


We are now fully underway with our training in DS12 and on day 3 of the Data School we got hands on with Alteryx, for many of us this was a first. We walked through the creation of several workflows with Coach Carl and Nick from DS10, one of these workflows involved cleaning up a text file and this is how it was done.
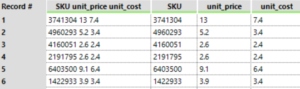
The data we started with can be seen in the image 1, Alteryx interpreted the data as seen in image 2 and we wanted the data to look like image 3, so how did we do that…

Image 1
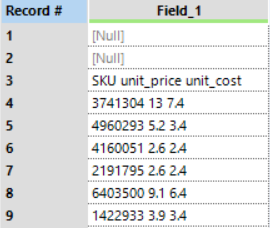
Image 2
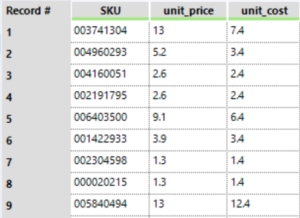
Image 3
Step 1. Use the input data tool to browse for and connect to your text file.
Step 2. Use the sample tool to remove the top two rows, by skipping the first n rows (n being two in this case).
Step 3. We then used the text to columns tool to split field_1 into three columns, using a space as the delimiter.
Step 4. Next we used dynamic rename to take the field names from the first row of data.
At this point we started to see some data that was resembled the final output.
Step 5. Use the select tool to remove the ‘SKU unit_price unit_cost’ field and change ‘unit_price’ and ‘unit_cost’ to double data types.
Step 6. Use a basic filter to remove any null values, the formula for which will look like this !IsNull([SKU])
Step 7. Finally, use a formula to add some zeros at the beginning of the SKU numbers, by selecting the SKU as the output column and using the formula PadLeft([SKU], 9, “0”).
Hit run and watch Alteryx magically turn your text file into a lovely clean piece of data as seen in image 3. What the final workflow should look like can be seen below.

Having never even seen the interface of Alteryx before the beginning of this week, let alone touching it, made me feel a little daunted at the prospect jumping straight into the software. However, with the expert guidance of Carl and Nick, I think it’s fair to say things are starting to seem a little clearer and I’m looking forward to getting fully involved in Alteryx!