



JSON file type is a common type choice for data shared online, given it's compactness, it is preferred format of access API data. The data are saved in a particular structure as a string.
Rules:
- <NAME>:<VALUE> Data is in name/value pairs. A name/value pair consists of a field name (in double quotes), followed by a colon, followed by a value: "firstName":"John"
- Data is separated by commas
- Objects are enclosed in curly braces ({})Objects can contain multiple name/values pairs: {"firstName":"John", "lastName":"Doe"}
- Arrays are enclosed in square brackets ([])
An array can contain multiple objects:
"employees":[
{"firstName":"John", "lastName":"Doe"},
{"firstName":"Anna", "lastName":"Smith"},
{"firstName":"Peter", "lastName":"Jones"}
]
During the Data School Snowflake project, we are asked to download London TFL bike rental data through an API from Alteryx connection, then load directly to a Snowflake server and transform within Snowflake environment. The aim is to demonstrate the transition from Extract, Transform, Load (ETL) to ELT mode.
To start we have a single file to work with

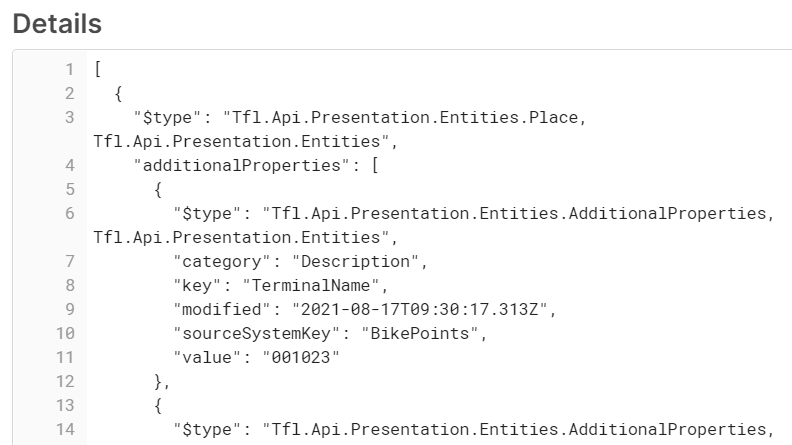
To understand the structure better, let's view the code within a code editor.
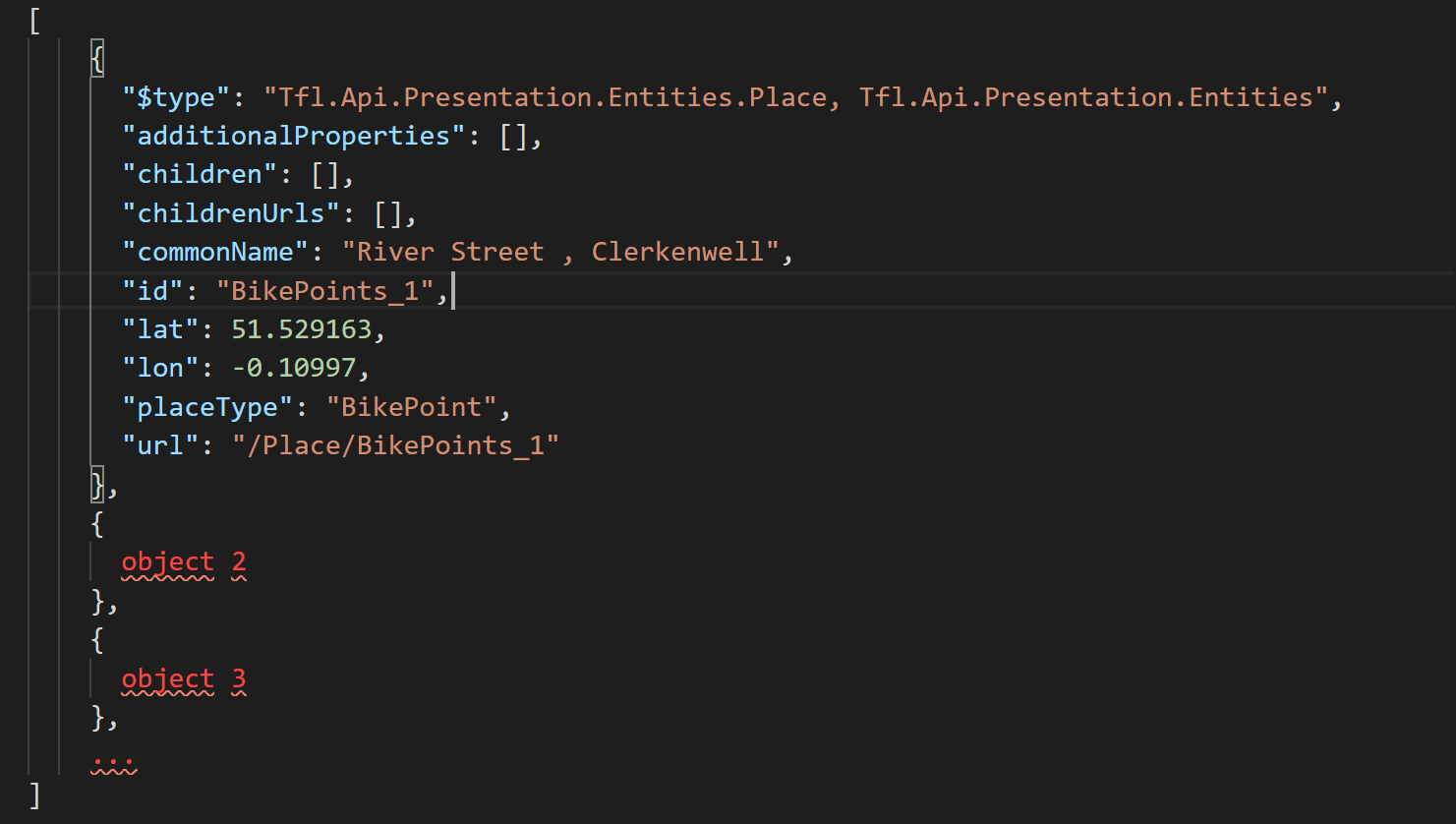
The first thing we need to notice is the external '[]' on the whole entry which represents an array that is needed to be flattened, then there is another '[]' for additionalProperties, i.e. a nested array.
Note: children and childrenUrls are empty, so we ignore them in the analysis
To flatten the JSON in Snowflake, there is a function - LATERAL FLATTEN (office page). Though the office page doesn't give the best example, let's demonstrate in this post with particular examples.

As shown in the first picture, we have a table with a single column BikePoint_JSON from Project_BikePoint_Data table. The function lateral flatten is called on the column that contains the JSON file (need a common in between). Once the array is flattened, then each objects within are name and value pair (as shown in the sample code at the start of this blog) will be displaced as separate rows. Most of the time, we are only interested in the value of the output, so we can call .value:, then the required columns.
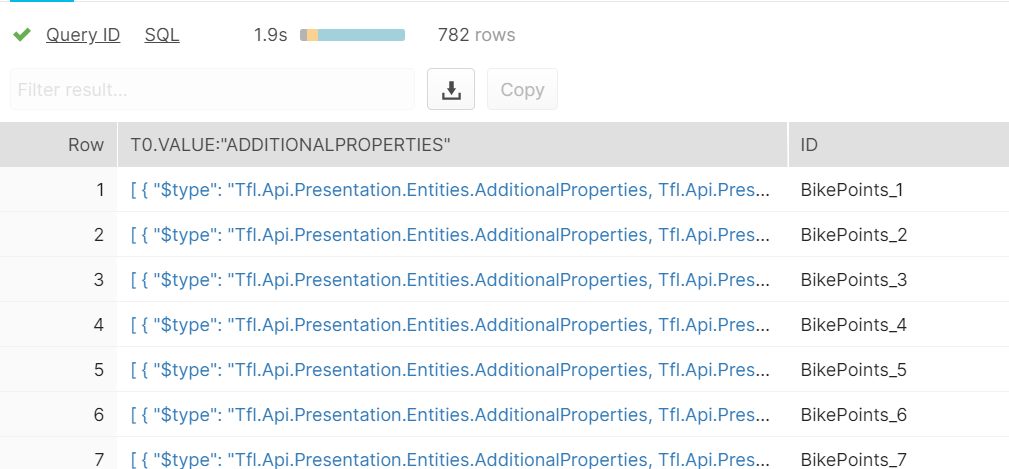
We notice the first column still contain another array which we need to flatten as well, this is a nested structure, but the lateral flatten function is easy to use where we can just repeatedly applying it.
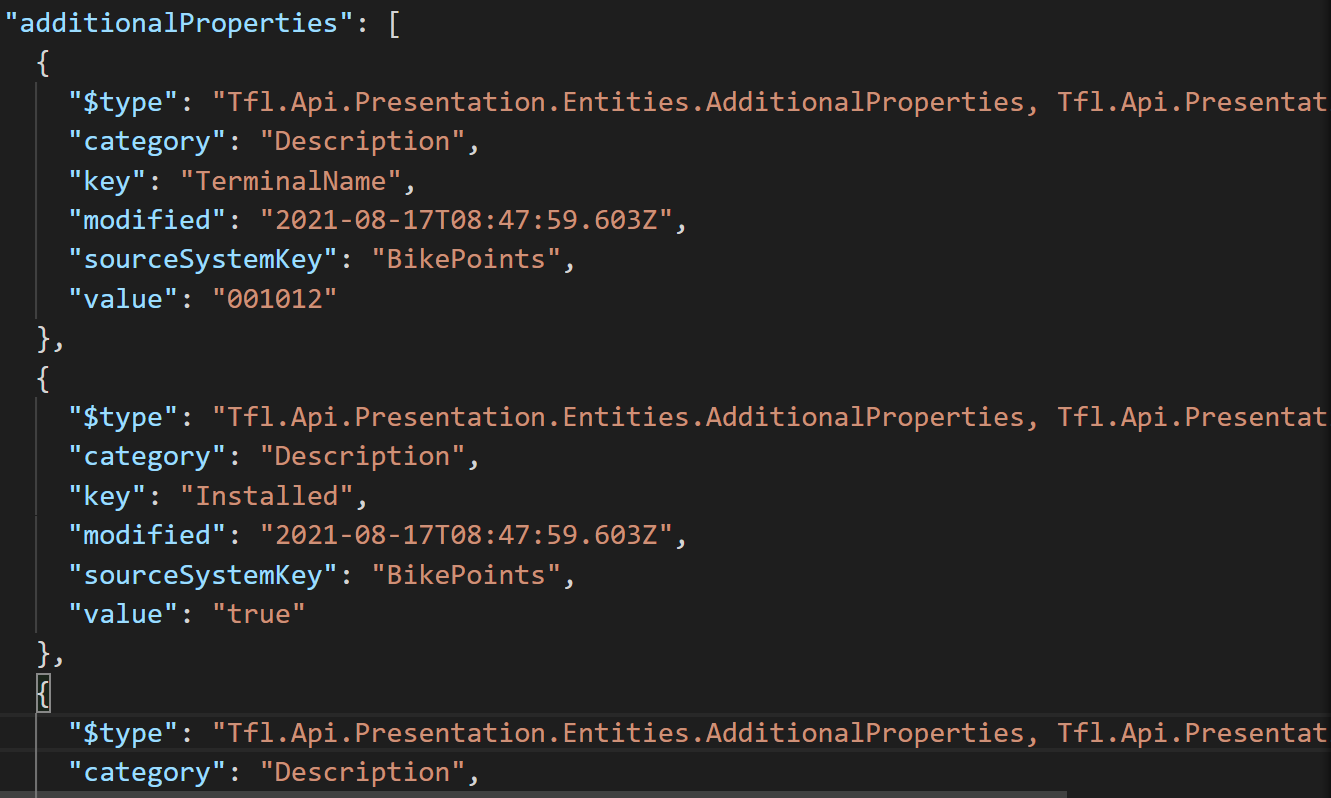
We can setup a similar structure as the above code, with additional name for results from inner array where we called t1 here. To get the results from the inner array can be called with .value on t1 instead, while results from the outer array is called with .value on t0.

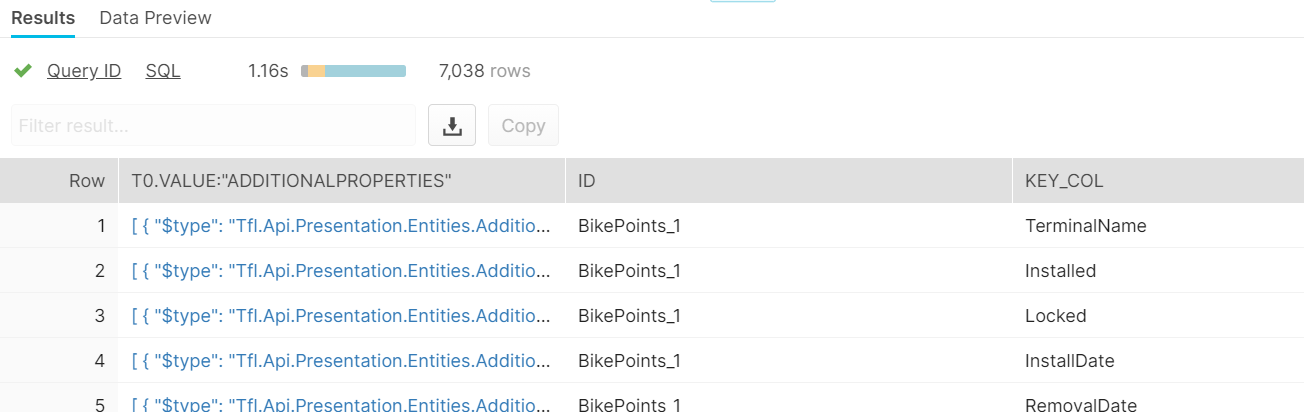
Since each objects (782) from the outer array has 9 objects each, the final results has 7038 rows, so flatten effectively created an appended table.
Now you can just add addtional calls to get any of the required columns from the JSON file in Snowflake in a query, rather than some complicated RegEx code.
Looking for more guides, tips and tricks in Tableau or Alteryx? Go check out the other blog posts from the Data School.