


Recently, I attempted to build an Alteryx workflow that extracted information from Wikipedia tables. I’ll publish my workflow once it’s fully operational, but for now I’ll talk through how to turn Wikipedia tables into a usable format. Below is a guide for the general steps you need to do: I hope to have a universal solution in the near future.
It’s clear that an all-purpose tool for parsing Wikipedia is incredibly helpful to us analysts: if you’re looking to improve your visualisation skills, Wikipedia provides an inexhaustible number of topics to practise on.
However, Wikipedia is pretty difficult to work with: you could try manually copying and pasting sentences from tables, but this takes time. My answer was to build a workflow that, given a URL from any Wikipedia page, would output each table from that page as a separate data source. The workflow would have to read any Wikipedia format, work out which strings were tables, and convert the entries from that table into a Tableau-readable format.
There are five basic steps to this process.
- Use Wikipedia’s API to download the data.
Wikipedia, like many websites, makes its data available through an API: type the right thing, and you can download the entirety of a Wikipedia page.
This is the call you need in your Download tool in Alteryx (using ‘List of countries by average elevation’ as an example – simply replace this with your own URL).
What this does is perform an action (i.e. query the page specified), look at the most recent revision, get the content and format it in JSON. Use the JSON Parse tool after the Download tool in Alteryx to extract your data.
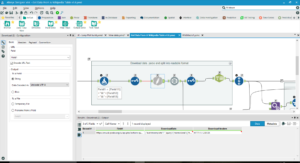
It’s complicated because Wikipedia’s API doesn’t output data in a format that can easily be read. Everything you download comes through in a single cell as HTML. Once you’ve run the workflow, you’ll see all your data scrunched up at the end of your output.

- Allow the workflow’s user to input their own URL.
Build a section of your workflow that updates the API code with the name of your URL, just as you did manually in the previous step. You’ll need a Text Box tool and an Action tool to do so.
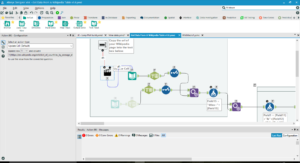
- Find the tables in the downloaded data, then assign a Table ID.
In order to get data from the tables, our workflow has to understand the way Wikipedia tables are constructed. Usually, the HTML formatting of a Wikipedia table will start with the text ‘class=wikitable’, so make your workflow recognise this text and assign Table IDs to the information beneath it.
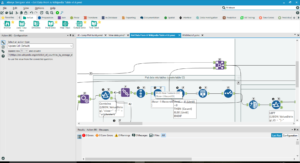
- Find the lines of each table of the data, then assign each line a Line ID.
You’ll need to do a similar process for the lines. Wikipedia uses ‘|-‘ to separate lines, so make your workflow recognise everything starting with that combination as a line, then assign a Line ID.
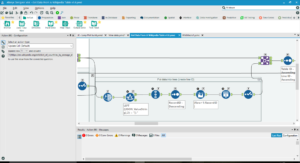
- If there are multiple entries within one cell of the table, assign them separate Line IDs.
This may be the longest section of the workflow. Some cells on a Wikipedia page may have multiple entries: for example, if the page gives winners of a specific competition by year, some years might have multiple winners, in which case there will be multiple entries in the cell for that year. My workflow creates multiple lines for each cell with multiple entries, then uses an iterative macro to sort the lines into the right order. Give each entry another ID based on its order in the line.
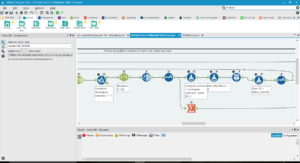
- Find the table headers and make them field names.
Next, work out which formatting turns something into a header: usually, lines beginning with ‘!’ will be column headers. Find each column header and assign it to the correct entries (make sure you’ve sorted the headers and the entries into the same order, then join on their order in the line).
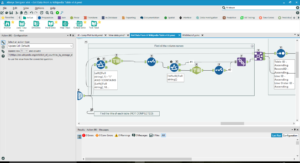
- Clean the data.
There will be a lot of formatting still in the data. Clean thse with Text-to-Columns and RegEx.
- Get Alteryx to output each table as a separate file.
Finally, use an iterative macro to cross-tab each table and save it in your directory, then do the same for your next file with a different table name.
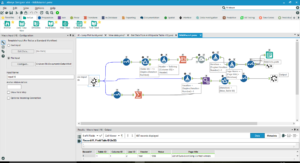
Watch out for a future post with the fully-functional workflow for downloading Wikipedia tables.