


There are many ways to retrieve data from the web, one way is using the download tool in alteryx. Other ways which might be simpler are using python, google sheets or online resources which will webs crape for you. One more thing before we get into things, it's important to remember whether you are scraping public data or not :o!
You will first want to identify what you want to scrape! To do this right click anywhere on the web page and select inspect. This will open the HTML code in which you can find where the needed information is.
Now we can copy the URL and place it in a text input tool in alteryx. Then we can use the download tool retrieve what is in the website. You will then have all your HTML code in a single cell. The best way to extract specific information is using Regex. You first will want to use the tokenize function in the regex tool to create a new row for every time you see what belongs in your field. For example when web scraping information about books you can use to tokenize tool to get a new row for each book title. I recommend using a text editor that identifies HTML code and colours specific portions in different colours to help you choose your regex expression. Here is an example where I retrieve the price of a book using regex from the HTML code.
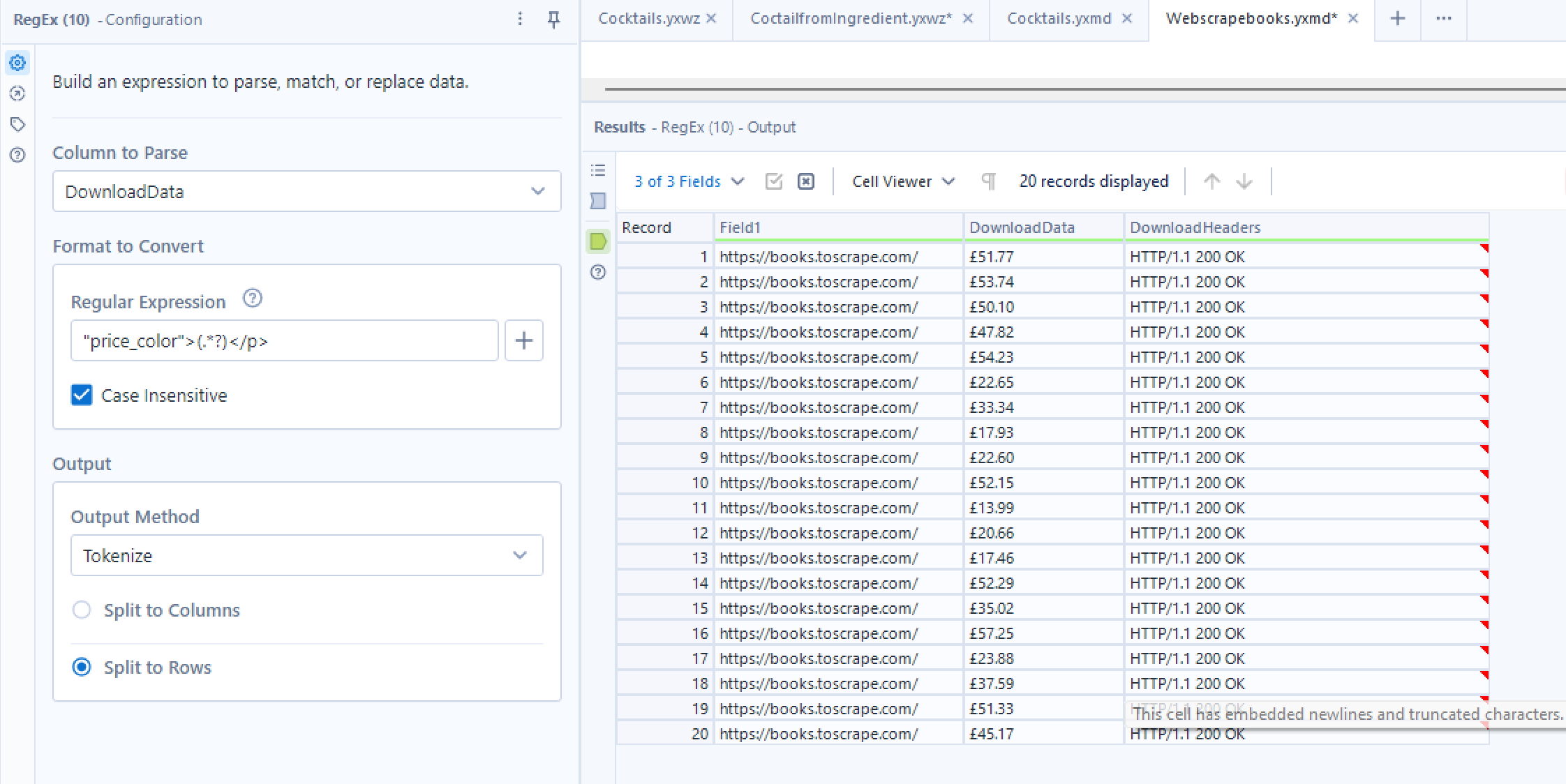
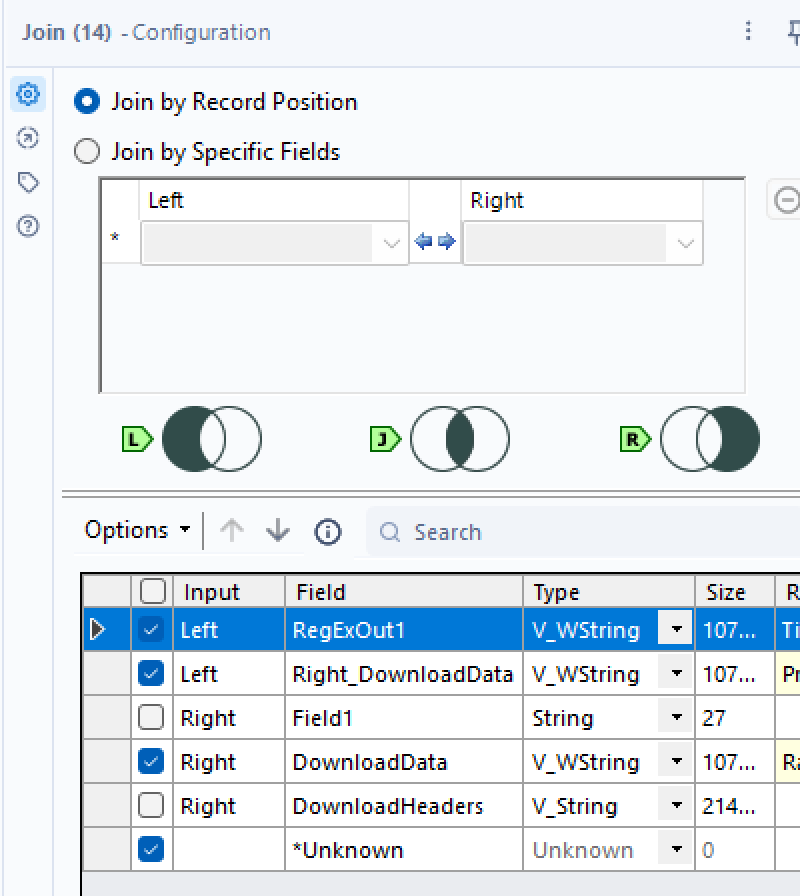
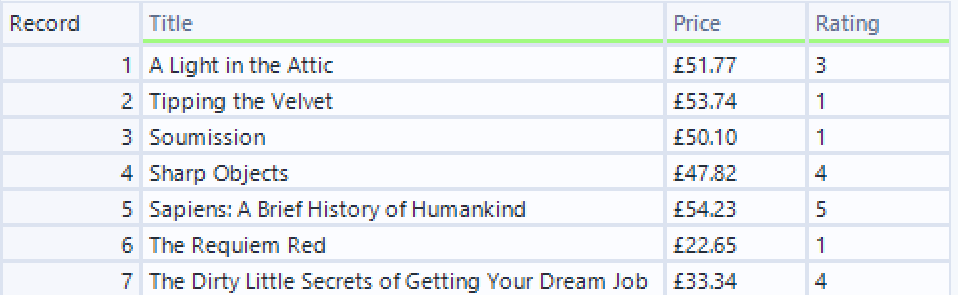
As HTML is always written top to bottom, you will be able to then join multiple fields based on their record positions. So we can link this price to any other information about the specific book this price matches.
If you want to webscrape from multiple pages which are the same. You can simple add new URLs in a different row of your first text input tool.
All the best in your scraping!