


Working with JSON is a common task in modern data engineering and API integrations. But while flat JSON structures are straightforward, real-world APIs often return deeply nested JSON objects - objects within objects, within objects, within objects...
Take, for example, the below Mailchimp campaign entity relationship diagram. A simple API call on campaign overviews returned a JSON structure with up to four layers of nesting, allowing for the creation of a 17-table snowflake schema.
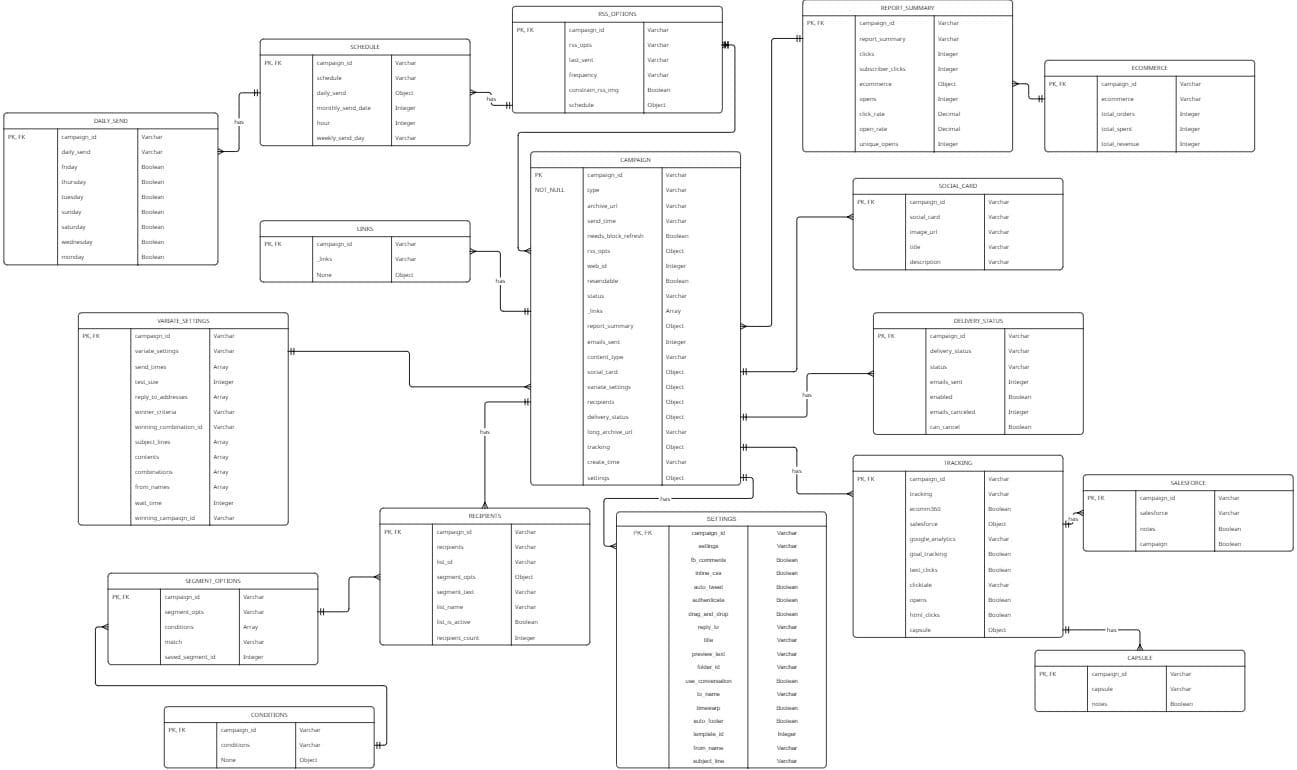
To manually write out the create table statements for each of these tables is a deeply time-consuming, manual, and prone to error task. It would involve knowing or finding out each of the data types for each of the columns, and hundreds of lines of code.
To combat this, notebooks within Snowflake utilising Python to recursively unpack JSON would allow for the unnesting, identification of datatypes, and the creation of tables. The full transformation script can be found at the base of this blog, attached as an .ipynb document.
Notebooks in Snowflake
Snowflake Notebooks are interactive, cell-based development environments embedded within the Snowflake Web UI - much like Jupyter Notebooks; they support SQL, Python, and Markdown, which allows users to combine data querying, transformation logic, and narrative commentary in a single document.
Notebooks can be found under the "Projects" header in the sidebar of the snowflake terminal.
Like with a normal Notebook or Python script, the first task is to import the required packages and establish the working session:

Before diving into the unpacking logic, it’s helpful to understand how SQL and Python work together in Snowflake.
SQL in Python
A quick aside to mention how SQL can be used in conjunction with Python.
Combining SQL and Python allows you to harness the best of both worlds - SQL for powerful, declarative data querying, and Python for flexible data transformation, analysis, and automation. Whether that is reading in snowflake tables into a Pandas DataFrame, injecting modular conditions into SQL scripts, or recursively unpacking lists.
In Snowflake, we use Snowpark to integrate Python and SQL. This allows us to forget about secrets, keys, and connections to our data. Running the below script, for example, would create a table in your Snowflake warehouse for the most recent week of data in your table.
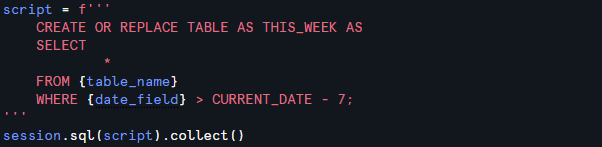
- The three ticks ''' dictate in Python that you are writing a block of text.
- The session object is instantiated using Snowpark’s
Session.buildermethod, allowing SQL queries to be executed programmatically within Python. - The .collect() runs your SQL code.
While this is a simple example, the ability to write these scripts opens a door for wider data creation and manipulation within Snowflake.
Code Breakdown
Functions
After you have established your session and imported the packages, it is good practice to separate your functions.
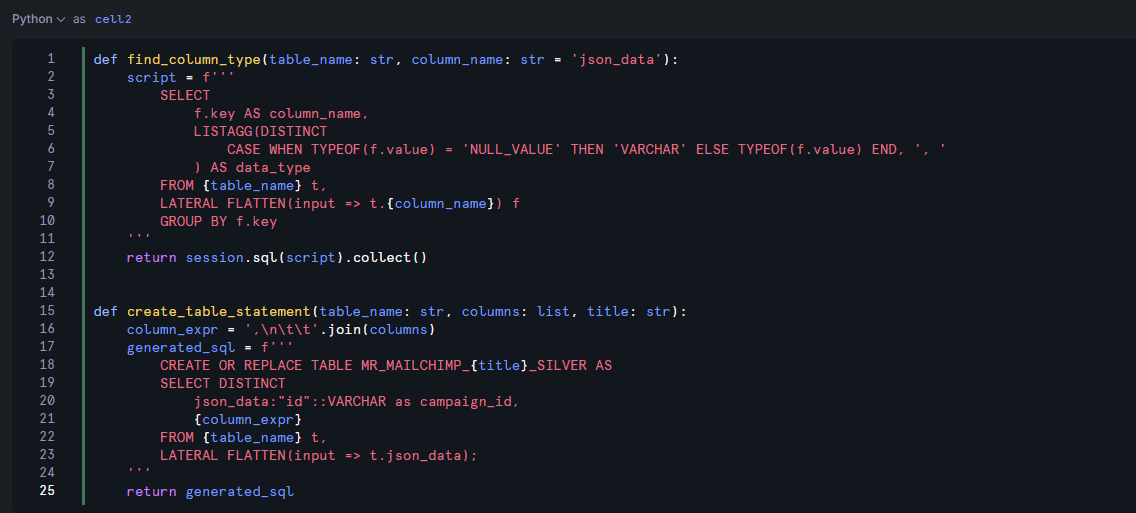
For unpacking JSON, I have two functions. While they initially look complex, they are quite simple. The first function find_column_type looks into the quoted table, flattens the JSON in a defined column, and separates the column headers using "f.key", and then finds the datatype of that column by looking at the values associated with it, and the SQL native TYPEOF() function. If there are no values, the function assigns the data_type as VARCHAR to stop any potential mismatches. The return of this function is an actioned SQL statement, meaning that the output will be the table created by this query.
The second function, create_table_statement, unpacks a list of column names (i.e. [Column X::VARCHAR as Column X, Column Y::VARCHAR as Column Y] into a create table statement. The output of this function is simply the fully qualified table in a created variable "generated_sql".
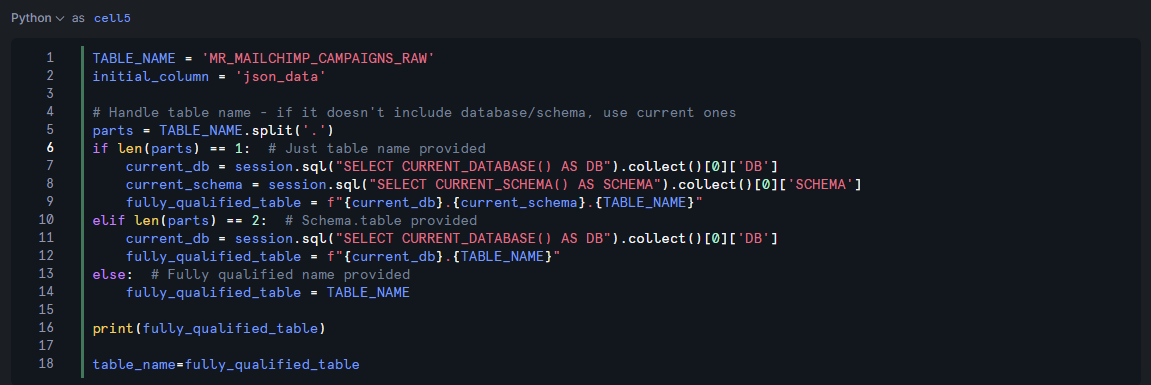
Table Name Qualification
The next block of code takes the user's input of table name and figures out how "qualified" it is. If the user has simply provided the table name, this code block brings in the current database and current schema, and assumes that the table exists where the user is currently working. If tables are being called from different schemas or databases, a more deeply qualified name is required.
Recursive Unpacking
This final code block is the real meat of the project, which will check if a table is ready for generation in SQL and create it if so.
If a scan of a table shows that a column is either an array or an object, then this column needs further unpacking; however, if the column is determined to be any other datatype, it is ready for table generation. Those that need further unpacking are added to the list, which is then recursively worked through until no values remain.
First, we simply set up the variables required for this process. A count is included for logging purposes, to provide the user feedback on the number of tables generated. An initial column is provided in the previous step, this is where we kick off the process from. This initial column is assumed to be a raw JSON export. We also create a set of visited columns to stop the script from rechecking JSON nest paths.

The next section begins the while loop, ensuring the loop continues while there are values in the "not_ready_columns". If there are values in this variable, continue the process until there are no more values. We add the column to visited at the start of the process, so it is not checked recursively if unneeded, and then we create the dynamic title of our future snowflake table. We then call upon our first function to check the data types of our columns.

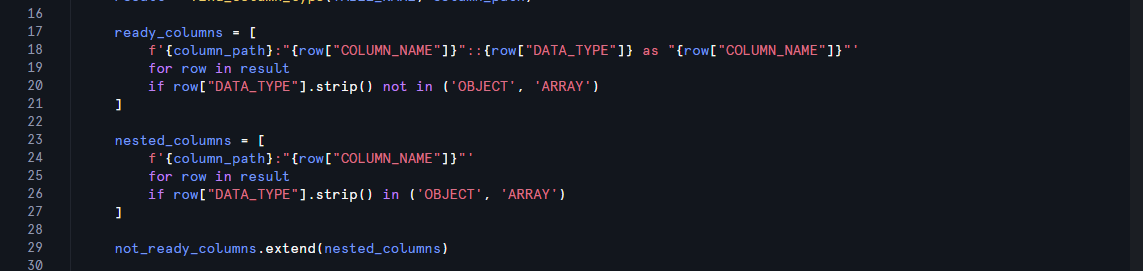
As described earlier, if these columns' datatypes are not an object or an array, then they are ready for table generation. This is scripted in the 'ready_columns' variable, which unpacks the resulting table from our function into a list. Each row from our resulting table returns a SQL-ready column definition like:
json_data:"archive_url"::VARCHAR as "archive_url"However, if the returning data is an object or an array, this column is added to our "not_ready_columns" function, which will be used to restart the process at the end of this loop.
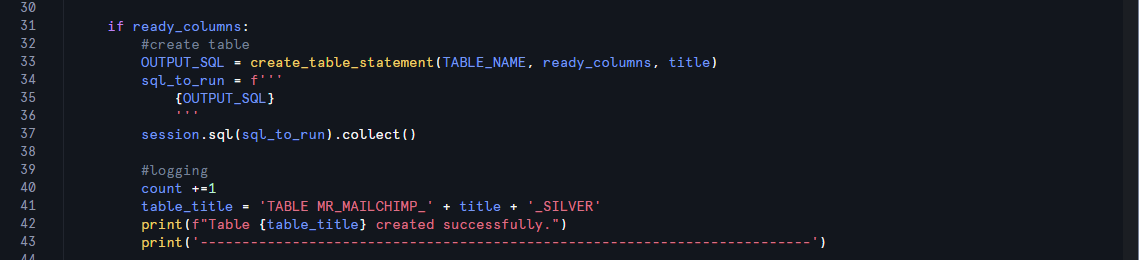
After the not_ready_columns has been updated, if there are any values in the "ready_columns", these are ready to be fully qualified as tables. We call upon our second function to generate the required SQL with these columns and a table name related to the path that we took to get there.
Some logging is then created to provide feedback on the created table, including how many were made.
A small excerpt from the print statement shows us that all of our tables have been created. We can now go into our Snowflake IDE and query these tables.

Conclusion
This approach dramatically reduces the time and complexity involved in ingesting and modelling deeply nested JSON data from APIs. With Snowflake Notebooks and Snowpark, you can automate recursive unpacking, dynamically generate SQL tables, and build a repeatable data ingestion pipeline for semi-structured data. As a next step, wrapping this process into a stored procedure or orchestrating it via a scheduling tool like Airflow or Kestra can help operationalise the workflow. These latter options, however, would require further connections to your Snowflake environment.
File:
GitHub Link to .ipynb file for recursively unpacking json for table creation in SQL