


ast week at the Data School, we were introduced to RegEx, macros and learnt more about tranpose, crosstab and multirow on Alteryx. By the end of the week, I was able to put all of those things to use for our friday project, which was to analyse data from the UK Parliament petitions.
The dataset I used at the time was not as complete as I had hoped and so I set out to compile my own dataset. In this post, I'll be going over my process of creating this dataset and how I visualised it.
Making the macro

All the fields in Figure a. are obtained from a json format. For example, the json file of this page can be accessed near the bottom of the website page. The json link is then used in Alteryx to extract all the required data.
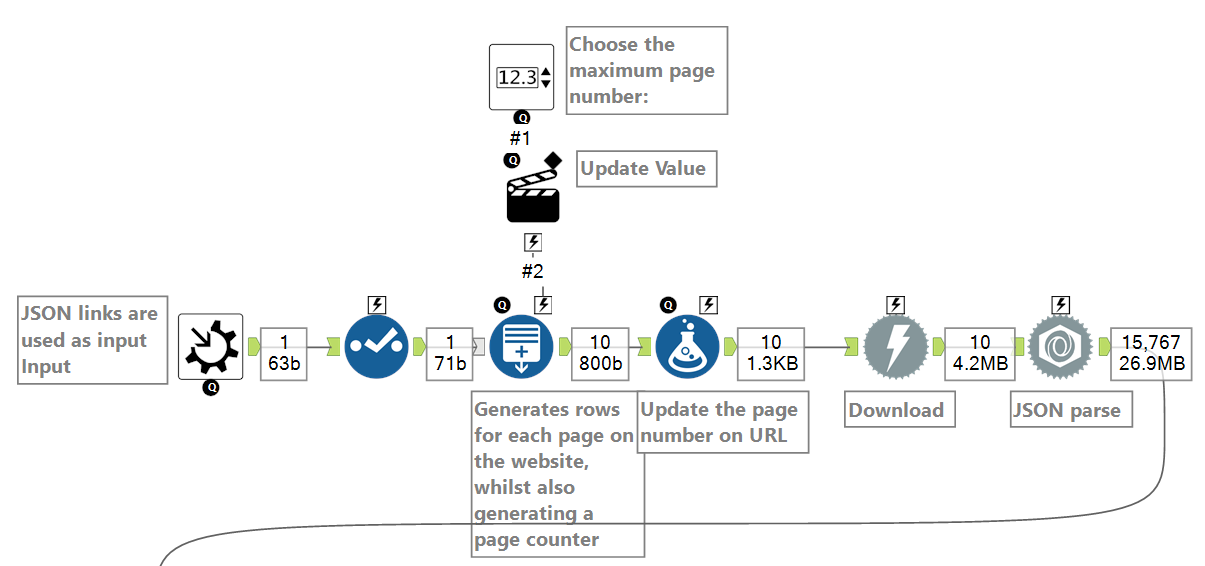
Generating entries for additional json links
The input required in the macro is a single entry of a json link: https://petition.parliament.uk/petitions.json?page=1&state=open for example, which corresponds to the first page of all current open petitions. However, this link will allow me to retrieve data only from the petitions on this page (each page holds up to a maximum of 50 petitions). So if I wanted the data of all currently open petitions, I would have to parse the json data from each page (which is 50 pages at the time of writing). To save myself the trouble of manually typing out a row for each page, I used the generate rows, formula tool and RegEx to do it for me (figure c.).
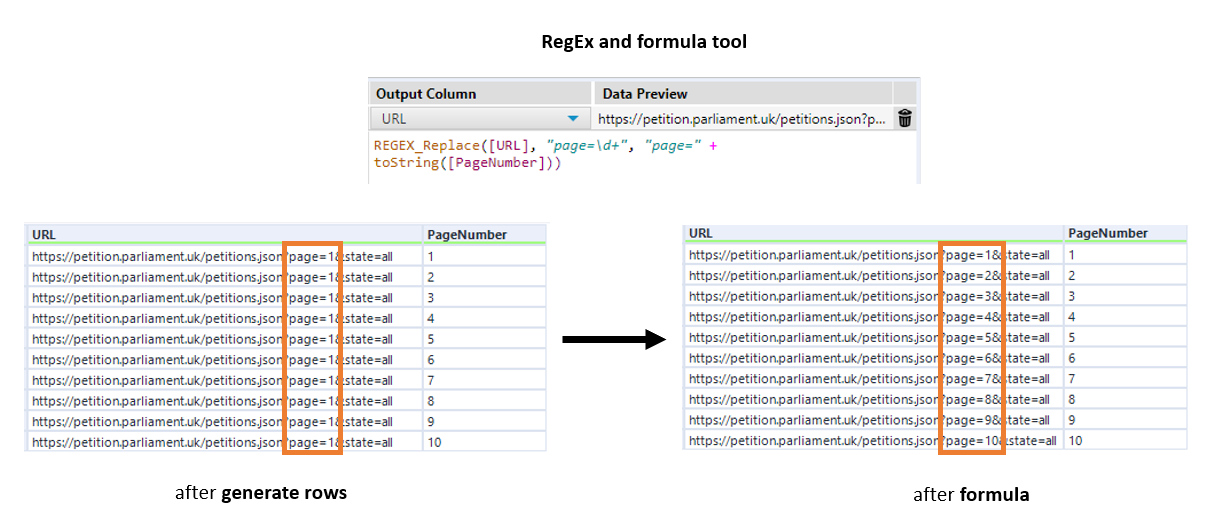
Through the numeric up down interface tool (figure b), the user can choose the maximum page number to parse (ie. how many pages to parse, starting from page 1). This number is used by the generate rows tool to determine how many rows to create, which in turn determines the number of pages. The PageNumber field was created using the generate rows tool. The formula tool and RegEx are then used to replace page number of the json links with the values contained in the PageNumber field.
After the required number of rows (pages) are created, each json link is then parsed using the download and json parse tools.
Creating a unique ID to group by before using the CrossTab tool

Another problem was that I had no unique field to group by with for a subsequent crosstab. Each petition on a single page is labelled from 0 to 49 on the json (figure d.), which is sufficient if we're only parsing a single page. But when parsing multiple pages, these labels are no longer unique, so to solve this I concatenated the page number to the data number (step 2 and 3 in figure e.).

CrossTab and Cleanup
Using the unique ID I created, I then used crosstab to change each petition attribute into columns – populated by their values for each petition. And after several cleaning steps, I was able to achieve the dataset structure shown in figure a.
Using the macro
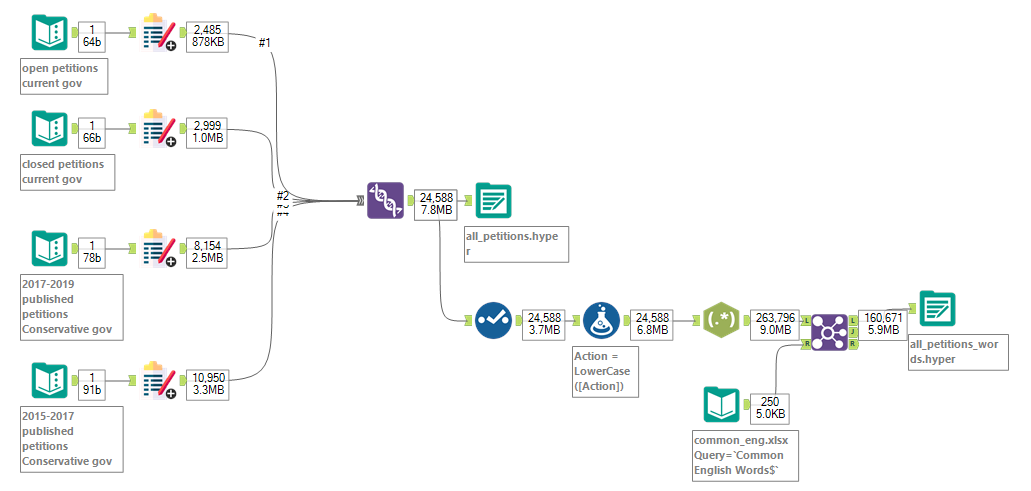
In the figure above we can see the four text inputs and each contain a single json link of the following petition pages:
- current government open petitions (50 pages max at the time of writing)
- current government closed petitions (61 pages)
- 2017-2019 government: published petitions (164 pages)
- 2015-2017 government: published petitions (219 pages)
Each text input then uses the macro and within the interface, I chose to parse maximum number of pages for each. Then I used union to merge all four outputs.
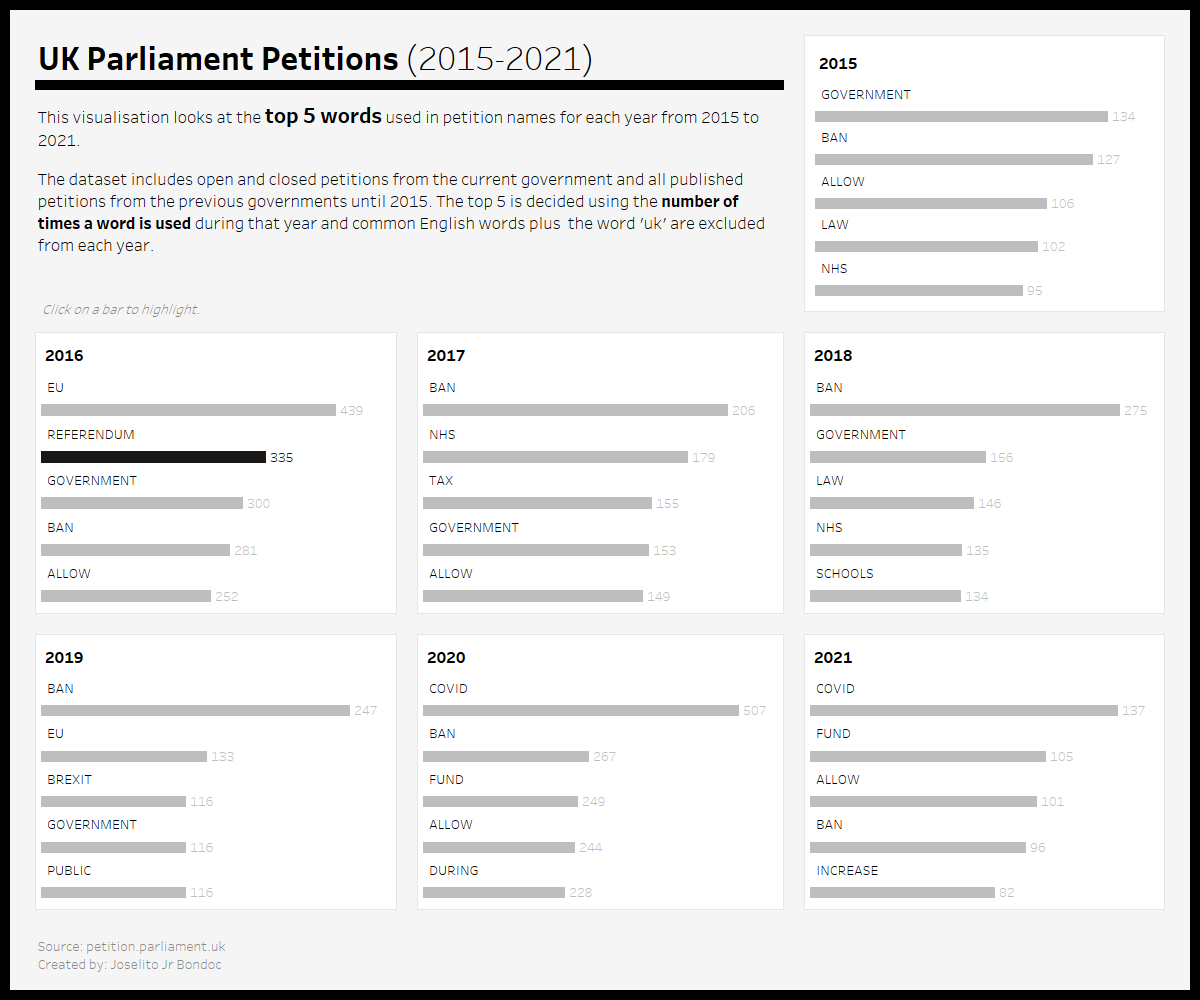
Processing the dataset to find the most common words
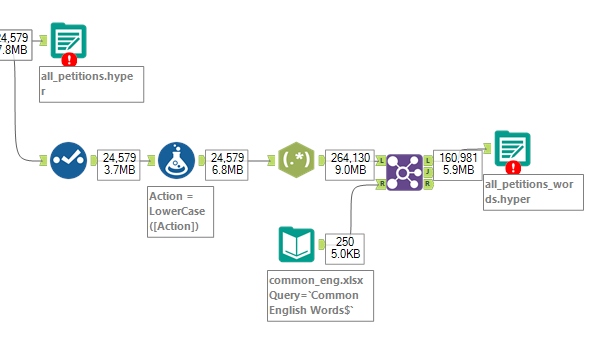
My friday project was inspired by Preppin' Data 2019 Week 9, which used a dataset of common English words to remove those common words from tweets. The idea that I had was to use this same method to find the most common words used in petition labels.

The first step was to change the petition labels to lower case because the common English words dataset was in lower case. Then I used the RegEx tool to tokenise the petition labels using the expression "[a-z]+", which will match each word in the petitions regardless of spelling (removing whitespaces, punctuations and numbers). A row will be created for each word matched. I then joined this dataset to the common English words dataset and kept the left-only records (because these are the words in the petitions that aren't common).
Further improvements
- Don't count a word multiple times if it was used more than once in a single petition name
- Take into account mispelling of words, for example by using grouping in Tableau Prep Builder
- In the viz, retain context of each word in the top five regardless of the year. For example, 'referendum' was top 2 in 2016 but where was it during other years?
Thumbnail photo by Jannes Van den wouwer on Unsplash.