


As I come towards the last week of my Data Engineering DES4 now face pipeline week where we now utilise the MailChimp API to extract some data, load it into an s3 bucket, connect it to snowflake, transform the data with dbt and/or snowflake and then think about how we can orchestrate this whole pipeline process.
Plan
I wanted to spend most of the data of ensuring I am extracting the data I needed from MailChimp. Firstly, there are some key questions that I had in mind before I got into looking into the MailChimp documentation to get what I needed:
- Is a user clicking the link in the email multiple times?
- What’s the percentage of recipients clicking on the link?
- Which topics lead to the most click?
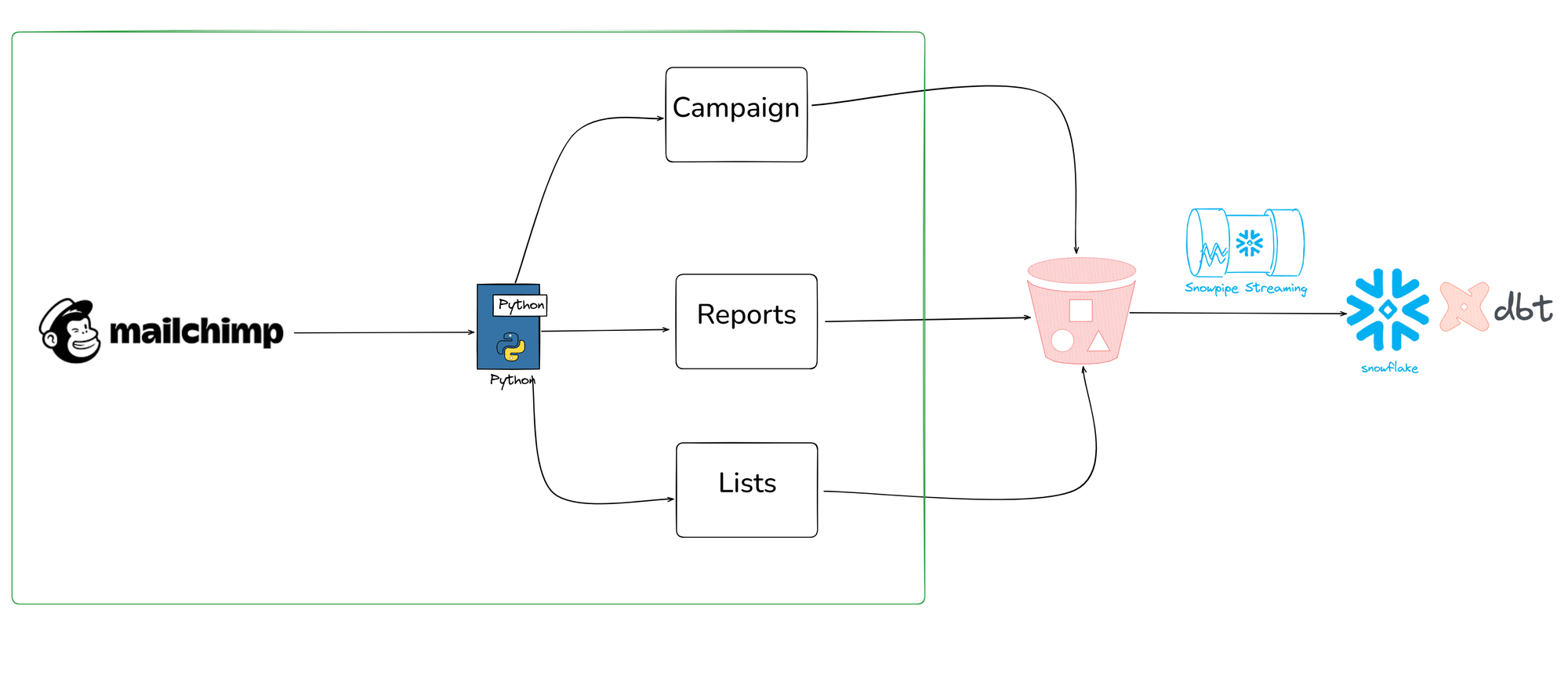
With those questions in mind, I began to scour the MailChimp documentation to find the appropriate endpoints to that will help this analysis later down the line. After some investigation and discovery, this made me come to use the endpoints illustrated in the diagram above.
Mailchimp have a GitHub repo where I can do a pip install of that repo, which allowed me to configure my python script to connect to the API by importing packages respective to it.
From then I was able to build the script to call it whilst using the endpoints and added some logs regarding number of campaigns, reports (which have detailed info about clicks), and lists.
Next Steps
Next phase would be to now create and configure an s3 bucket so that when I run a python script it can push the campaigns, reports, and lists data into it. Then I will need to set up a snowpipe and stages so that I can load the data that resides in the s3 bucket into snowflake.
If I find some time, I can make some lines of code in my script into a function that will tidy up my code as it uses some same code when calling for the different endpoints.