


Day 2 down.
Yesterday definitely gave me a false confidence, such a tough one today. We have never been taught how to bring PDFs into Alteryx, but that was exactly what the challenge was today!
It was in truth a great experience that I know will serve me fantastically well going forward. Essentially PDF parsing requires alot of RegEx, which we have been taught and utilised for a while now. We were using Diamond League Data and the greatest challenge was the fact the tables within the PDF were structured differently per event.
First we were told to follow a blog post, and had to download R and follow some seemingly simple steps to import our PDFs into Alteryx. However, even this took a remarkable amount of time to work out, squeezing the rest of the day.
My workflow is essentially a lot of parsing tools (RegEx & Text to Columns) with filters and select tools scattered across the canvas. It really isn’t the prettiest but it gets the job done!
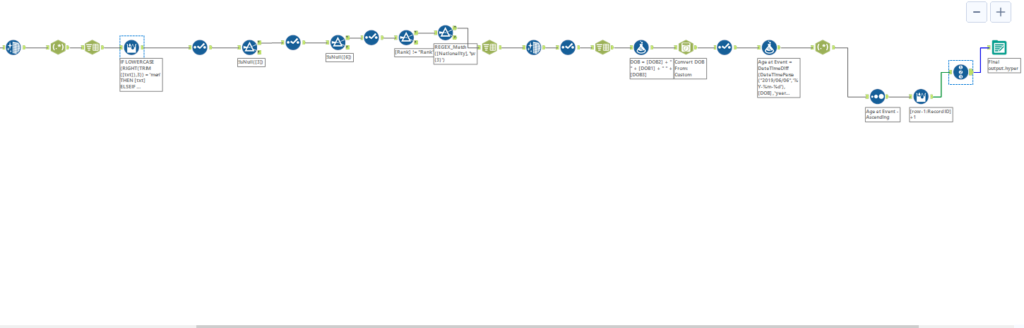
I decided early on that I wanted to look at the age distribution across the meetup, when noticing how young some of the competitors were. I remembered a viz I had seen that looked at Instagram selfie age distribution that I really liked the look of and thought I would have a crack at something similar.
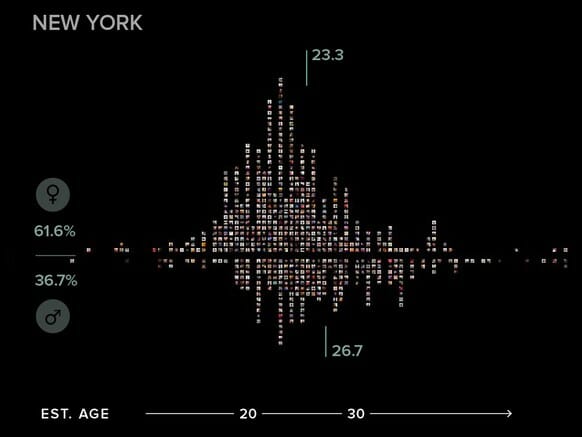
The viz is below, and see the article for it here. It is written by Liz Stinson from Wired.com.
My viz is below, the the interactive version here:
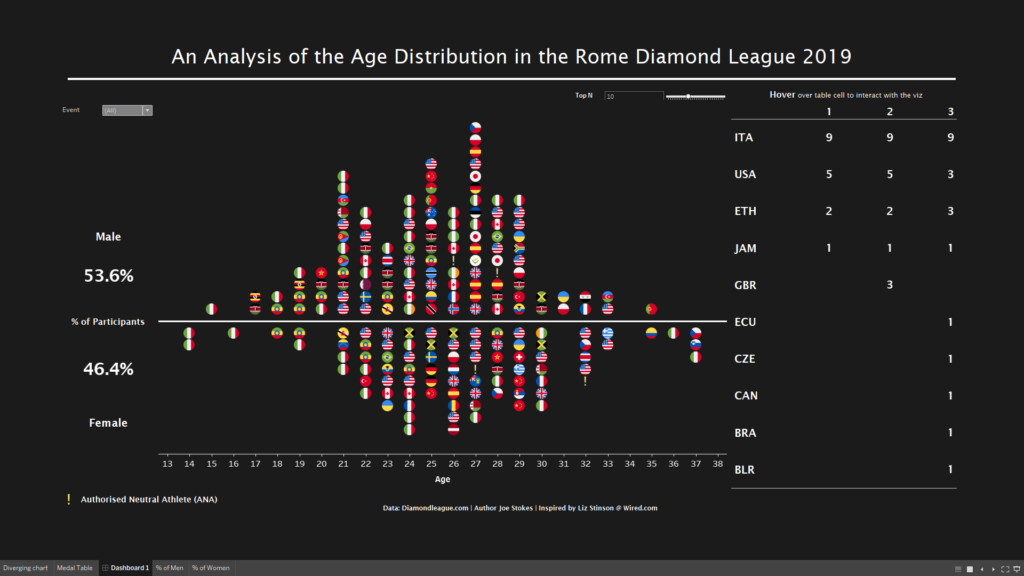
Overall, I was pleased enough with the final product. The actual data after hours of prepping was actually quite limiting. I struggled for a while to decide on a direction for the viz and overall am pleased I managed to pull it together!
I am shadowing tomorrow so back in Thursday for day 4!