


Much maligned (feared?) core programming technique, one of Regex’s easiest use cases involves creating dynamic API calls which can respond to page limits.
APIs will often have pagination limits in order to throttle the calls made to it – seriously developers who may be making extensive volumes of calls (e.g., because they are building apps) are generally expected to contribute to the server architecture they are using. This post will discuss how to use regex to generate new page numbers for a URL when calling a list of items from a site, using the Movie Database’s new TV API as an example. This API is very clear to understand and very well documented (looking at you, Google) which makes it great to learn from.
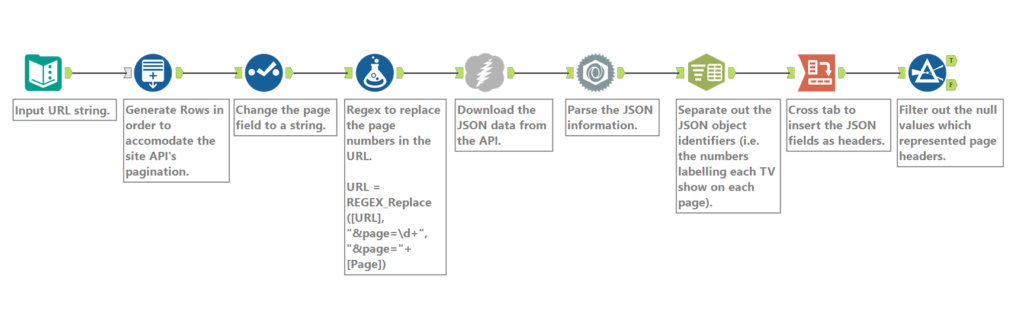
We’re going to focus on the first part of this flow. First, enter the URL of the API you want as a text input, which in this case is https://api.themoviedb.org/3/tv/top_rated?api_key=<<api_key>>&language=en-US&page=1 (documentation here). At the end of the call you can see the pagination, which limits the number of calls. Calling this on its own will give you the top chunk of Top Rated shows (the top, arguably), but I would like to see all the shows on this list. A regular call with the download tool reveals there’s 32 pages in this list (which is uncommonly helpful!), which gives me a number for the number of rows I’d like to generate (32). After generating the rows, you need to change the field type of the row you’ve just generated to a string so the regex formula can pick it up, which is the next step.
The formula tool in Alteryx can be used to apply regex, as well as the Regex function in the Parse palette. In this case, the formula is calling the REGEX_Replace function, asking it to look in the URL field for the pattern “&page=\d+” – this is explicitly stating that I’m looking for “&page=” and then a character with metainformation indicating it is a digit. The second part of the field is replacing that search string with “&page=”+[Page], which is again explicitly stating that I’d like to add “&page=” to the file and then add a number from the field [Page], which are my row numbers. This means that my 32 rows becomes 32 URLs, pointing at pages in sequence.
Following this, the Download tool will call the API for each page by following each row, and put the JSON data in a field, ready to be parsed. Once parsed, this can be combined with additional data which can be extracted through additional API calls, such as cast and crew information, series information or similar TV shows.