Dashboard Week day 4 has arrived and it started again with the morning presentation about yesterday project, followed by today’s project kickoff. This time the data set was completely different: looking at the Energy production in the United States of America.
Each member of the team chose one Energy type to extract in Alteryx and then analyse in Tableau. I decided to look at the Nuclear data Capacity and Generation from the eia website. The data is looking at the Nuclear capacity and generation for each country worldwide from 1980 and 2015. However, I decided to focus on the US, the Nuclear generation worldwide leader. I also supplemented the Nuclear set with the US State level data, providing annual generation in the sector.
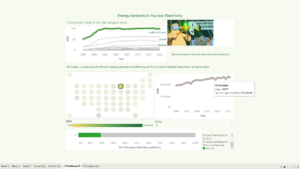
In my final visualisation in Tableau I decided to use the data as a comparison tool to show the supremacy of the US in the market against the other world leaders. I also looked at each State electricity production with both a US Tile Map and a timeline to show each state grow over time.
![]()
When clicking on a State on the Tile map, the timeline filters accordingly and with a dashboard action it is possible to visualise another hidden sheet, showing the percentage of total energy production for each state by category.

In order to arrive to the final visualisation in Tableau, it is necessary to clean and prepare the data source first in Alteryx. Today I decided to take a slightly different approach from yesterday and Nora helped me solving a crucial part of the following workflow, without her I would possibly still be looking at the data until now!
The initial data was downloaded from a Text file and once imported into Alteryx looked all together without a clear delimiter. After several attempts I found out that the best delimiter to use in this case was the closed curly brackets } rather than the open one.
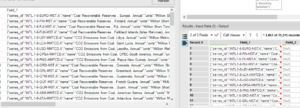
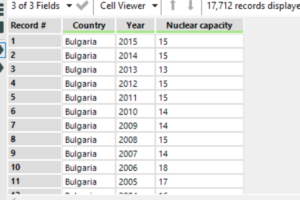
First of all I used a filter tool to find the Nuclear energy consumption among all the energy types and then I used a text to columns tool to parse out by the } delimiter. After that it was straightforward to isolate the countries names in an individual field, which I cleaned with the Data Cleansing tool. The main challenge was however to parse out all the different years from 1980 until 2015 with every single value attached and linked to the specific country.
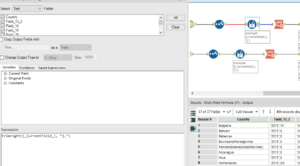
This is how the field looked like after the second text to columns parsing with the closed square brackets delimiter: each row has a column with a country and a combined field for each years with the respective value as follows “2005”,15],
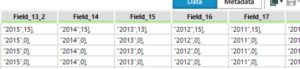
This is certainly not the ideal formula to analyse the data and not even the easiest. Therefore a bit more of data cleaning and preparation is required before analysing it on Tableau.
The first step is to remove the squared brackets and the coma on the right with the Multi-field formula as Nora showed me today: trimright([_CurrentField_], “],”)
After that Transpose all the fields in order to have all the values for each country one after another and then filter out all the non countries names within the country field with a formula tool.
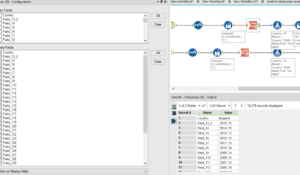
In the same way use the multi-row formula to shift up all the values that do not contain a Country field, in this case called Tim in order to find it more quickly.
if [Country] = ‘Tim’ then [Row-1:Country] else [Country] endif
Finish off with some more minor cleaning before exporting the data.
![]()
I used the text to columns parse tool with the coma delimiter to split the year from the value into two different fields. I also used two different data cleansing tools to remove punctuation and letters in the two different fields. At the end I used a filter tool to remove empty fields in the data set.
And here we go: the parsed and cleaned data set, ready to be used in Tableau public, where you can look at my latest Interactive Viz about Nuclear production in the US and worldwide.