


My first visualisation for my application process centred around a sample of user data from the PC game platform Steam. This was an analysis of which games were most popular by owner usage and play time, as well as customer segmentation by those groups into five categories.
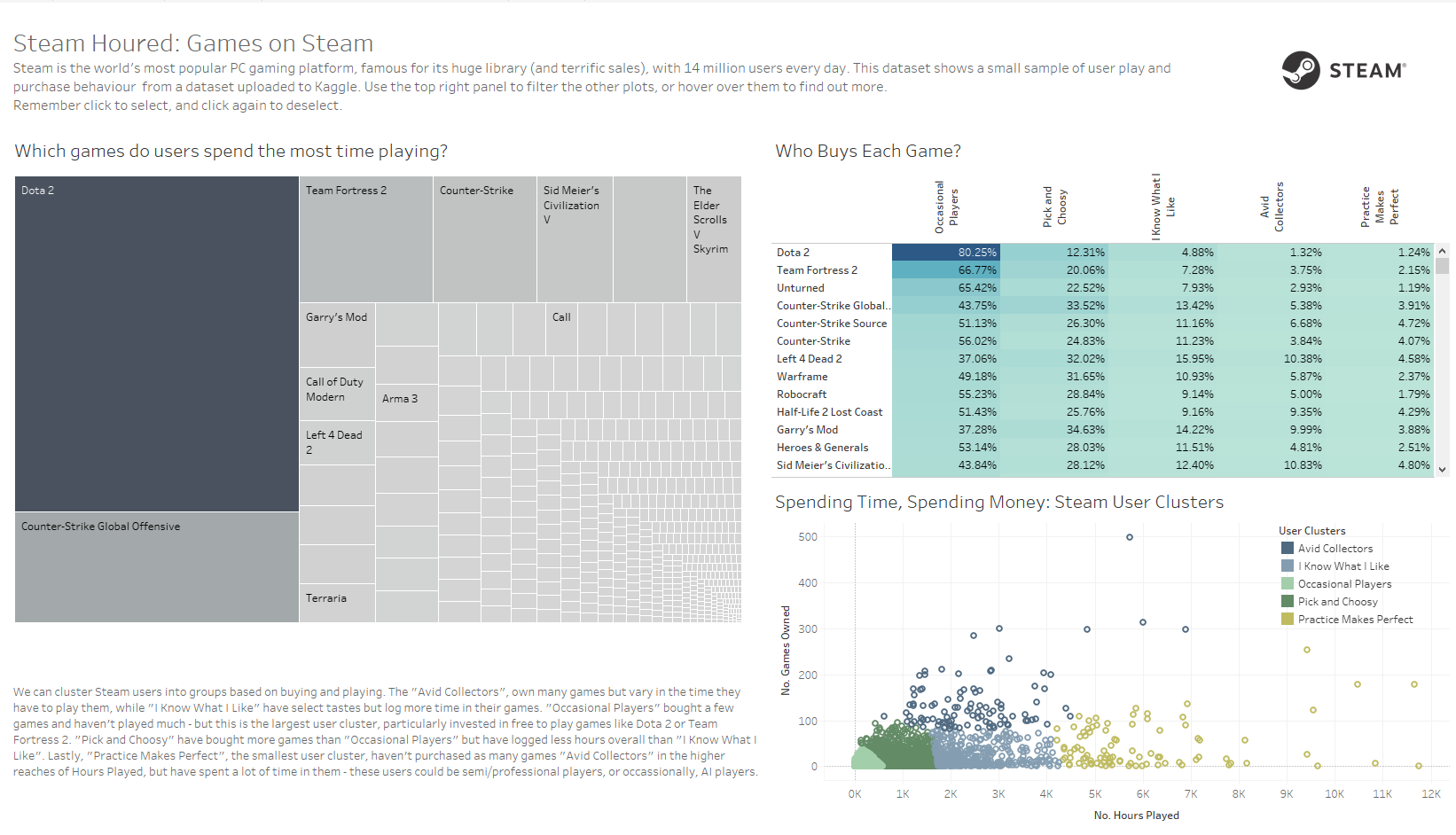
My original application dashboard. We’re focusing on the bottom right corner.
Our first presentation from the first week of the Data School was to review and update one of our presentation visualisations, enriching the data set by joining it with a new one. First challenge was precisely which data set to use – the original sample I had was from Kaggle. Steam’s platform collects a lot of data and shares visualisations with users on individual stats they may find relevant (see below) but are notoriously cagey about releasing commercial information. SteamSpy is an effort to improve this visibility, so I decided to focus my story down from all games to only the top games across playtime, which I downloaded from Steam Spy’s leader board, and joined it to my existing data in the following flow.
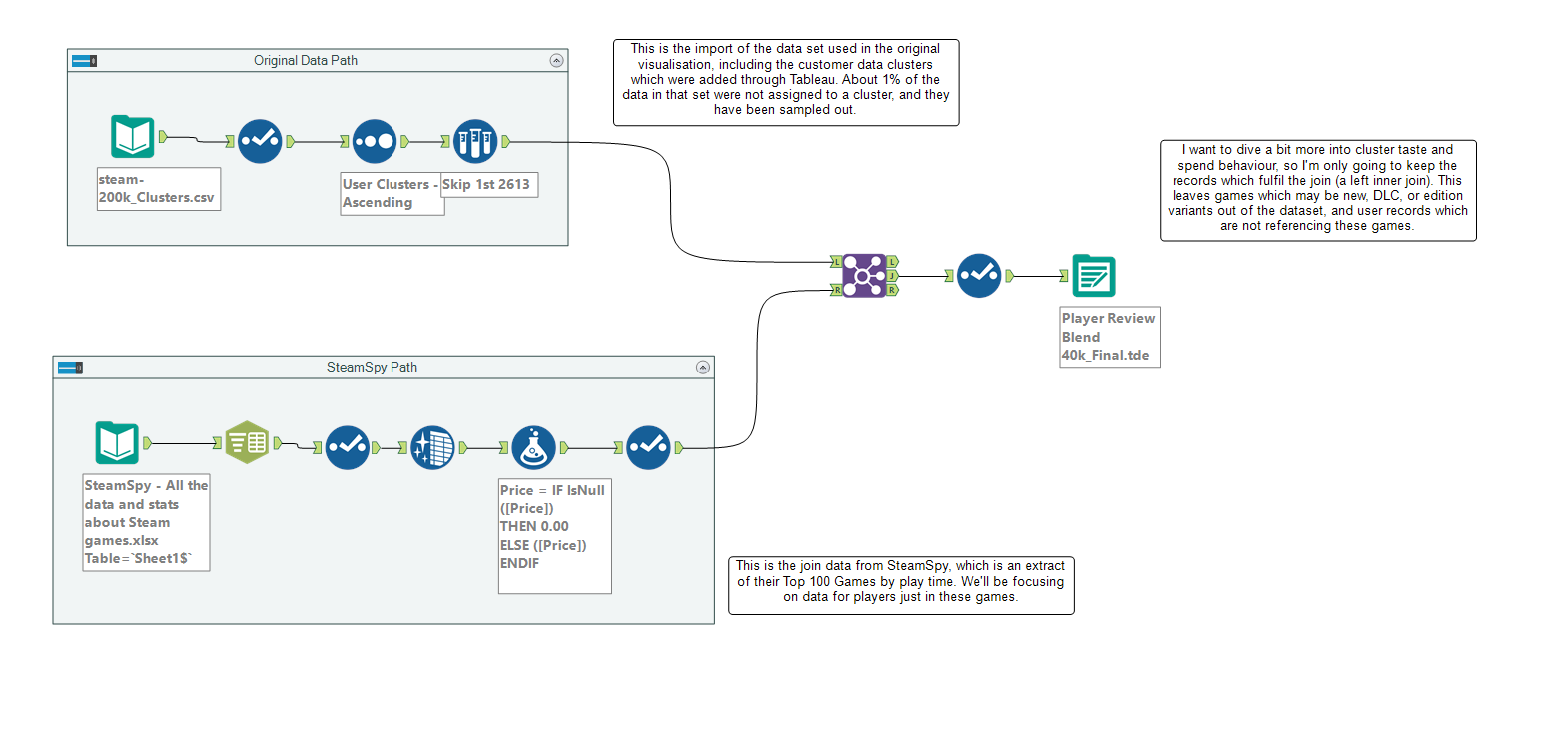
Alteryx Flow to join the two data sets.
I only wished to retain the inner join of information, which means only retaining the games which provide cost information and the users who play them. This significantly reduces the dataset but still leaves about 40k records, which is enough to retain the user clustering. Focusing in on user clusters meant changes to the dashboard. The tree map was retained but changed to show proportions of ownership within the clusters, as well as adding insight into the value of player’s time (with a reference line to compare to the value hour of films) on a jittered scatterplot (thanks Carl!), and the spread of ratings in player portfolios (which players are willing to try new or different things, which may not be as well rated). You can use the dashboard at this link to Tableau Public.
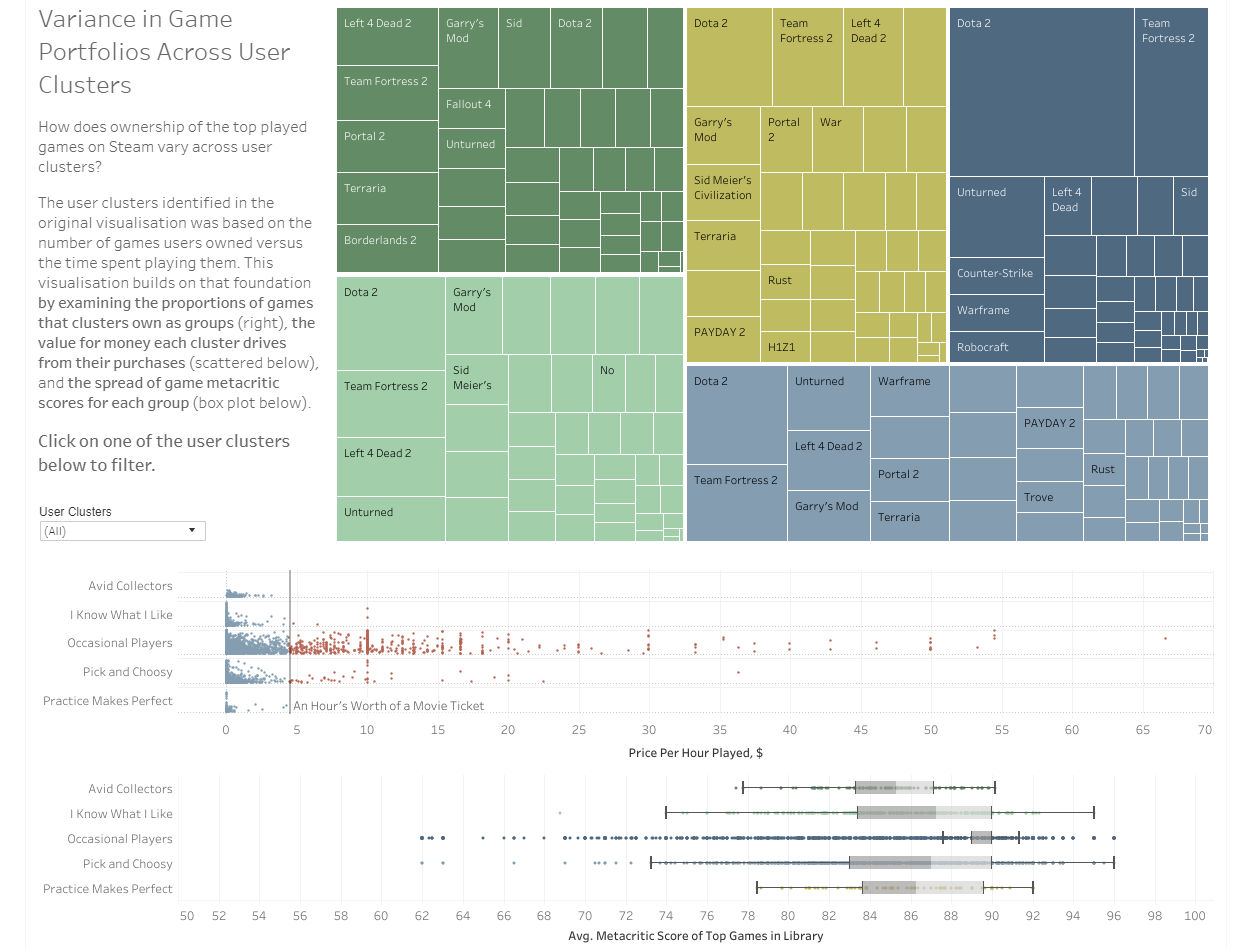
The new dashboard, post feedback.
There are further changes that I would like to make in order to further interrogate the data, such as creating a scraped database of game metainformation. Look out for Volume 3 when I’m better at Alteryx!