


The last few weeks in the Data School have seen us learning lots about APIs and web scrapping in Alteryx. I thought it might be useful to do a quick series introducing some of the concepts and discuss where and how they can be useful.
First let’s go back to basics and talk about this new-fangled thing called “The Internet”. Stemming from the human desire to spread information, knowledge and learning, the internet has become a fantastic resource where you can learn anything from Tableau and Alteryx to how to fix the kitchen sink. Or look at memes, whichever.
The Internet is made up of web pages, which are in turn made up of code. The fundamental back bone of a website is it’s HTML (Hyper Text Markup Language), and it’s this that we use to extract data from websites. Each item you see on a web page, be it the title, an image, or writing on the body, is wrapped in a set of tags. These tags separate the HTML into sections and are tremendously useful when trying to parse out the code once you’ve downloaded it into Alteryx.

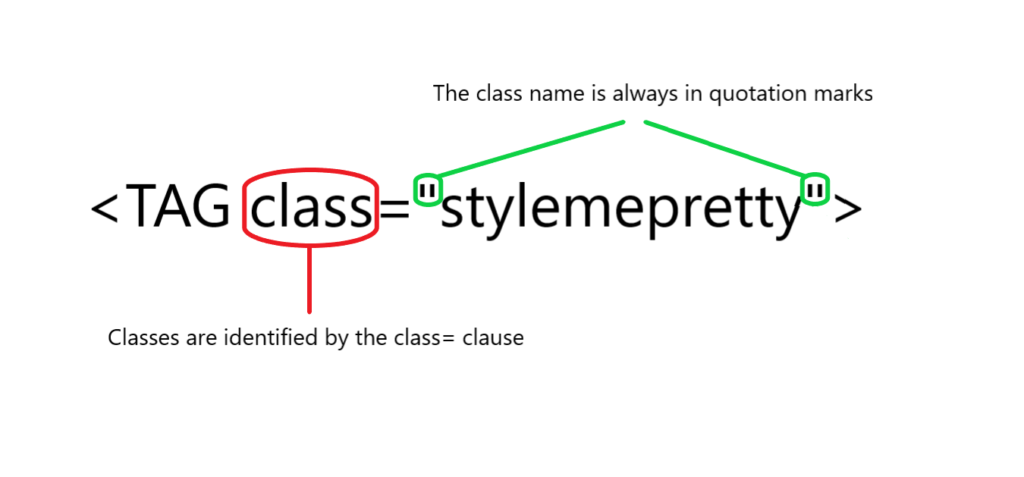
Tags come with a standardised format; the font in an <h1> header tag will be bigger than in an <h2> tag for example; but the formatting and styling can be altered with CSS, or Cascading Style Sheets. Tags can be given classes which refer to sets of styling in a CSS sheet, these classes and can help to distinguish tags from one another when parsing out code.
The final major code component of a website is JavaScript. JavaScript is different from Java, and is not responsible for coffee-cup thumbnail with the constant reminder to update which always used to appear. Instead, JavaScript is a major player in website interactivity, from menus that pop down when you hover to endless scrolling on social medias. This is important to note when web scraping because if you want to scrape data from a website which loads dynamically as you scroll down, this becomes pretty complicated pretty quickly, although is now possible. More coming soon on where I encountered this issue in a web scraping project with Gheorghie.
One final this that always confused me: front vs. back end. This refers essentially to what is client-facing and what is not. So, taking an example like Twitter, your front-end is the Activity Feed you see when you log in and is based on JavaScript. The back-end is based on other languages (see here), and this lets the website access the server which sits behind the feed, accessing things like how the website works and its associated databases. A really good explanation is available here, although bear in mind that for web-scraping you’ll be accessing front-end.
Stay tuned for Part II: What’s an API when it’s at home?