


When designing a data system, one of your first decisions will be between columnar and row-level storage. These two storage options serve very different purposes and are optimized for distinct workloads: OLTP (Online Transaction Processing) and OLAP (Online Analytical Processing).
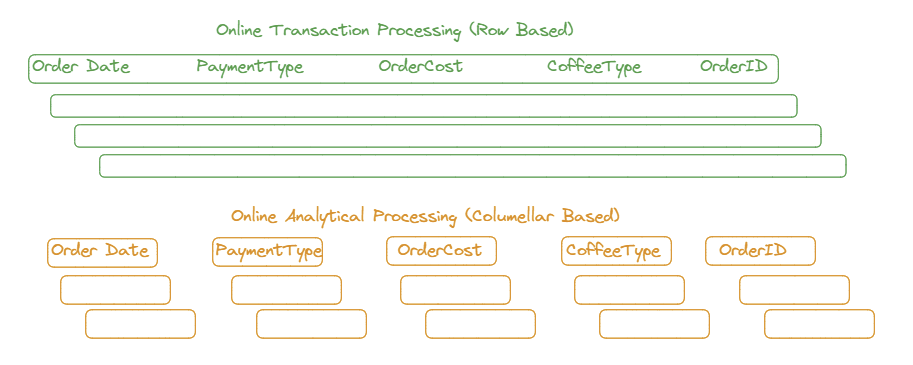
First, to begin, I like to think from a coffee shop's point of view. For each order made in a coffee shop, a row of data will be generated (coffee order, cost, payment type, time, etc). This information is based on a transaction, and makes sense as a row of data - therefore, we would store it in an OLTP. When it comes to analysis, on asking the question "what types of coffee have we sold", we don't care about time time, cost, or payment type associated with these transactions, only the column of "coffee order". This data would best be stored in an OLAP.
Row-Level Storage: OLTP’s Best Friend
In row-level storage, data is stored one row at a time. This format is ideal for OLTP systems where applications perform frequent insert, update, and delete operations. Think of systems like banking apps, e-commerce platforms, or CRMs. They typically deal with individual transactions and need rapid access to complete rows of data.
For example, if you need to update a user's address or check their recent orders, you want the entire row , everything about that user, available instantly. Row-oriented databases like MySQL, PostgreSQL, and SQL Server are optimized for these tasks.
Key Advantages:
- Fast inserts, updates, and deletes
- Ideal for operations involving single rows or small row sets
- Lower overhead for transactional integrity
Columnar Storage: Powering OLAP and Analytics
Columnar databases, on the other hand, store data column by column. This is optimal for analytical workloads where you often need to aggregate values over many rows but only across a few columns.
Consider a dashboard showing average sales by region. A columnar store like Amazon Redshift, ClickHouse, or Apache Parquet can scan just the relevant columns (e.g., sales and region) across millions of rows far more efficiently than a row-based system.
Key Advantages
- Excellent compression due to similar data types in columns
- Fast aggregate queries across large datasets
- Ideal for read-heavy, analytic scenarios
Conclusion
Choosing between columnar and row-based storage isn’t about which is better—it’s about which is better for your workload. Use row-level storage for fast, reliable transaction processing (OLTP), and columnar storage when you need to crunch numbers across large datasets (OLAP). Modern data architectures often use both, with transactional data flowing into analytic systems through pipelines and ETL processes.
Understanding this distinction allows teams to design systems that are both efficient and scalable for their specific needs.