


Today we had the pleasure of being taught Machine Learning by Bene and it’s honestly been one of my favourite days! It’s a topic that sounds complicated, but once again Alteryx’s drag and drop interface makes it simple.
Machine Learning can be broken down into:
- Supervised Learning – where you have a dataset to train your model on i.e. a dataset with the predictors and outcomes, broken down into:
- Regression (Predicting a measure)
- Classification (Predicting the likelihood of categorical data)
- Unsupervised Learning – where you only have predictors but not the outcomes and so you cluster your data into similar groups
Supervised Learning:
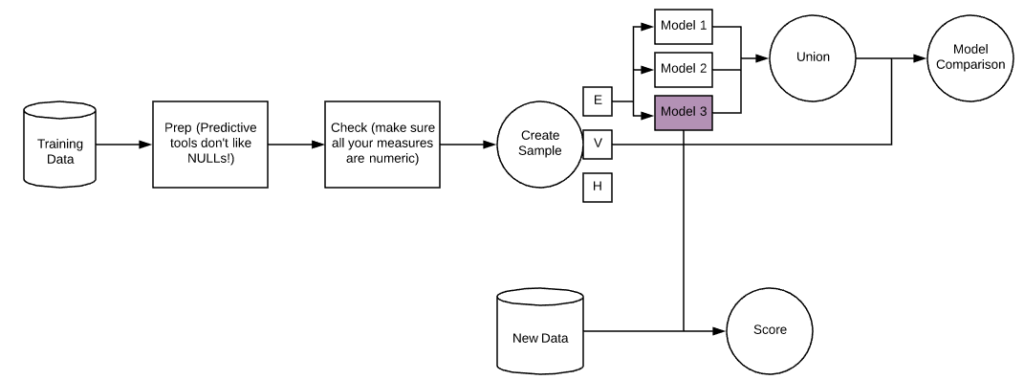
There are classic steps that you take with most supervised learning problems. First of all, you need to prep and check your training data. The important thing to remember here are that predictive tools don’t like NULLs, so you’ll have to decide whether to filter them out, or take an average, whatever works best for your data! Also it’s important to make sure Alteryx has got your data types right, so check all your measures are numeric.
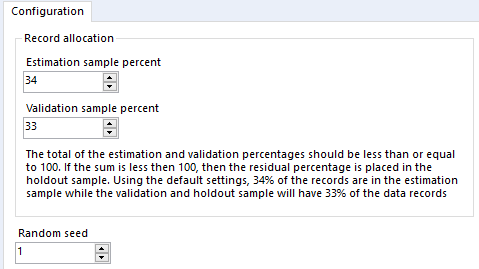

Next is the create sample tool. This tool has 3 outputs and allows you to split your data into 3 random samples. To configure, you set 2 percentages. The first will be the main chunk of your data, today we chose between 60 and 70, but basically you want quite a large proportion, as this is what you will use to train your model. The second percentage will be used to validate your model – we chose between 30 and 40 today. Any leftover percentage will go into the Hold Out anchor and the only reason you may want to have some data in here is if you have a very large dataset, so basically to make things go quicker.

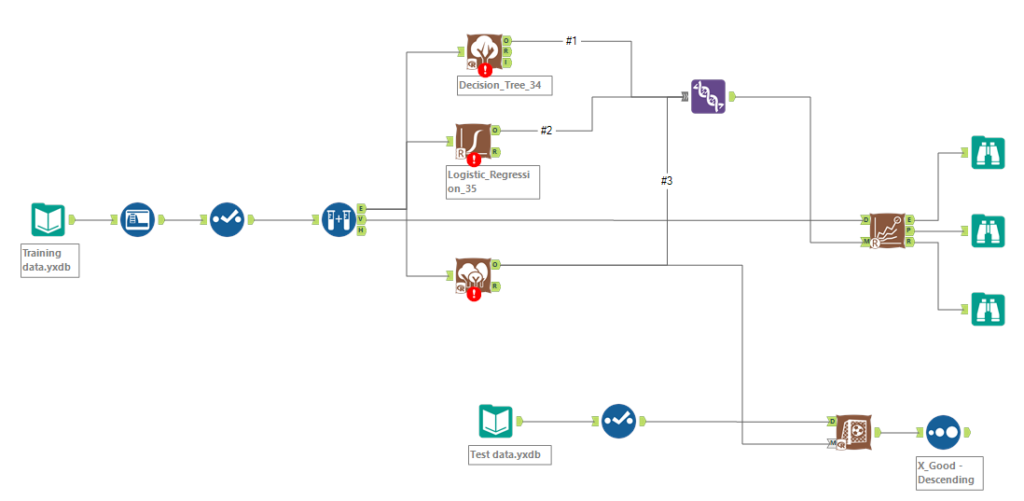
After this you will create some models. There are different types for Regression (trying to predict measures) and Classification (trying to predict categorical variables). One thing to note is that some of these tools have been updated, but others haven’t, and so to compare them you may need to downgrade them. To do this, right click on the tool, go down to “Choose Tool Version” and select the 1.0 version.

Once you’ve unioned together the outputs of these models, you will need to download the model comparison tool. Into the D input you will need to connect the V anchor from the create samples tool and you’ll connect the output of the union into the M anchor. This will tell you which model is best. This is easiest to see in the E output, the model with the highest correlation/accuracy fits the data best. In the above flow chart this was Model 3.

Finally, all that’s left to do is connect your model of choice to the dataset that has the same predictors, but no outcomes. This can be achieved using the score tool!
Unsupervised Learning:
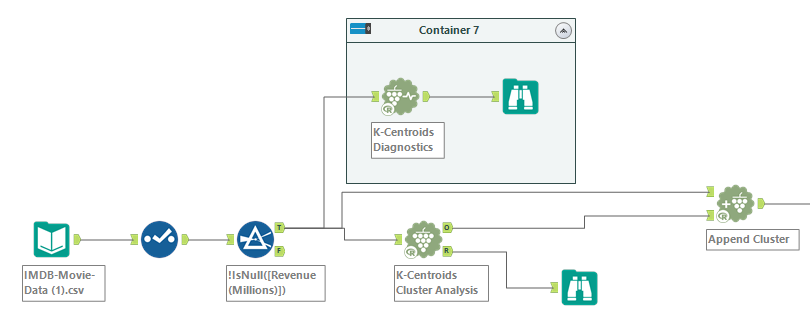
Today we mainly focused on K-mean clustering. This means the best division of data into K partitions. The way to find the optimal value for K is through the K-Centroids Diagnostics tool. A good clustering is defined as:
- Minimizing the distance between points in the same cluster and,
- Maximizing the distance between points in different clusters
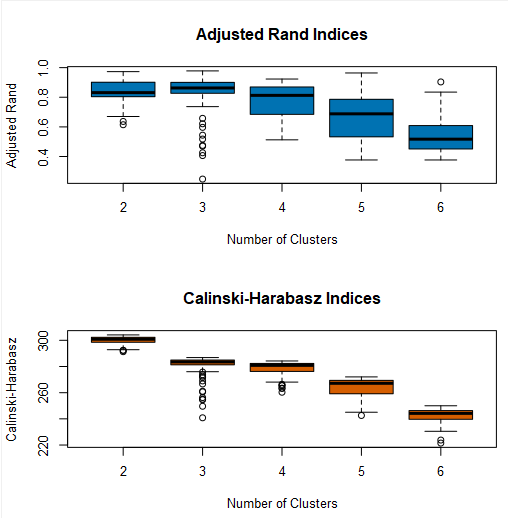
The way to decide this in the output of the K-Centroids Diagnostics tool is by having high medians for both indices, with small ranges. So in the example above, 2,3 or 4 clusters would probably be best.
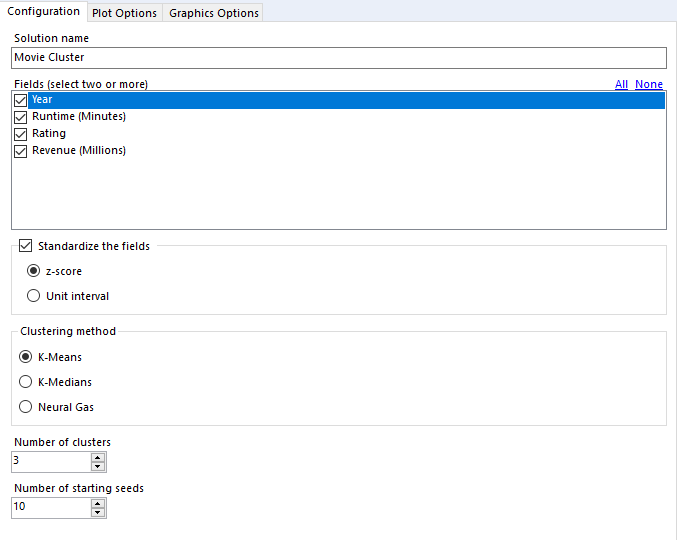
Once you have this K value, you can use the K-Centroids Cluster Analysis Tool to work out your clusters. One thing that I kept forgetting to do here was tick the “Standardize the fields” option. This makes sure that if you have some variables ranging from 0-1000 and others being between 0 and 1, they are adjusted accordingly to be considered on the same scale.
Finally all that you need to do is stick those cluster numbers onto your original data. This is done using the Append Cluster Tool.