


This blog outlines how to use webscrapping in Alteryx to find Groupon's top things to do. Below there is an overview of the workflow developed:

Step 1: Decide how many pages from the website you want to analyse
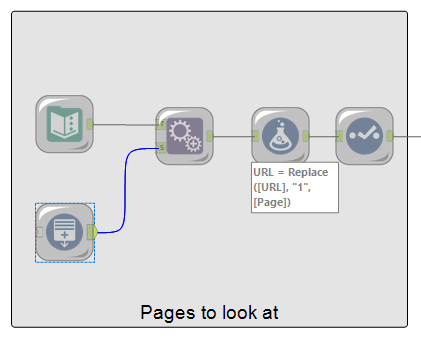
In this first step, the URL of Groupon's top things to do webpage was added in a text input tool. A generate rows tool was used to create rows from 1 to 10 to represent the pages to look at. Both outputs were appended together and a formula tool was used to replace Groupon's base url with the corresponding page (e.g. for page 8, replace https://www.groupon.co.uk/browse/london?category=things-to-do&page=1 with https://www.groupon.co.uk/browse/london?category=things-to-do&page=8).
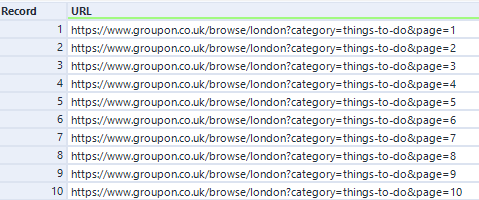
See outcome below:
Step 2: Download HTML
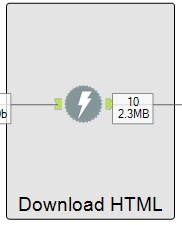
Use Alteryx download tool to download the HTML for each record. You do not need to configure this tool, but it is recommended to cache and run from this point to avoid refreshing the page every time that the workflow is run.
Note: You may not always get the entire HTML code if the webpage does not load the entire HTML code in time after the page is first refreshed. This might be due to JavaScript code in the back which triggers the HTML to load on the page after a certain event is initialised or called. Sometimes you may even have to adjust the throttle records in the connection tab (or use a throttle tool) to define the number of rows per minute that can pass to downstream tools (e.g. if the throttle is 60 rows per minute, at this rate, 10 records in this example will pass through the tool in about 10 seconds).
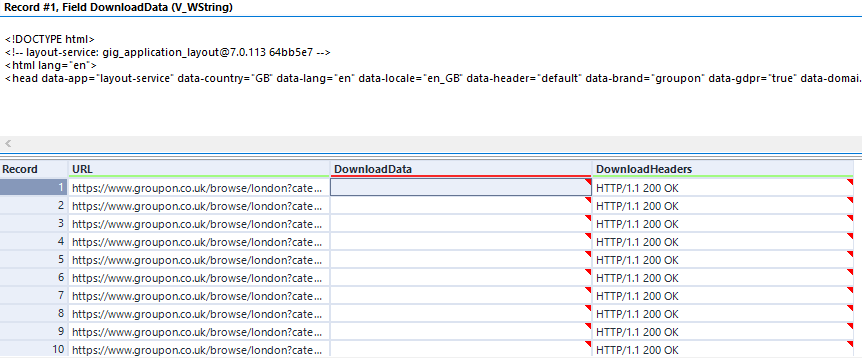
See outcome below:
Step 3: Clean the data
Deselect the fields that you do not need and clean the data (in this case the HTML code from DownloadData field) to remove leading or trailing spaces, line breaks or nulls if any.
Step 4: RegEx and parse desired data values

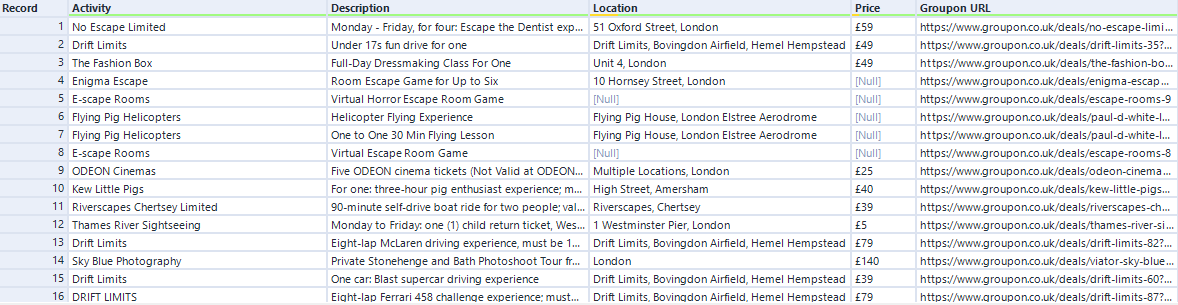
In this example, since we want to visualise the top activities from Groupon's top things to do first 10 pages, we need to select and only display the data values that we are interested in. The first unlabelled RegEx tool is used to tokenize the data which contains these values of interest from the HTML code. The rest of the RegEx tools are used to parse these values of interest (e.g. activity, description, location, price and the link to the deal as shown in the image above).
Note: There might be more than one way of doing this step. Feel free to try different alternatives or improve your RegEx skills following this example.
See outcome below:
Step 5: Clean and output the data
Clean and output the data to obtain the results outline in the last image from the previous steps. Filter out the nulls, remove trailing and leading spaces, deselect undesired fields and lastly use an output tool to output the data in a desired format (e.g. csv, xls, hyper, etc.)