
Preparing the Python script for AWS Lambda
- From Script Entry Point to Lambda Handler
In a regular Python script, everything starts executing from the top when you run the file. But AWS Lambda needs a specific entry point, called the handler function. That’s why we wrapped the main logic in:
def lambda_handler(event, context):
This is the function AWS Lambda calls when it executes your code. You can’t just start your code from the top like you would locally.
- No .env Files – Use Lambda Environment Variables Instead
Your original script used .env and dotenv to load secrets like the API key:
from dotenv import load_dotenv
load_dotenv()
app_key = os.getenv("app_key")
But Lambda doesn’t automatically know how to load .env files. Instead, you store your secrets securely using Lambda environment variables, which you define in the AWS Console.
To create an environment variable, go to the Code source and there is a label called ENVIRONMENT VARIABLES, hover over it and there is a + button to create an environment variable. Simply add a name and value, then click Save.
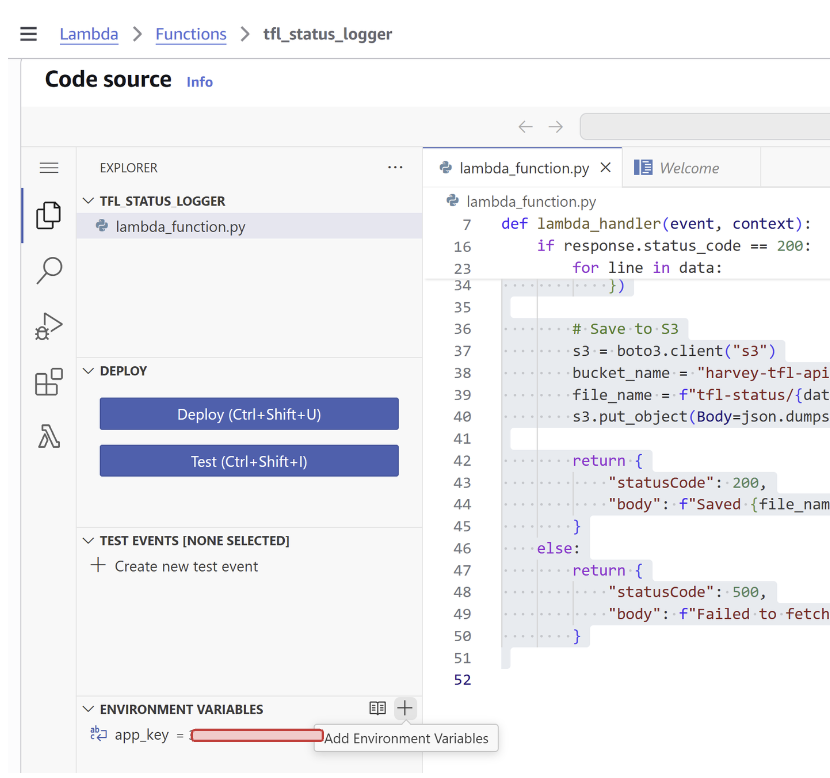
So the new code simplifies to:
app_key = os.environ["app_key"]
- Creating a Layer for libraries
Libraries like requests aren’t included in Lambda by default. There are 2 ways to include them:
- Manually upload a .zip file containing the package to the Code source
- Create a Layer with the .zip file inside, these are better as they can be reused across multiple Lambda functions.
First we need to create the .zip file, create a folder somewhere on your computer:
C:\Users\HarveyJoyce\Downloads\aws-layer
Open command prompt and change the directory to this new folder:
cd C:\Users\HarveyJoyce\Downloads\aws-layer
We need to add in a certain folder structure within the directory:
mkdir -p python
The folder must be named python, this is important because AWS Lambda looks for packages in a python/ folder inside the zip.
pip install requests -t python/
This installs the entire requests package (and its dependencies like urllib3, chardet, etc.) into the python/ folder.
zip -r requests_layer.zip python/
Now zip the python/ folder (not the parent, just the folder itself). This creates a file called requests_layer.zip, this is what you’ll upload to AWS.
To create a layer, go back to the main Lambda home page, under Additional resources, click Layers. Click ‘Create layer’.
Give the layer a name. Select ‘Upload a .zip file’ and select the created .zip file.
I selected x86_64 for compatible architectures and Python 3.13 for compatible runtimes (needs to be consistent with Lambda function), then click ‘Create function’.
Go into your function again, scroll to the bottom and add the layer, under Custom Layers. (We don’t need pandas anymore for this script so that doesn’t need to be a layer)
- Outputting to an S3 Bucket
We need a place to output the data to. We create a bucket by going to S3 and click ‘Create bucket’, give it a name and keep all of the other options untouched, making sure all public access is blocked.
We need to amend the python script to output to that bucket:
import boto3
We need this library when working with S3.
retrieved_at = datetime.utcnow().isoformat()
date_retrieved = datetime.utcnow().date().isoformat()
s3 = boto3.client("s3")
bucket_name = "harvey-tfl-api"
file_name = f"tfl-status/{date_retrieved}/{retrieved_at}.json"
s3.put_object(Body=json.dumps(lines_info), Bucket=bucket_name, Key=file_name)
To make it easier for Snowflake and to be organised, I’ve used sub folders in the bucket so every day is a folder and each .json file is the current date and hour when it is ran.
Here is the completed script I used:
import requests import json import os import boto3 from datetime import datetime def lambda_handler(event, context): # TfL API details base_url = "https://api.tfl.gov.uk/Line/Mode/tube/Status" app_key = os.environ["app_key"] # Get from Lambda environment variables params = {"app_key": app_key} # Make API request response = requests.get(base_url, params=params) if response.status_code == 200: data = response.json() retrieved_at = datetime.utcnow().isoformat() date_retrieved = datetime.utcnow().date().isoformat() # Build list of statuses lines_info = [] for line in data: name = line.get("name", "Unknown") statuses = line.get("lineStatuses", []) status = statuses[0].get("statusSeverityDescription", "Unknown") if statuses else "No data" reason = statuses[0].get("reason", "") if statuses else "" lines_info.append({ "Line": name, "Status": status, "Reason": reason, "RetrievedAt": retrieved_at }) # Save to S3 s3 = boto3.client("s3") bucket_name = "harvey-tfl-api" file_name = f"tfl-status/{date_retrieved}/{retrieved_at}.json" s3.put_object(Body=json.dumps(lines_info), Bucket=bucket_name, Key=file_name) return { "statusCode": 200, "body": f"Saved {file_name} to S3" } else: return { "statusCode": 500, "body": f"Failed to fetch: {response.status_code}" }Deploying function trigger
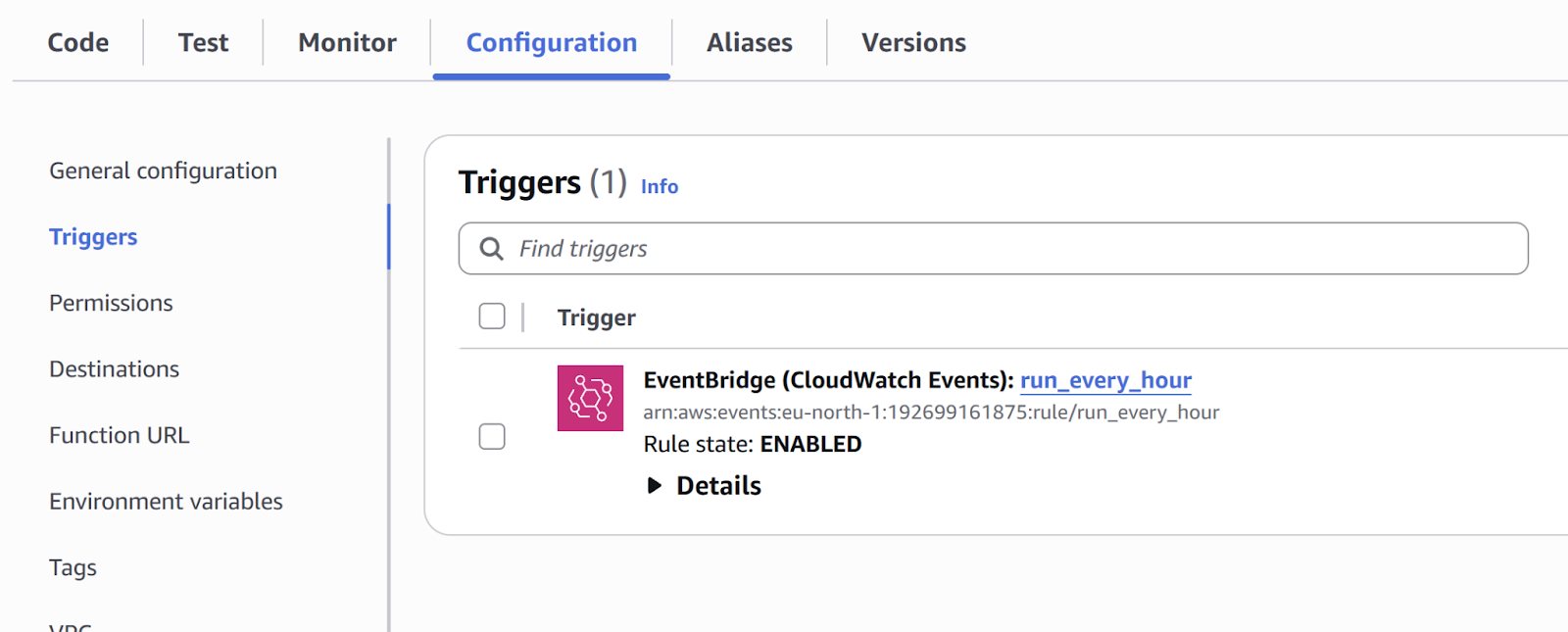
Finally we need to create a trigger so the script runs every hour. In the top search bar look for Amazon EventBridge. Under Get started, select EventBridge Rule and click ‘Create rule’.
Give it a name and for Rule type select Schedule and click ‘Continue to create rule’. Next we define a schedule, I used the cron expression to run on every hour on the dot (e.g 8:00, 9:00, 10:00) so the cron expression is cron (0 * * * ? * ). Click next.
Under select a target, we want to select Lambda function, select the function you’ve created. Click next, next again, then create rule.
Back to the function main page, in Function overview select ‘+ Add trigger’, Trigger configuration is EventBridge, click Existing rule and pick your rule. Check the Trigger is enabled under Configuration and Triggers.
To test if your function is working you can run tests here:
The next part of this blog will cover connecting the bucket to Snowflake through storage integration and setting up a procedure to collect data every hour.