


Recently, we’ve been exploring data modelling techniques and how relationships help describe how dimension and fact tables can communicate with each other. Below I’ll use a star schema example to help demonstrate data modelling in action.
This example looks at a store that could have the following tables:
- Sales Data (Fact table)
- Product Information (Dimension table)
- Account Manager Information (Dimension table)
- Store (Dimension table)
- Customer Details (Dimension table)
Fact tables store the quantitative, numeric measurements of business events, while dimension tables often store the descriptive attributes. Here is the current layout.
Diagram created in DrawSQL.

For a star schema, the fact table sits in the middle with the dimension tables connecting around it. Dimension tables are linked through primary and foreign keys, which have relationships for how they link. For example:
Customer key is a primary key in the customer details table, whereas it is a foreign key in the sales data table. The Customer details[Customer Key] has a one-to-many relationship with the Sales data[Customer Key]. This means that a customer key, a random example being FA20987, will appear once in the Customer details table and then many times in the Sales Data table. Intuitively, this makes sense as a particular customer may have many purchases at the store, explaining how a customer key could occur many times in the sales data.
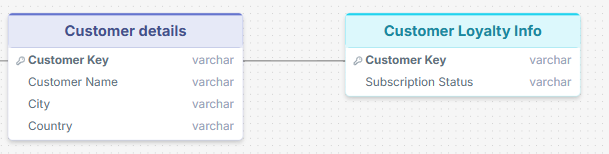
Below is now an extension of the schema:

This additional table Customer Loyalty Info[Customer Key] now has a one-to-one relationship with the Customer details[Customer Key]. Using customer FA20987 again, this customer will appear once in the Customer Details table and, at most, once in the Customer Loyalty Info table.
Relationships and data schemas provide a structured framework for organising and connecting data. Importantly, together they help enforce data integrity.