



There is one thing I am really scared of: joins.
Whenever we have a weekly project (and even during Dashboard Week), I am always very careful when joining multiple files together.
There are even vizzes on Tableau Public to guide you on how the different types of joins work.
However, when we are faced with cryptic datasets, hundreds of thousands of rows of data, multiple files to join on some common fields and fields themselves to decipher with a Data Dictionary at hand, it gets really tricky and messy.
I feel that I still need to master this tool both in Alteryx and Tableau.
Therefore, when Gwilym came and shared a few practical examples on how we could avoid messing up with joins, I was really grateful.
Here are a few tips that I have learned about creating the right processes, setting up some checks along the way, and dealing with joins.
Case no.1: Be careful with the processes and tools you choose
Have you ever used the UNIQUE tool in Alteryx?

It’s very useful to remove duplicates. However, in certain cases, you might risk losing numbers along the way.
Let’s look at this example.
In a company, every department owns each other money. Departments might be located in different countries.
The logic is the same as in the math exercises everybody does in school: If I owe Paul £2 and he owes me £3 and Laura owes me £4… and so on.
If department X paid department Y a certain amount of money, every department would be even.
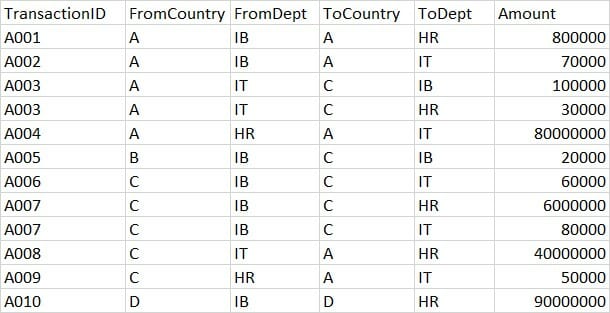
You have to conduct this analysis and you are interested at the country level. Therefore, you don’t take into account the departments that much.
Imagine you have a lot of columns in the dataset and the workflow takes a lot of time to run.
You may decide to remove some columns you don’t need. An example? FromDept and ToDept.
Now we have two rows with TransactionID A003 from A to C.
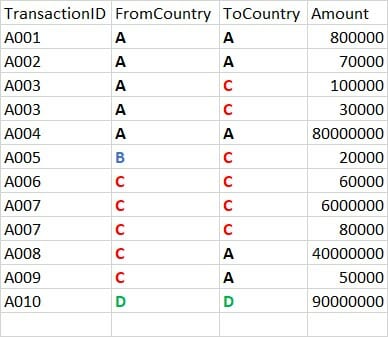
Imagine there are many people working on the same workflow over time. A person may have built the whole documentation on a complex workflow and another person may have to take over some time later.
At some point, while troubleshooting, what could that person notice?
That there are multiple record IDs, e.g.:
- A003 with 2 transactions from A to C
- A007 with 2 internal transactions within country C.
What if you decided to have one line item per transaction and use the UNIQUE tool?
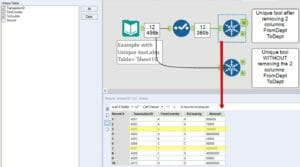
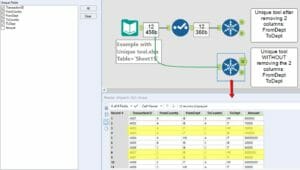
The UNIQUE tool takes the first line item each time and drops the other records.
If we hadn’t removed the two columns above (FromDept and ToDept), the UNIQUE tool would have taken them into account.
Instead, by removing them, we have lost that context.
In a very long and complex workflow, dozens of tools later, you might have trouble remembering that decision and spend quite a lot of time tracking down what the problem was.
Tip: Instead of the Unique tool use the Summarize tool. Group by everything and sum up the amount.
No matter whether you remove those two columns or not, you will get this result:
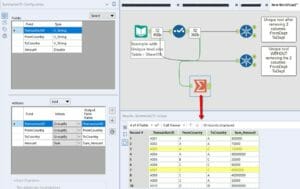
We might be talking about millions of pounds worth of data that we have lost track of because of a bad process.
Conclusion
Quite rightly, there should be one line per transaction. So you might want to put the Unique tool in.
However the combination of:
- Dropping columns
- Using the Unique tool
Made us lose a lot of rows.
Think about the implications of the choices you make
Imagine if the company were a loans or mortgages department. These wrong processes would cause it to lose customer data and payments along the way.
Case no.2: Be careful with joins
Let’s say we work for an estate agent and we have both a list of tenants and their rents.
2 datasets:
- Dataset #1: For each person, we have the amount of rent they need to pay every month.
- Dataset #2: We have a list of the same people with their personal info.
This is a mock dataset created on mockaroo.com.
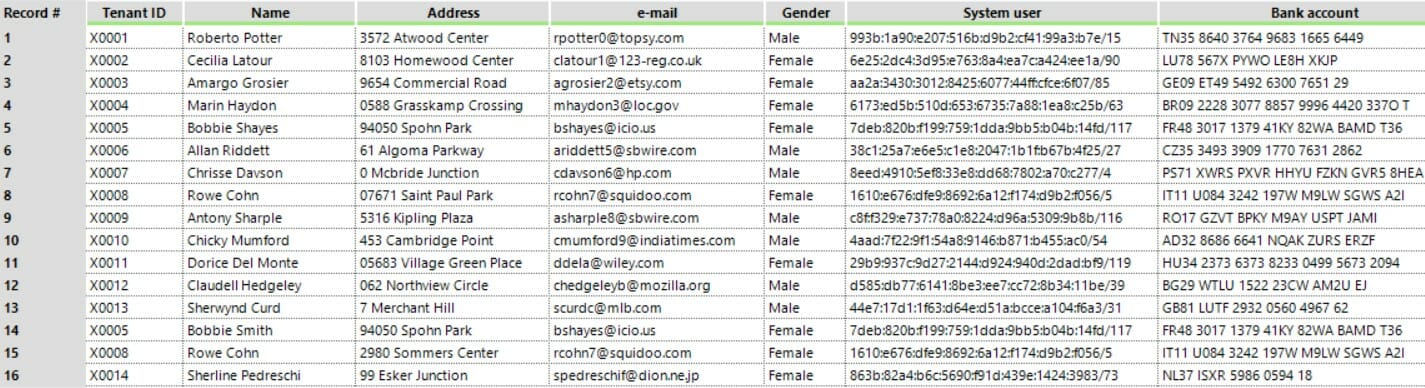
Do you notice anything strange?
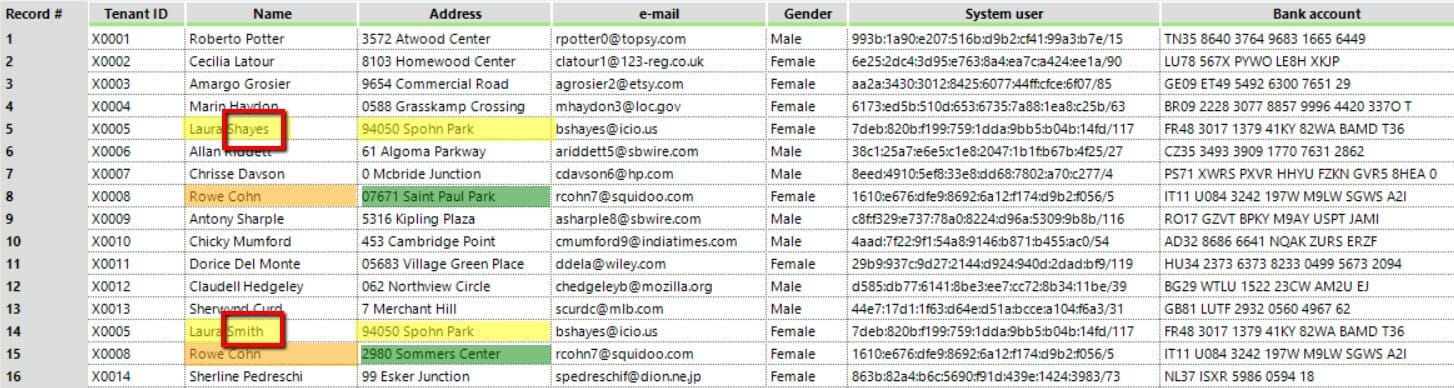
Dataset 2
Laura Shayes has changed her surname to Smith.
Rowe Cohn, instead, has just changed address.
However, X0005 and X0008 are brought in twice. We have two different rows for the same tenant.
Instead of changing a record, a lot of companies would add it as a new record. They would add more rows with the same ID and maybe a validity data column which makes one row valid before a certain date and the new one valid after that date. In this case, we have a boolean field called “Current address” which is TRUE or FALSE.
Rowe now lives in a new apartment and her previous address is no longer valid.

The logic would tell us to join the two datasets I mentioned above, one with the rent information and one with the tenants’ personal info.
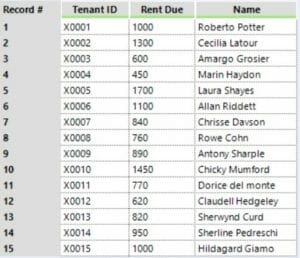
Dataset 1. As you can see, X0005 and X0008 appear only once.
However, by doing so, their rent will be doubled. And Laura Smith will appear as Laura Shayes twice.
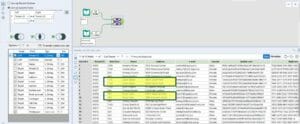
The join will fail and will assign these two tenants a rent that is double the amount they are supposed to pay.
What if we added a Filter tool on the Personal info table?
What if we filtered out one of the two rows for both tenants?
Let’s filter by Current Address = TRUE
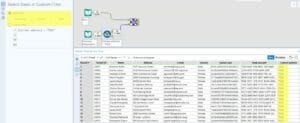
We have solved the issue with X0008, but X0005 is still there twice.
If we had another name validity column like “Current Name” (TRUE/FALSE), then we could filter by Current Name = TRUE and solve this one as well.
Conclusion
If you join two files by a field similar to the TenantID used in this example and you don’t look for these issues, you’re not necessarily going to realize that this is happening.
This kind of dataset would contain hundreds of thousands of rows and you wouldn’t be able to look at the entire table and see instantly whether these fields have changed.
You need to set up checks in your process. Every time you make a join, you need to think it through
Should the join multiply the number of records? Should the number of records remain the same? Should we lose records?
Tip: You might want to set up a Summarize tool to count the number of rows before and after the join and then compare the figures.
What if we joined by both TenantID and Name?
Well, this could sort out the problem. However, names are often full of typos.
Can you find one?
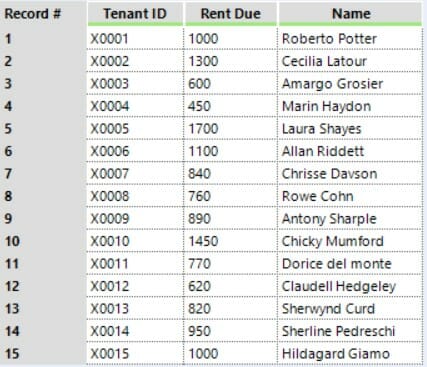
Dataset 1
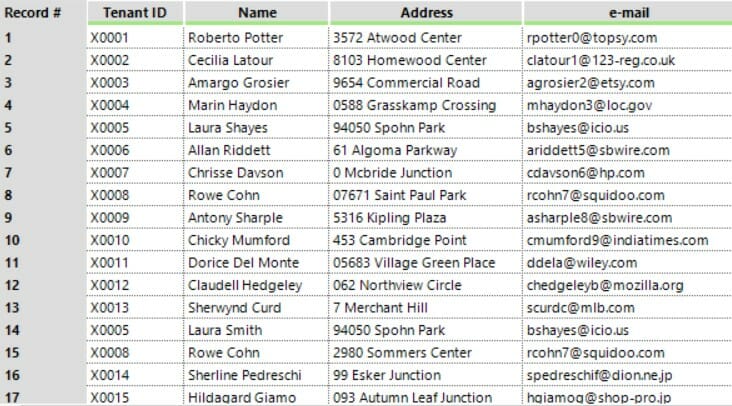
Dataset 2
The “D” of Denise Del Monte is capitalized in one dataset, but not in the other!
It is not going to join.
It took a little while to find it, right? Imagine what would happen with a sizeable dataset.
I have also given you a hint about the fact that there would be an issue with the name. What if I hadn’t?
You might be joining on a field and not be thinking that that is what is going to cause it.
In this case, we would have lost Denise’s record.
This dataset is about collecting rents. Through a wrong workflow, you may have established that some people are behind on rent while they have actually paid it.
The ethical side of this job comes in. I am really grateful about Gwylim who walked us through some plausible scenarios.
What happens when you join on text fields?
A good practice is to create an additional column (let’s call it “NAME (FOR JOIN)”) which sets the entire text field to uppercase.
Then, you would do the same thing for the other dataset that you need to join.
You can then drop those two columns immediately after the join.
It’s a bit of processing, but it’s much better than spending time troubleshooting while working with very long workflows.
It will save you time in the long run.
Tip: Put little checks in your workflow. It will save time in the long run.
Joins and Blending in Tableau
This is a tricky topic for another blog post.
One thing is to learn them through basic examples, another is to make decisions with much more complex datasets!
******
Credits: