For this blog post I will do a guided, step-by-step walkthrough of a solution to Alteryx weekly challenge #211, with a specific focus on the ‘REGEX’ tool.

For this data set, we have a single row and column containing a plethora of names with ascending numbers attached. The aim here is to generate email addresses from these names, and group them by alphabetical letter.
The first tool we will use here is TEXT TO COLUMNS and we will be splitting the singular column into several rows by parsing out each person’s name using the comma as the delimiter. We now have 1 column and 300 rows containing a different name and ascending number.
The next step is to simply remove the any value with ‘N/A’ using the FILTER tool, followed by the DATA CLEANSING tool to remove the ascending numbers.
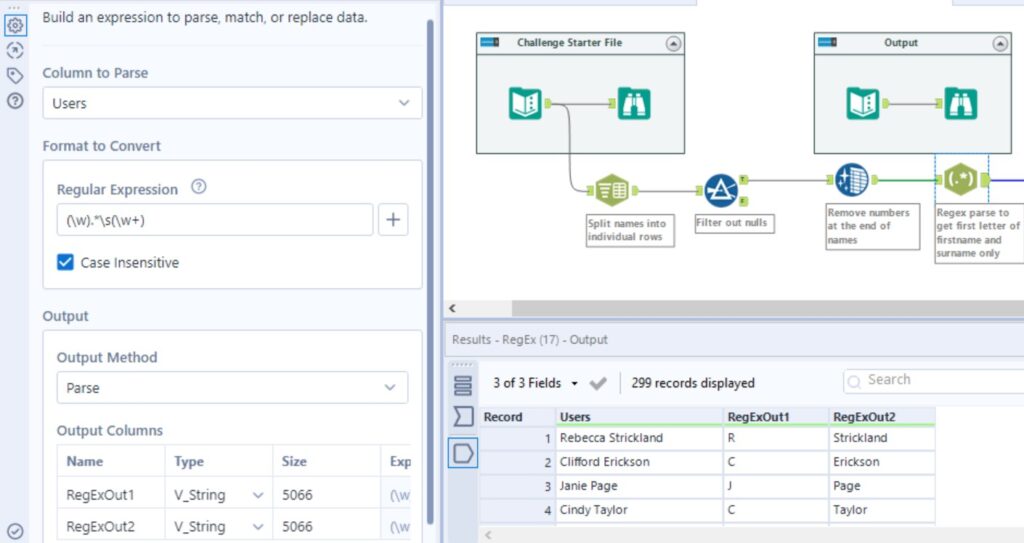
Now for the exciting part, the REGEX tool… In this case we will use the output method of ‘Parse’ to extract just the first letter of each person’s name, as well as their surname. To do this, we will use the regular expression “(\w).*\s(\w+)”. The important parts of this expression are what we are capturing in the brackets to be parsed. So now we have “(\w)” = first letter of the first name; and “(\w+)” = surname extracted as the two additional columns of RegExOut1 and RegExOut2.
These two columns can now be combined to create an email address using the FORMULA tool. The formula “[RegExOut1] + [RegExOut2] + ‘@testemail.com’” is then used to create an additional column with each persons new email address.
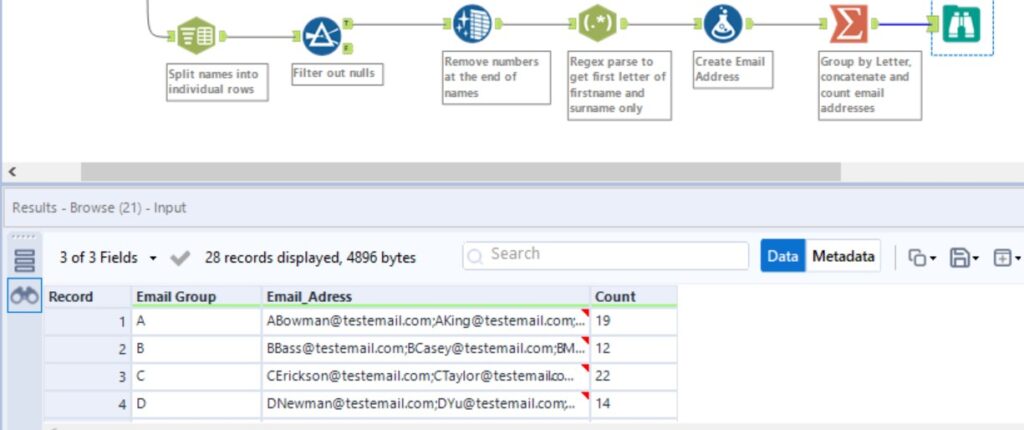
Finally, we will use the SUMMARIZE tool to group by the first letter of the first name, concatenate the email addresses using a ‘;’ separator, and count by first letter of first name to give us our much improved, desired output and completed weekly challenge.