


Today marked the start of Dashboard Week. Andy called in and gave us our brief- this challenge intended to refresh our API knowledge. The API would be taken from FOAAS.com. For those unacquainted with FOAAS, F*ck Off As A Service provides a “modern, restful, scalable solution to the common problem of telling people to f*ck off”. I.e. it generates profane insults to a person of your choosing.
At first, this seemed like an unusual dataset to attempt to visualise because… there was no obvious data- just a collection of words. Nevertheless, we set about finding the API we needed. The website offered a few options, we soon realised the ‘operation’ API was the one we were after:
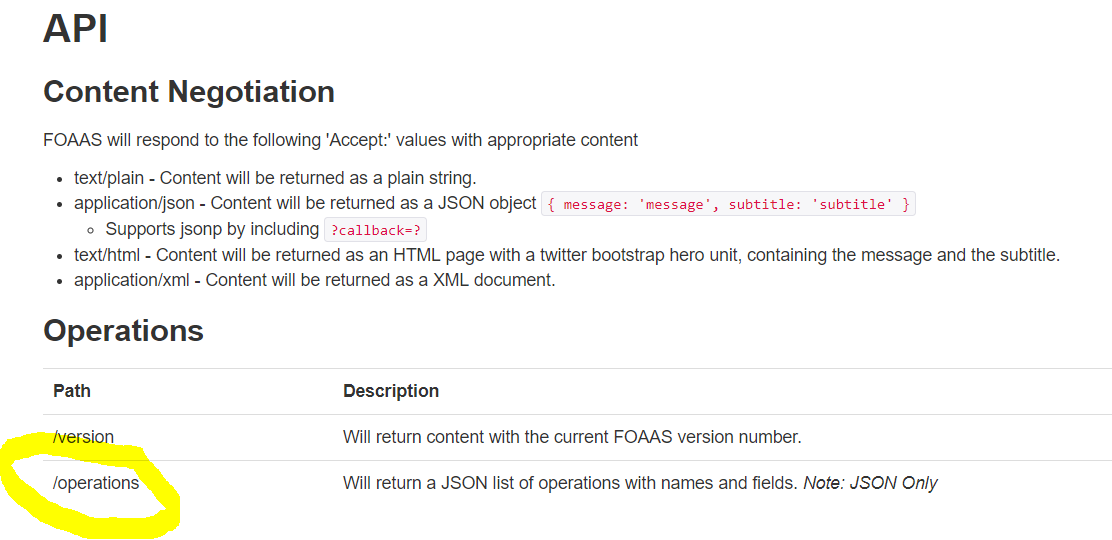
Using the Download tool, we imported the data from the API and filtered to only the rows which contained sections of URL using the Filter tool and only including rows with the phrase ‘url” (I have censored some of the words in the data below).
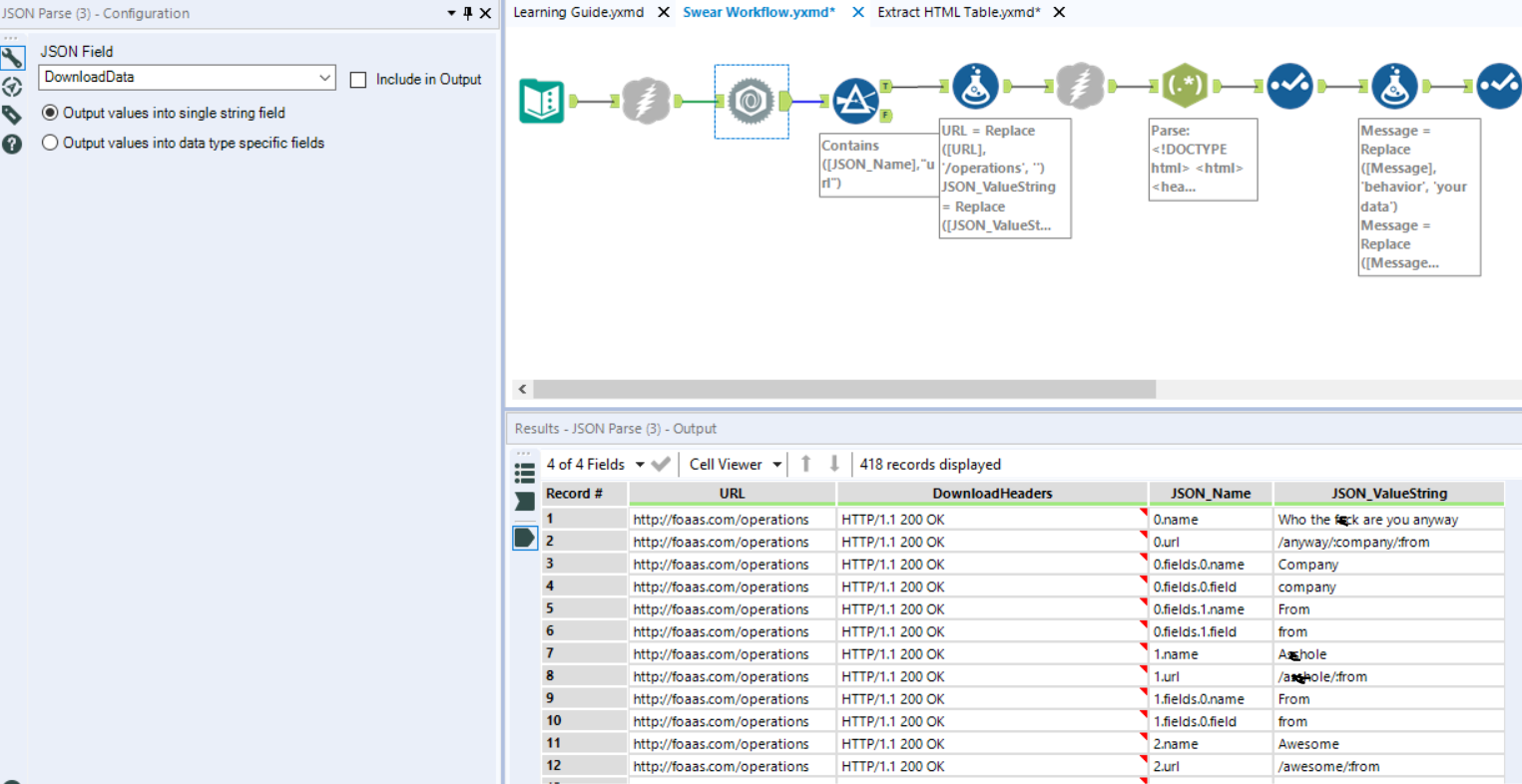
So, I used the Formula tool a LOT in this workflow. The first use was to customise the data- change words like ‘name’ to ‘Kirsty Fraser’ for example. Most importantly, using this tool I could put URLs into a form where the API information could be downloaded. This involved removing ‘/operations’ from every original link in the URL column and replacing it with the URLs we filtered to in the new [JSON_ValueString] column.
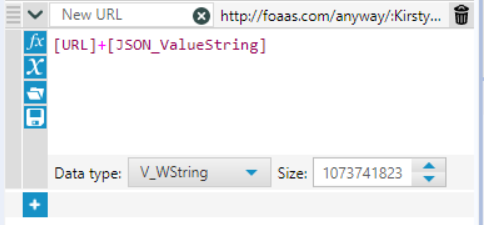
At last! I had a column of APIs which could produce the required information! I then used the download tool to import this data.
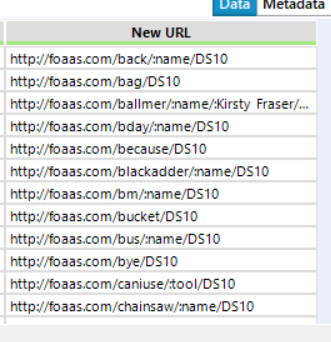
Unfortunately, this produced a rather messy-looking column with lots of unnecessary data which I didn’t need:
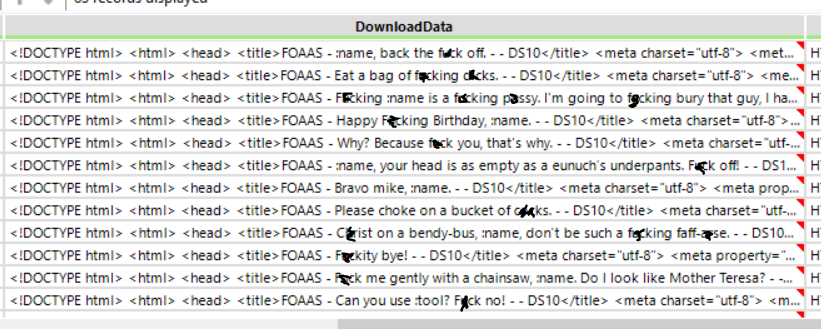
Using the parse tool, I isolated the profane statements I was after and got rid of all the other data. The highlighted (.*.) below represents the sentences which I was interested in separating off.
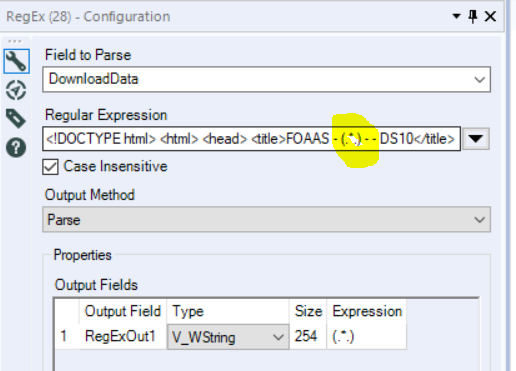
The next few tools in the workflow focus on cleaning the data and customising it further. Also, since my dashboard will be visible to the public, I decided to add in some censorship were necessary using a few choice *s.
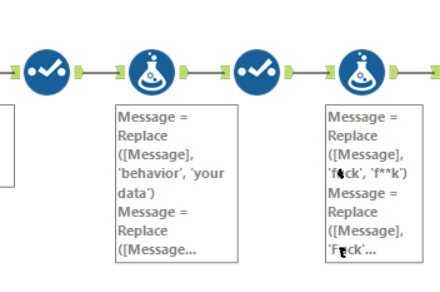
For my final viz, I wished to count the various words used in this collection. To do this, I parsed out the words in each message by the spaces between them.
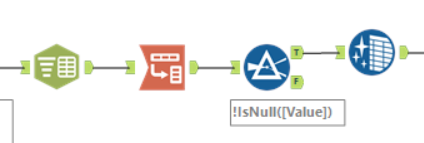
I then transposed these words to that they were in one single column, seen here under ‘Value’:
![]()
After some more cleaning and some final data cleansing, I uploaded it into tableau and made my very first word cloud!

After I finished this, I did go back and investigate looking into common word patterns using R (and the invaluable help of Louisa). It made the overall dash look a little messy so I decided to keep it simple and stick with a word count dash.
In conclusion, this project was unconventional but helped practise API use and general data cleaning in Alteryx. It forced us to be creative with limited information and a numberless data-type, which we aren’t used to using.