


I sincerely hope you never have to connect a Cloud Storage Platform to Snowflake. However if you find yourself in the position of having to do so... this blog is for you It's written from the perspective of someone who has just gone through this process for the first few times.
If you have access to it, AWS S3 can be a great place to stage your data in a pipeline. It can sit there for as long as you need it, then you may delete it. Staging can be a good idea if you need a "stopping point" for your data along the way. If you stage data in S3 prior to loading or transforming it, you've essentially bulletproofed yourself against issues happening later down the line. For our use case, we're imagining this data is being loaded from S3 into Snowflake, where it will be transformed and stored permanently.
This process is convoluted. It doesn't make sense. It makes complete sense. Whether it makes sense or not doesn't make sense.
There is an absurd number of different things, each connected to various other things, and each thing is named something sort of random. Some things are inside other things. Some things are folders, some are access keys, some are portals into folders.
Here's an Excalidraw diagram I drew up in an attempt to keep track of them all and how they connect:
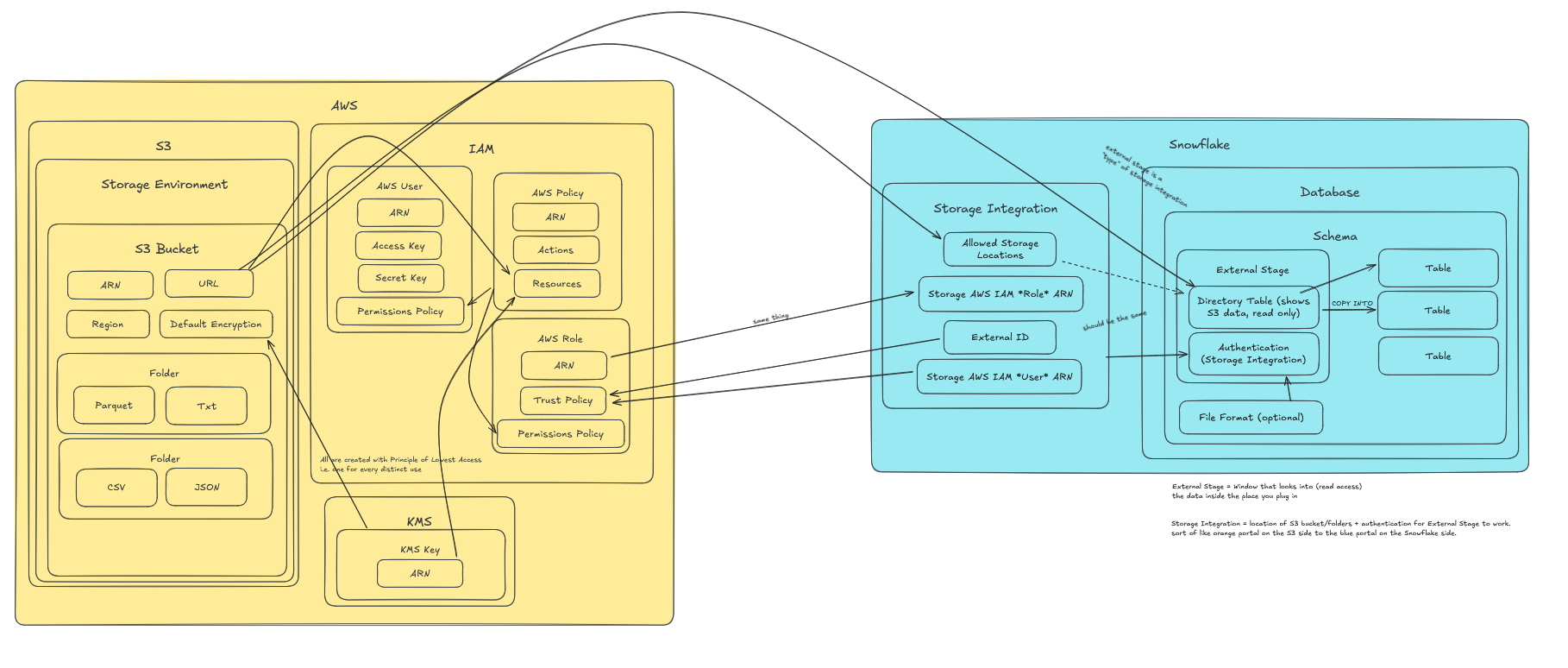
I'm simply not going to tell you what each and every one of these things is. I will however give you these easy steps to follow.
First, if you need an S3 bucket, set one up. This is where you'll stage your data. How you get the data into S3 isn't a part of this blog, see my colleagues' blogs for that.
Setting up S3 Bucket:
- Within KMS: create KMS Key if you don't have one already.
- Within S3: Create S3 Bucket and any folders/subfolders in that bucket
- plug in KMS Key ARN
- IAM: Create a policy, choose JSON
- plug in S3 Bucket/folderpath where you want the data to come from
- plug in KMS Key ARN
- I can't copy-paste the text of the policy here, but I would suggest quickly looking up a AWS IAM policy JSON template. Below is a screenshot telling you where to plug in the above information.
- IAM: Create a user
- assign the policy you just made to this user
- Create access keys for the user

Nice. S3 Bucket is set up. Ensure you've got some data in the bucket and subfolder you plugged in there. Here's how to get that data into Snowflake:
Setting up S3 <-> Snowflake Connection:
- Create an AWS Role, setting External ID to '0000' as a placeholder
- plug in S3 bucket/folder name similar to the policy JSON above
- Create a Storage Integration in Snowflake, selecting AWS S3 in the options
- plug in the AWS Role ARN and S3 bucket folder URL (ex: s3://...) into the allowed storage locations
- don't fill anything in for the External ID - when you create the Storage Integration, this will be created automatically
- Plug the External ID and Storage AWS IAM User ARN (this is a Snowflake User ID) from the newly created Storage Integration into the AWS Role's Trust Policy
- Create External Stage within a Snowflake Database/Schema, plugging in the S3 bucket/folder URL and the Storage Integration as the method of Authentication
If you've done everything correctly, you should now have an External Stage set up in Snowflake. This is essentially a specialized "window" that lets you peek through into the S3 bucket/folder you plugged in. It's the equivalent to read-only access. From within the schema you can copy data from the external stage into new tables.
Nice work!