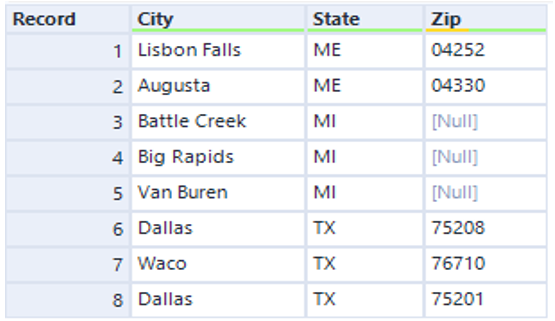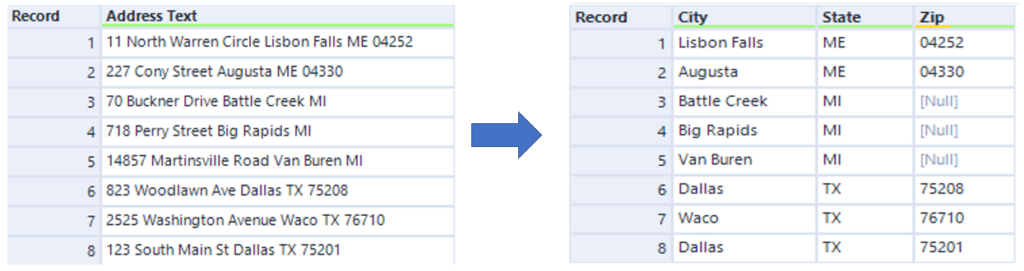
This week DS21 have been focusing on Alteryx, looking at several different topics across the week, we spent Wednesday learning the basics of Regex with Oliver Clarke, and today we were tasked with completing one of the Alteryx weekly challenges that required Regex. Week 54 is about parsing awkwardly formatted addresses, it is a small data set of addresses, as seen above with the aim of separating the addresses out into the City, State code and Zip.
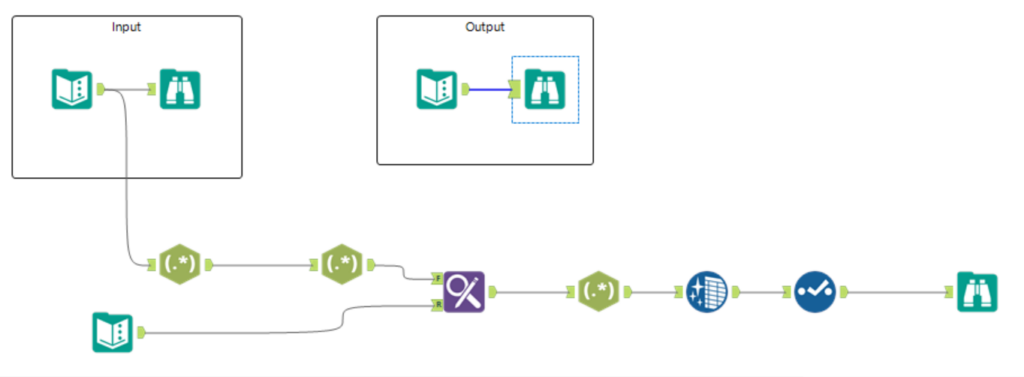
Separating the State code and the Zip code were both relatively simple as they had a standard format that was different to everything else within the address.
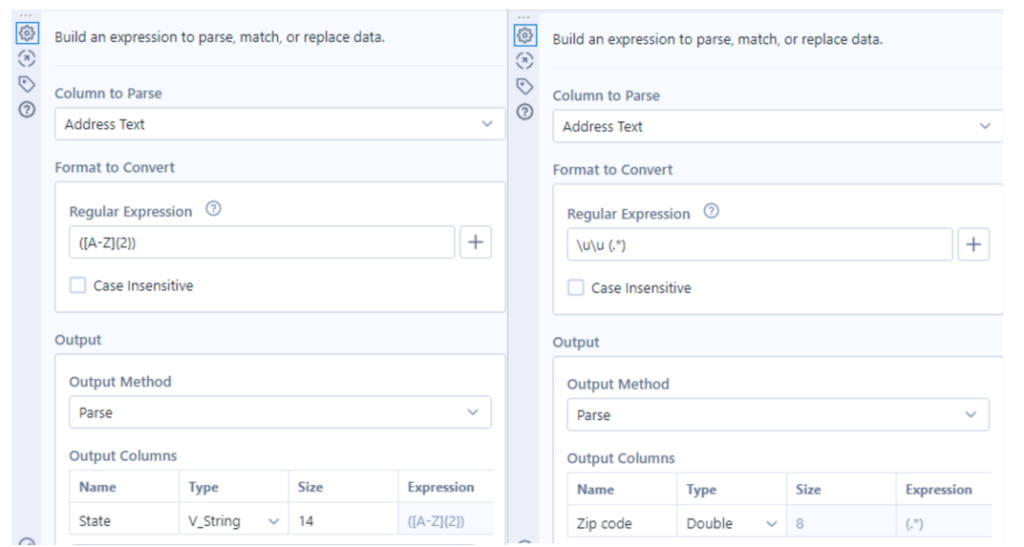
The State code could be parsed out using ([A-Z]{2}) as it had two consecutive capitals; I did spent a while wondering why this was not working only to realise I still had case insensitive checked, but apart from that it was pretty simple. The zip code, if there was one, always came after the state code and so I used \u\u (.*) which takes everything after the capital letters of the state code, in hindsight i could have just specified take the 5 digits.
The city was a bit trickier, as I couldn’t spot a pattern in the name of the city or the text before or after the city name. So after taking a peak in the responses to the challenge I realised that the way to do it was to use the street names. The city name always came after the street name, so if you replaced all the options of street names, (drive, avenue, road etc) with a common factor you could use that to parse after. I replaced the road suffix with a | and then used the expressions |\s(.*)\u\u to parse everything between the | and the state code, as some of the cities were two words.
It was then just a case of cleansing the data and selecting which columns to be outputted.