


Have you wondered about the full data lifecycle? Which processes are included in that lifecycle and their purposes?
In this blog, I will explore and find the answer to those questions.
The content of this blog post is based on my summary and thoughts after completing the course and reading the "Fundamentals of Data Engineering" book by Joe Reis and Matt Housley.
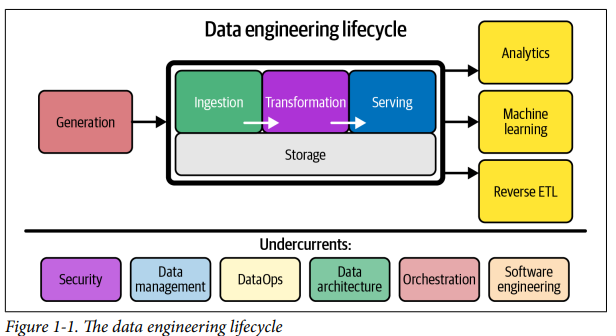
From Fig. 1, the data engineering lifecycle contains 5 main stages: Generation, Storage, Ingestion, Transformation, and Serving. I will walk through each stage in the blog.
Generation
Generation is the first stage where the source system is used in the data engineering lifecycle. The source could be from an IoT device, a database, or a third-party source. A data engineer should understand how to interact with those sources, how the source generates data, limit of the source systems, and consider:
- Data generation (At what rate is data generated? How many events per second?)
- Data persistence (Is data persisted long term, or is it temporary and quickly deleted?)
- Data quality (Will the data contain duplicates? How often do data inconsistencies occur?)
- Schema of the data (Will data engineers need to join across several tables? If schema changes, how is this dealt with and communicated to downstream stakeholders?)
- Upstream data dependencies (what are the characteristics of these upstream systems?)
- Performance (Will reading from the data source impact its performance?)
Storage
After data is generated, we need a place to store the data. The storage stage can run across the entire data engineering lifecycle. It occurs in multiple stages in a data pipeline (Ingestion, Transformation, and Serving).
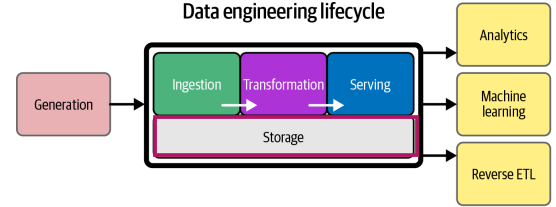
Storage could be on-premise or on cloud. When choosing a storage system for a data warehouse, data lakehouse, database, or object storage, a data engineer can consider:
- Read and write speed
- Bottleneck for downstream processes
- How frequent a storage work?
- Scaling (available storage, read operation rate, write volume)
- Is the storage schema-agnostic (object storage), flexible schema (Cassandra), or enforced schema (a cloud data warehouse)?
Data warehouses are a standard OLAP (Online Analytical Processing) data architecture. It's less adaptable, requires a predefined schema (schema-on-write). It's more complex to scale. The limitation of a data warehouse is that it cannot handle unstructured data (images, video, audio).
Data lake is highly adaptable and can handle various data types such as structured, unstructured, semi structure data. Data lake is expected elastic scaling, but it's more complex to maintain.
Data lakehouse is an architecture that combines aspects of the data warehouse and the data lake. The data lakehouse can store multiple data types. Lakehouse also support table history and rollback. Many tools can connect to the metadata layer and read data directly from the object storage in the data lakehouse architecture.
Ingestion
After the generation stage, that's data ingestion stage. The source system and the ingestion are the most significant bottlenecks of the data engineering cycle. The reason is that the source systems are outside direct control, or the data ingestion service might stop working for many reasons.
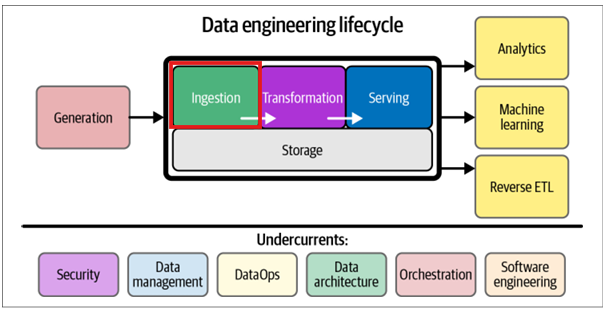
For this ingestion stage, we might consider:
- Business use cases for the data
- Data reliable
- The destination after ingesting data
- How frequently to access the data (how long or what might cause the data to be unusable?)
Batch vs streaming ingestion
Batch ingestion is a convenient way for processing the stream in large chunks that can be decided by size, time period, or threshold.
Streaming data allows to provide data to the downstream systems in real-time.
Transformation
In the previous blog, I discussed the ETL, ELT, and reverse ETL. The T, which is referenced to Transformation, can be before or after loading data. The data needs to be changed from the original form to useful data for downstream use cases.
For example, after extracting data from the API, the response data can be in JSON data type (semi-structured). The, the data engineering can parse/ flatten JSON into structured data to store the data.
Serving
After the data is ingested, loaded, and transformed, the last stage is serving it to the user. The data analyst can analyze the data and get insights from the BI tools and support to make a decision. For machine learning, the data is used to predict or making decision. For reverse ETL, the data can be transformed back to the source system for business use cases (for example, marketing strategy).
The data engineering lifecycle includes 5 stages: generation, ingestion, transformation, serving, and storage. Understanding this process, I know how the data moved from the source system to the endpoint. Depending on the complexity and the cost of the organization, the data engineer can choose the best way to proceed for each stage.