


Here’s something which might help you if you’ve ever needed to download a load of URLs which are only accessible if you are logged in.
Normally, webscraping with Alteryx is pretty simple – you connect a text input containing the URL to a Download tool and parse out the DownloadData column returned. For example:
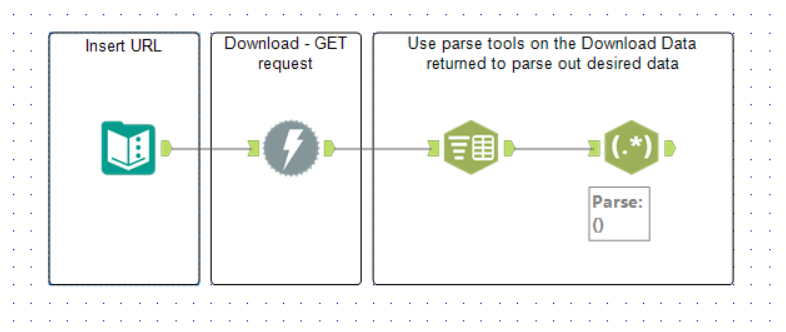
However, if you try to scrape a website which looks different when you are logged in, this straight forward method will not work as it will not treat you as someone who has logged in; it will only download the webpage accessible to everyone.
To understand how your browser works so you can replicate the logging-in and subsequent accessing of webpages, the Inspect feature (ctrl-shift-i) in Chrome is king. The Network tab will record your browser’s network activity in real time as you access webpages.
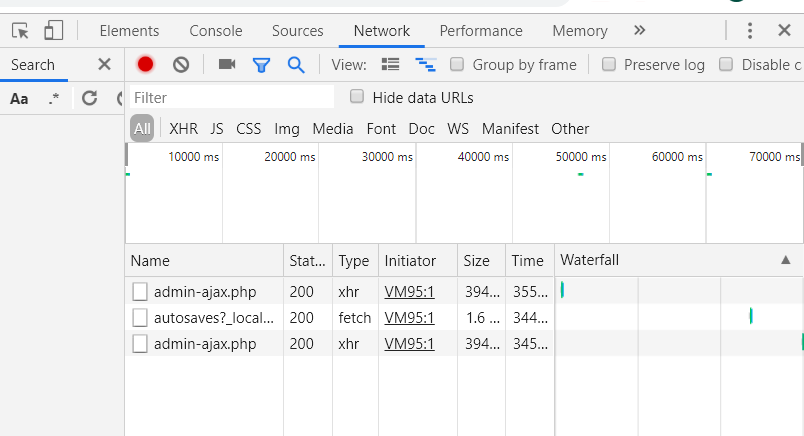
Importantly, it will detail the requests which are made from your browser, the responses from the given website and the order in which the events happen.
Your web browser uses HTTP requests to make things happen. The client (web browser) requests something from the server (behind the website) returns a response to the client.
There are several different types of requests, but I am going to focus on POST and GET.
POST requests are used to upload data to a server to create/update a resource.
GET requests are used to download data from a server.
GET requests are responsible for the web pages which are returned to you for you to interact with. For example, you can see below that GET requests resulted in the BBC homepage rendering when I clicked on its URL.
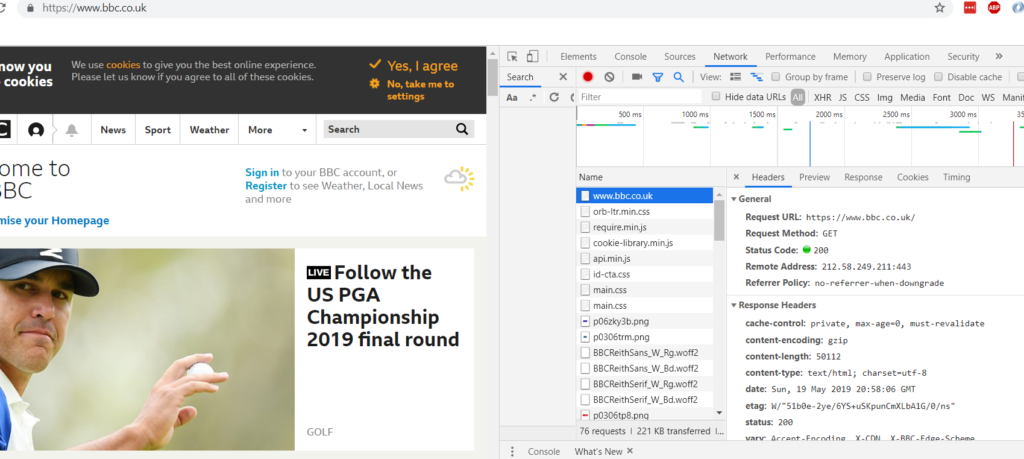
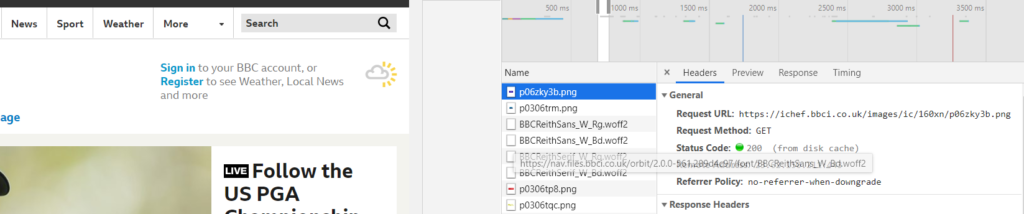
Note that not all of the actions recorded in Inspect may be relevant to you – e.g. some may be adverts – so you need to use some common sense to figure out which are.
Now, if you monitor via Inspect what happens when you log in to a website, you will see a different cascade of events…
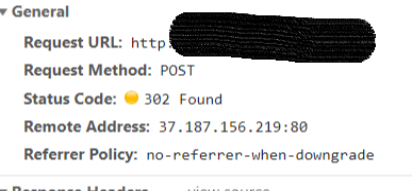
A POST request is sent to post your login details to the server and in turn can respond and give you full access to the site.
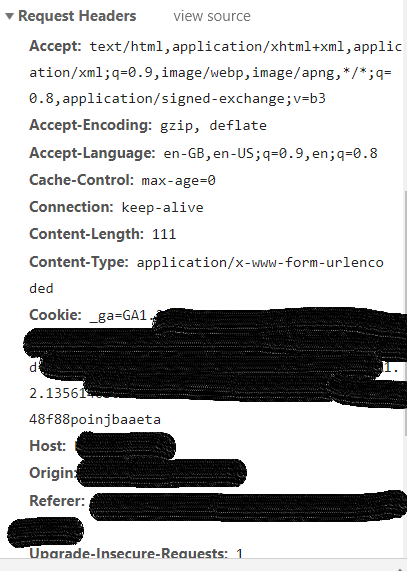
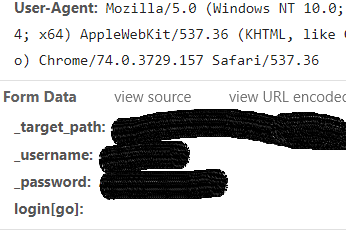
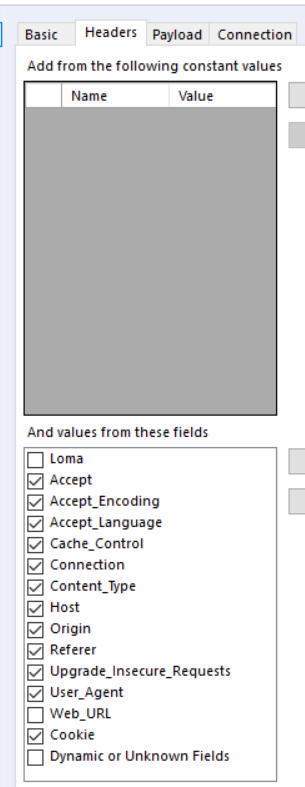
You need to be able to recreate this request in Alteryx. Luckily, you can! The first step is copying all of the Request Headers with the Headers tab of the Download tool.
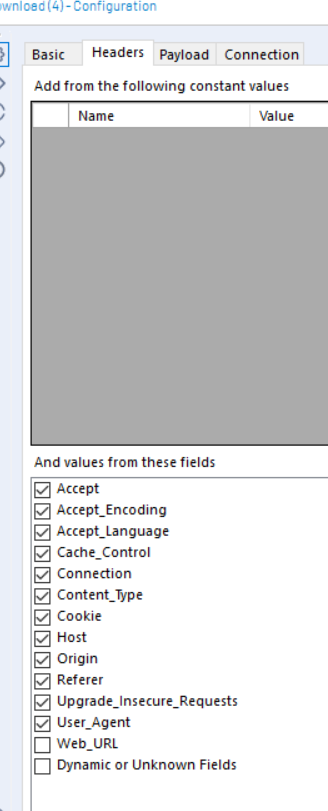
Second, make sure the Download tool is set to send a POST HTTP action. Third, recreate the form data sent by your web browser when you login.
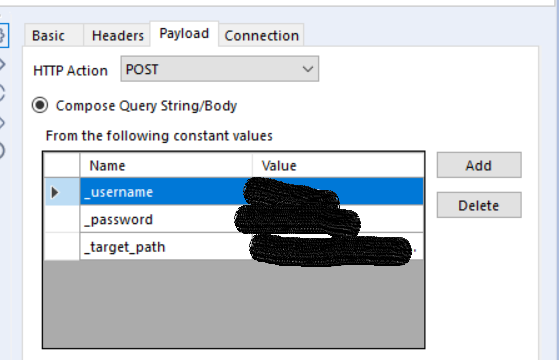
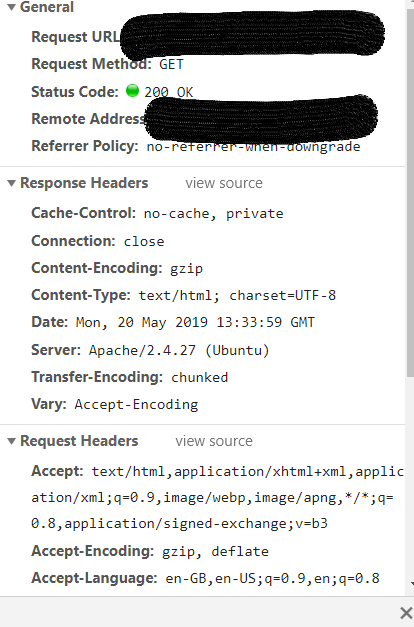
The server will respond to this login request, as can be seen in Inspect:
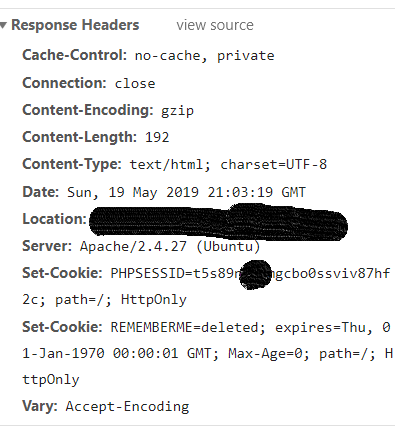
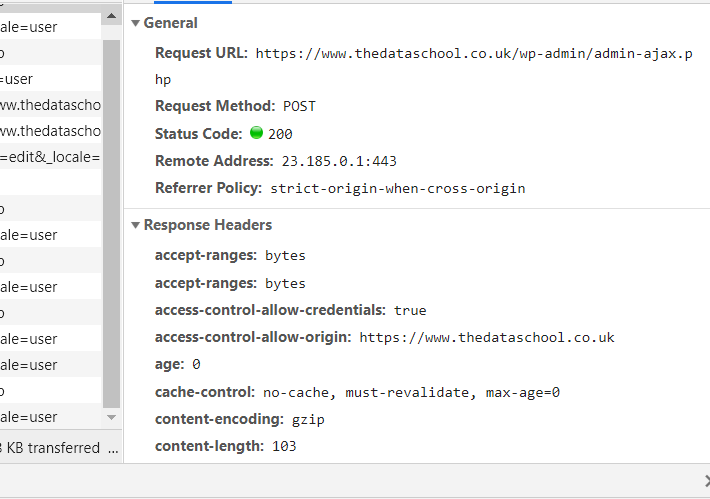
The response is accompanied by a series of Headers, each consisting of a Key and Value, which provide contextual info about the response (see above).
In Alteryx, the Headers will be in a separate column to the body of the response – see below.

The website’s ability to remember your client is logged in is critical to successfully webscraping a login-only site.
You may notice that there is a ‘Set-Cookie’ header returned when you login.
Look at the value for Set-Cookie received when you login via Inspect, keep recording and then click on a different webpage (while logged in). You will notice that the Set-Cookie value (received in Response Headers in the login POST request) is being used in Request Headers for the following loading of webpages.
Why?
Cookies are messages stored by your client which help websites remember you and also remember whether you are logged in or not. So this Set-Cookie you receive from logging in is effectively a token you receive which prove you are logged in.
By extracting the Value accompanying the ‘Set-Cookie’ Header from the first Download tool, you can use a second Download tool, with whatever HTTP action you want, which uses this cookie in the Headers tab. This second Download tool will appear as a logged in client to the server due to showing this cookie.
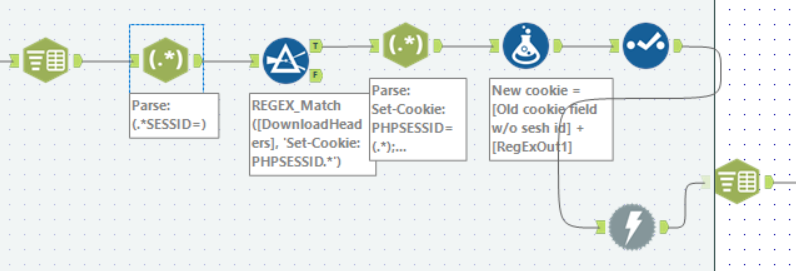
This is how I parsed the Set-Cookie in DownloadHeaders from the first Download tool. In short, I used Text-to-Columns to separate out the DownloadHeaders field with ‘\n’ as a delimiter, regex to filter only the row with Set-Cookie and then used a Formula tool to replace the old Cookie value with the Set-Cookie value.
Now, the second Download is configured with the updated Cookie field.
Like for the initial login stage, using Inspect is great for configuring the second Download to mimick viewing a webpage while logged in.
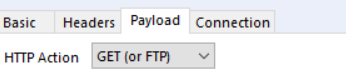
As you can see above, in this case it is a GET request, so to replicate the process in Alteryx you need to configure the second Download to GET:
You also need to copy the Request Headers used in the HTTP action your web browser uses (e.g. User-Agent – this is used to trick the server into treating your Alteryx the same as a web browser).
With the login cookie received from the initial login POST action and the correct Request Headers, the second Download tool will now correctly webscrape the pages specified as if it’s a logged in web browser.
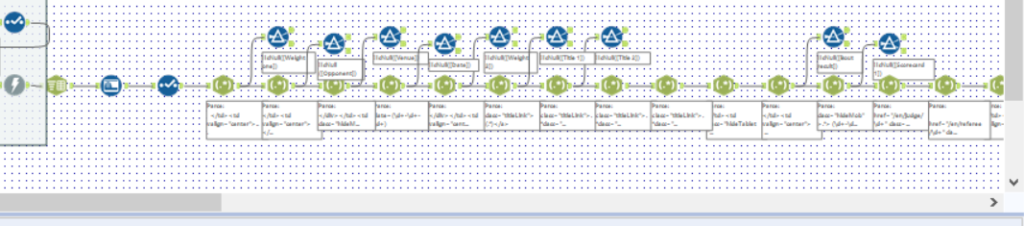
You are then free to parse out the data from the second Download tool to your heart’s desire!