


This week we are strengthening our Alteryx skills. There are weekly exercises in the Alteryx community that are great as a learning resource and each of us are taking on one at a time and then presenting our solutions to the group. I worked on the exercise from week 13 yesterday. There are several interesting solutions on the forum page, so I want to add to that with my alternative. This is a great example of all the different ways you can get to the same results with Alteryx.
The task for this exercise is to take the HTML/XML input and transform it to a simple table of two columns with 14 rows. As I have never worked with XML before and don’t know much about HTML this was quite a challenge. If you are in a similar position I recommend copying the source code you are working on and pasting it to a word processor/text editor such as Microsoft Word or Sublime (which has the benefit of highlighting different parts of the code according to what they do, helping you to understand the structure). With an earlier version of this workflow I realised I hadn’t managed to import all the pairs I wanted and by investigating the source code and highlighting the values I had and those I didn’t have I managed to figure out what the problem was.
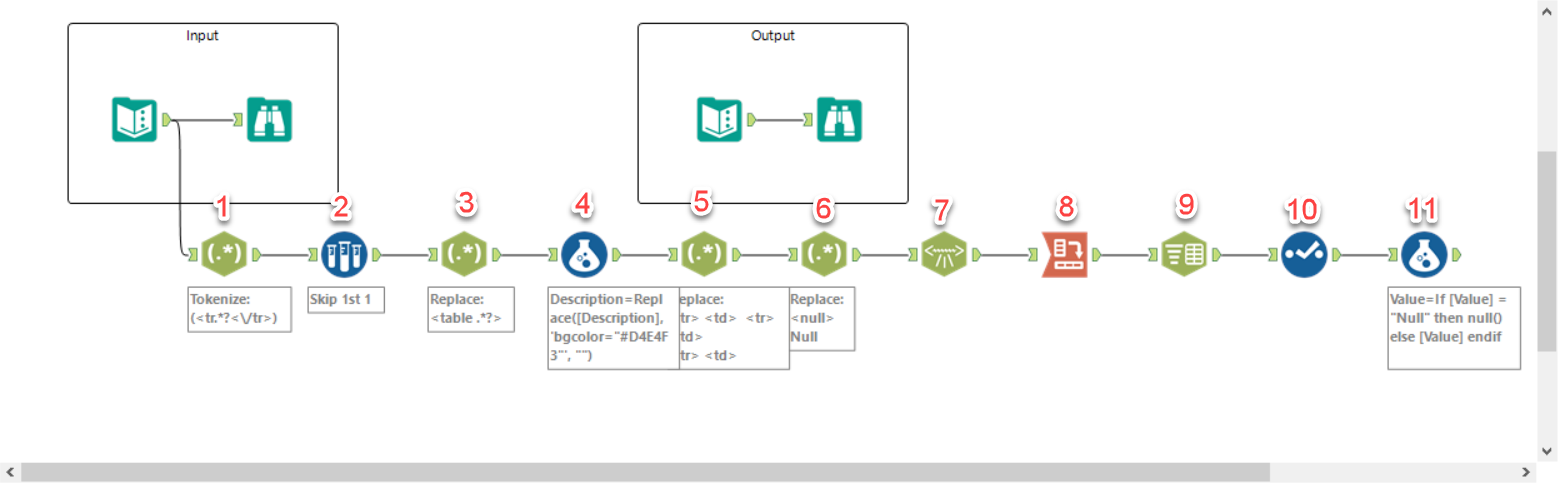
Final workflow for my alternative solution to Alteryx weekly exercise 13
My first reaction was to try the XML parse tool. However, this only works with some preparation as we still have some HTML code that the XML parse cannot deal with.
- Strip out the HTML bits that are not part of the XML we want. We use a RegEx tool to just keep everything between the first <tr> and the last </tr>
- The first record contains formatting data, which we can skip.
- One of the rows has both formatting information as well as data, so we take out the information that is not needed.
- Every second row includes an instruction for colour. This is replaced with a blank.
- In step 3 we took out the contents of the information we did not want but the tags are still there and are now removed
- Some fields are shown as <null>. The xml parse interprets these as a tag and creates an error as it cannot find a closing tag </null>, so this is replaced with the string “Null”.
- Now the xml is in a format that the xml parse can actually recognise and it creates a new column with just the informaton (stripping away tags).
- We need to split out the data to two columns. Grouping the data by the original xml rows (which each contain both the description and the data and are thus now duplicated and can be used as a grouping mechanism). The result is that the data is now concatenated in just one column.
- We split these to two columns, using the comma as delimiter
- Now we just need to delete the fields we don’t need and rename the ones we want to keep to match the solution output
- The final step is replacing the string “Null” with an actual null value.