


I've been getting stuck into the predictive suite offered by Alteryx and there are some great challenges from the Alteryx Community to help practice. This blog will be a walkthrough of (neatly) solving the Alteryx Weekly Challenge 132- which looks at predicting how long until the community page hits 1,000,000 posts.
The data we are given is quite messy, containing 'F1', 'F2', 'F3' fields. F1 and F2 can be converted to date form (Years and Months), but we first must tackle a problem with the first row of data. Since data is collected differently before 2017, the first row is a summation of all of the posts prior to 2017.
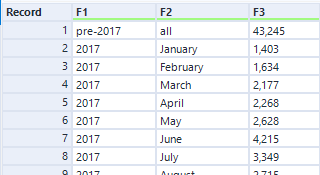
While we want to eventually skip our first value when doing ARIMA, we also need to keep the first field for when we do our running total calculation. So, if we create a formula for all of the dates first (keeping but ignoring the first row), we can then simply use a sample before using ARIMA to skip out that row. This saves us having to repeat the process twice before unioning our data together.
We first create our formula, and then use the DateTime tool to convert our values to a date. While this could be done in 1 (slightly messy) formula, I think it makes more sense to do it in 2 steps, for clarity.

We now have a formatted date field, and can just get rid of our F1 and F2 fields keeping our DateTime_Out (renamed to Date) and F3 (renamed to Value).
We are now ready to use the ARIMA tool from the Time Series pallette. Our target field is Value, and we are using a monthly frequency (ie, we want to predict monthly values as out data is in a monthly format). We then want to use a TS Forecast tool to predict our future values. The challenge specifies using a 80% value for our larger confidence interval, which can easily be configured in this tool.
TS Forecast outputs values in a slightly different format than we require. It returns a [period] (year) and [sub_period] (month) column, with the forecasted outputs (4 in total, indicating 2 x upper and lower confidence predictions). Therefore, we need to only select our [forecast_high_80] field, which will be the value we are using for our prediction.
We next need to define some logic to re-format our period and sub-period data. Fortunately, this is pretty simple (well, for the year field).
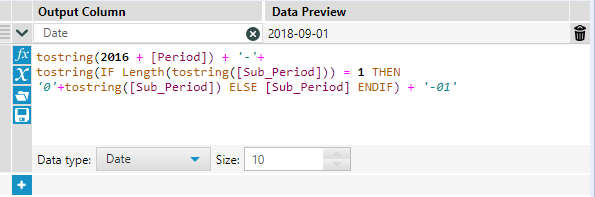
Breaking this formula down:
tostring(2016 + [Period])
This gives us our original year field. We add our Period value (for example 2) to 2016, which gives us 2018 (the first prediction year from our ARIMA forecast). We wrap this in 'toString()' because we need to concatenate our values together to make a date field, and [Period] is currently in the integer format
tostring(IF Length(tostring([Sub_Period])) = 1 THEN '0'+tostring([Sub_Period]) ELSE [Sub_Period] ENDIF) + '-01'
Slightly more confusing... Sub period is outputted as '1' instead of '01', but we need to have that zero to the left for any Sub_periods where the length of the string is just 1. This means that when we convert it to a date, it will not throw an error. So what we do is say that if the length of [Sub_Period] is 1, then return 0 + [Sub_Period], otherwise return [Sub_Period]. We need to wrap these in strings since [Sub_Period] is also an integer. Finally, we add '01' which indicates the first day of every month. We can then select the data type as 'Date', and it will cleanly format the data to the date format.
Before unioning the data back together, we just need a select tool to clean it all up. Untick all fields except [Date] and [forecast_high_80] and we are nearly ready.
Since we want to incorporate the 'pre-2017' value into our running total to calculate the date we reach 1,000,000 viewers, we need to repeat the date process again but including our 'pre-2017' field. Thankfully, all we need to do is drag the output from our Date time function (before the sample tool), only keep [DateTime_Out] and [F3], renaming them to 'Date' and 'Value' respectively, and then we are ready to union our data.
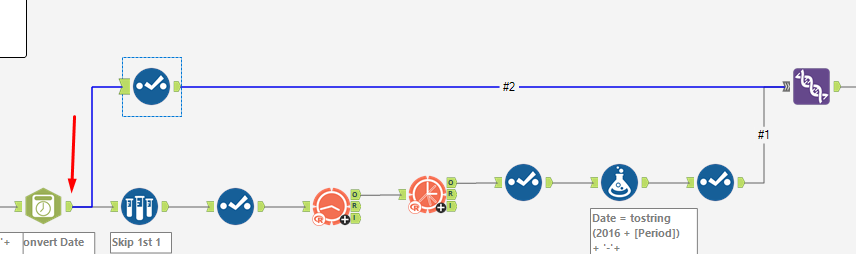
Next, drag a union field onto the canvas, and 'manually configure fields'. We want to union date on top of each other, and [forecast_high_80] and [Value] on top of each other. However, a quick note. We need our original data to be first, followed by our predictions. This is because our values need to be chronological when using our running total tool. To prevent needing an additional sort tool, make sure the output order is specified manually. In my case, I needed #2 to be above #1, since #1 is my ARIMA predictions, and #2 is the original dataset.

We are nearly done, and all we need to do is use a running total on our value, and finally filter our value for when it reached >= 1,000,000. This will return all rows that have a value of over 1,000,000, the first should be 2023-06-01. Since we only need this value, a sample tool taking the first row solves this for us!
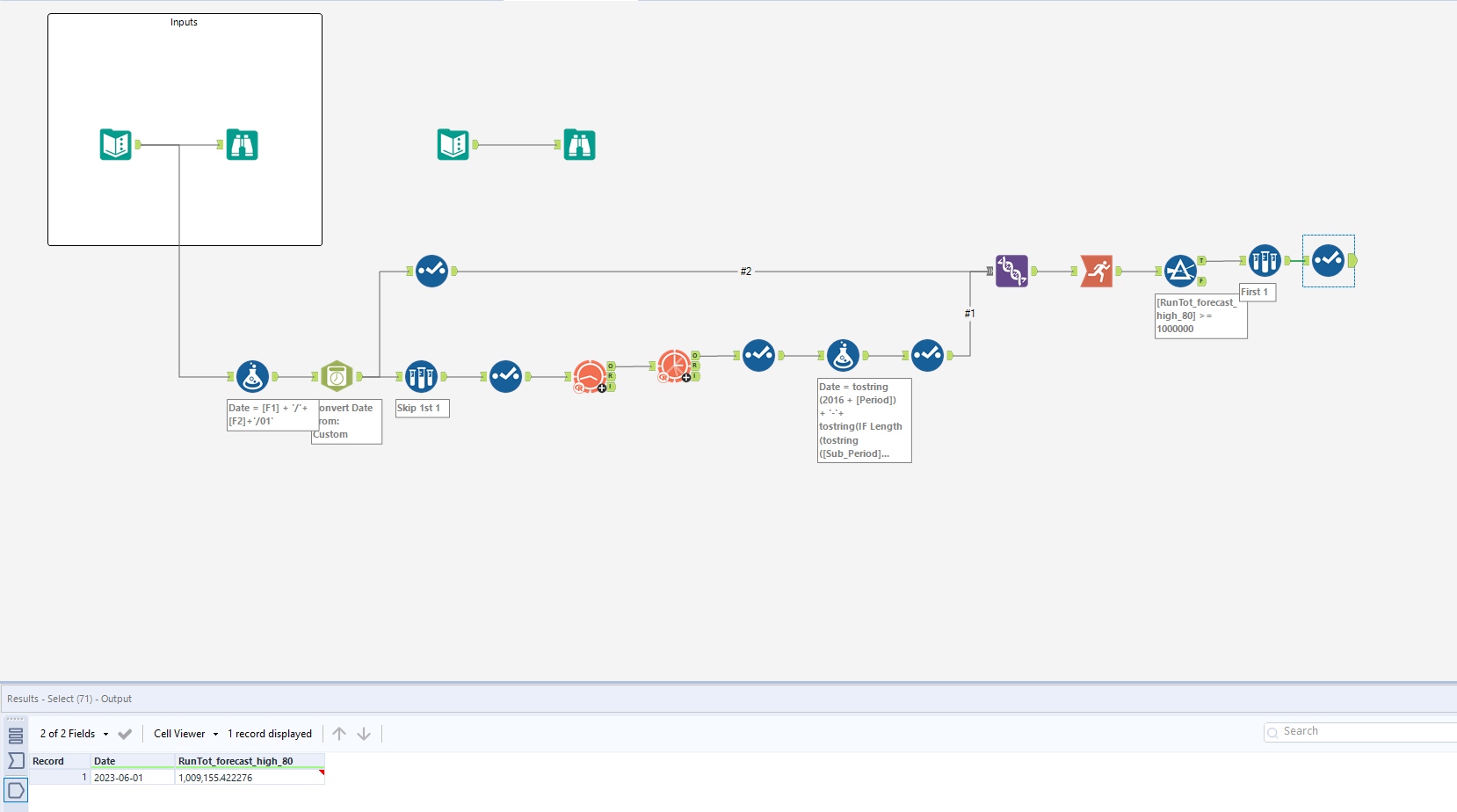
I found this really useful when learning how to use predictive tools, especially understanding the correct configurations.