


Reflections of Alteryx Challenge 19
I racked my brain to find a solution for challenge 19. It was harder than first anticipated. But after an hour of toiling, I did find a solution. However, a small voice in my mind was annoyingly informing me that my solution was probably not the most efficient or replicable. At first, I told the little voice ‘HOW DARE YOU! THIS IS THE BEST SOLUTION EVER!’. But I relented, and checked the Alteryx community website. Lo and behold, the real solution was elegant. A thing of beauty.
The Task
A fictional client has 100’s of XLS files (although we are given only 2 for the challenge), with a sheet in common. The task is to read across all the files and return values in specific cells - Row 2, Column 3 and Row 8, Column 2 from Sheet1 in each XLS workbook. The result should be a table with 3 columns: XLS File, Row2_ Column3, and Row8_Column2.
The Problem
When inputting the files, a problem becomes quickly apparent. The field in one book that may have been a row number, goes up in increments of 2 in another book. This facilitates a need for a standardized row number (i.e., 1, 2, 3…).
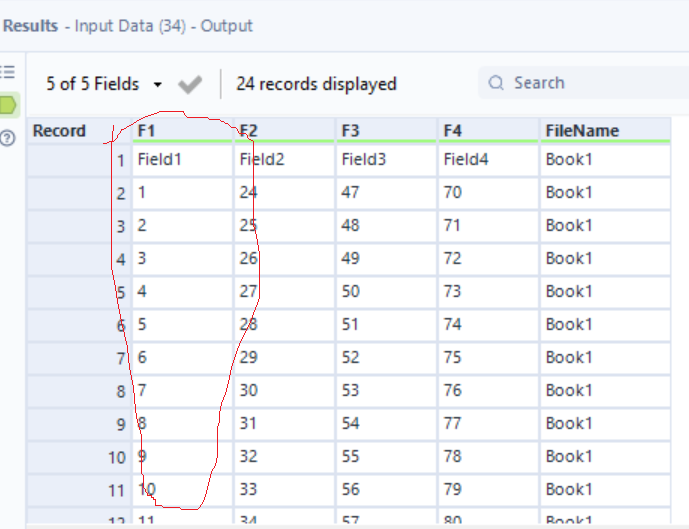
Another problem, for me at least, was not knowing how to separate a specific row and column, removing everything else. This part took me the longest time to solve.
My Solution
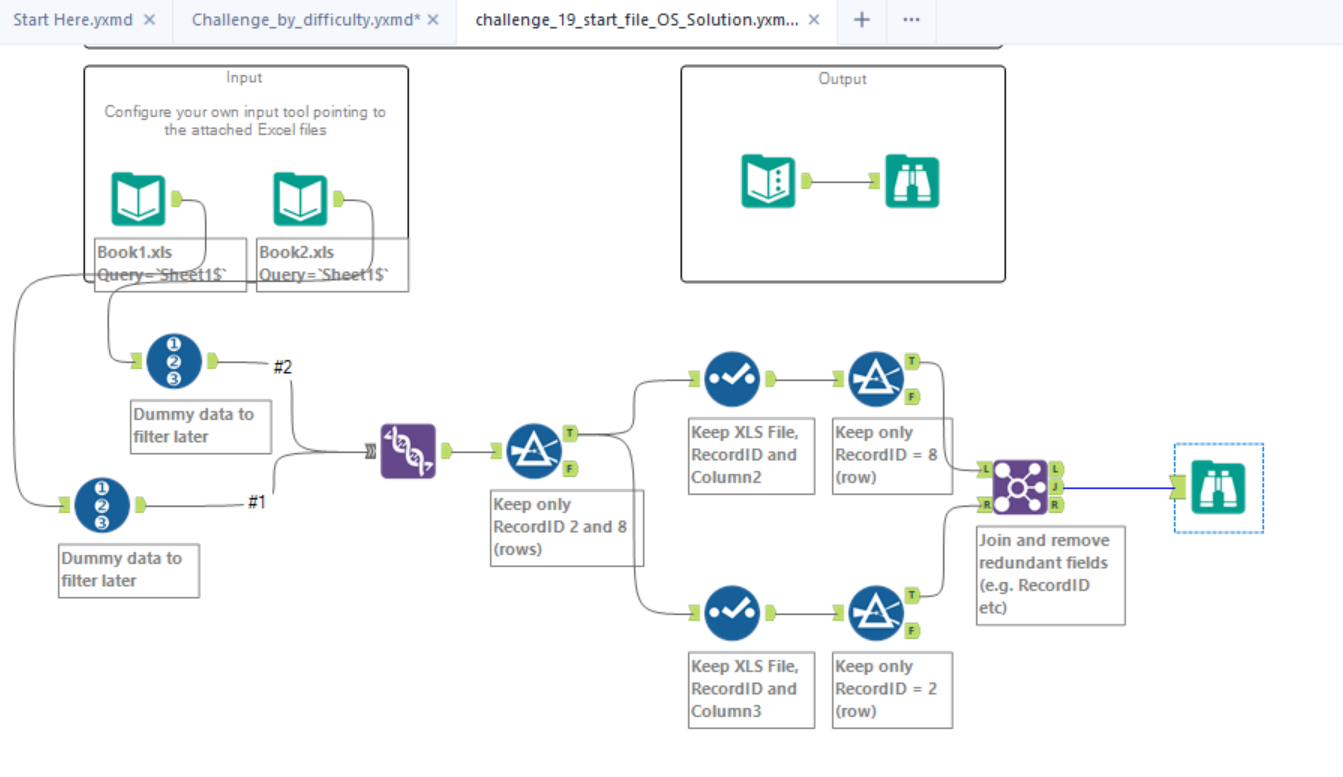
The inefficiency of my solution started from the very beginning. Two things eluded me while inputting the data: the scope had mentioned 100’s of XLS files, so I had not taken into consideration the fictional client’s needs; Robbin had showed us, on the first day of Alteryx fundamentals, how to input files with similar names e.g., Book1, Book2.
A reason I had inputted the files separately was because I had also forgotten that I could do a multi-row calculation to count rows if there is a common pattern to reset the count on. In this case, the pattern was the file name, which I had inputted with the file.
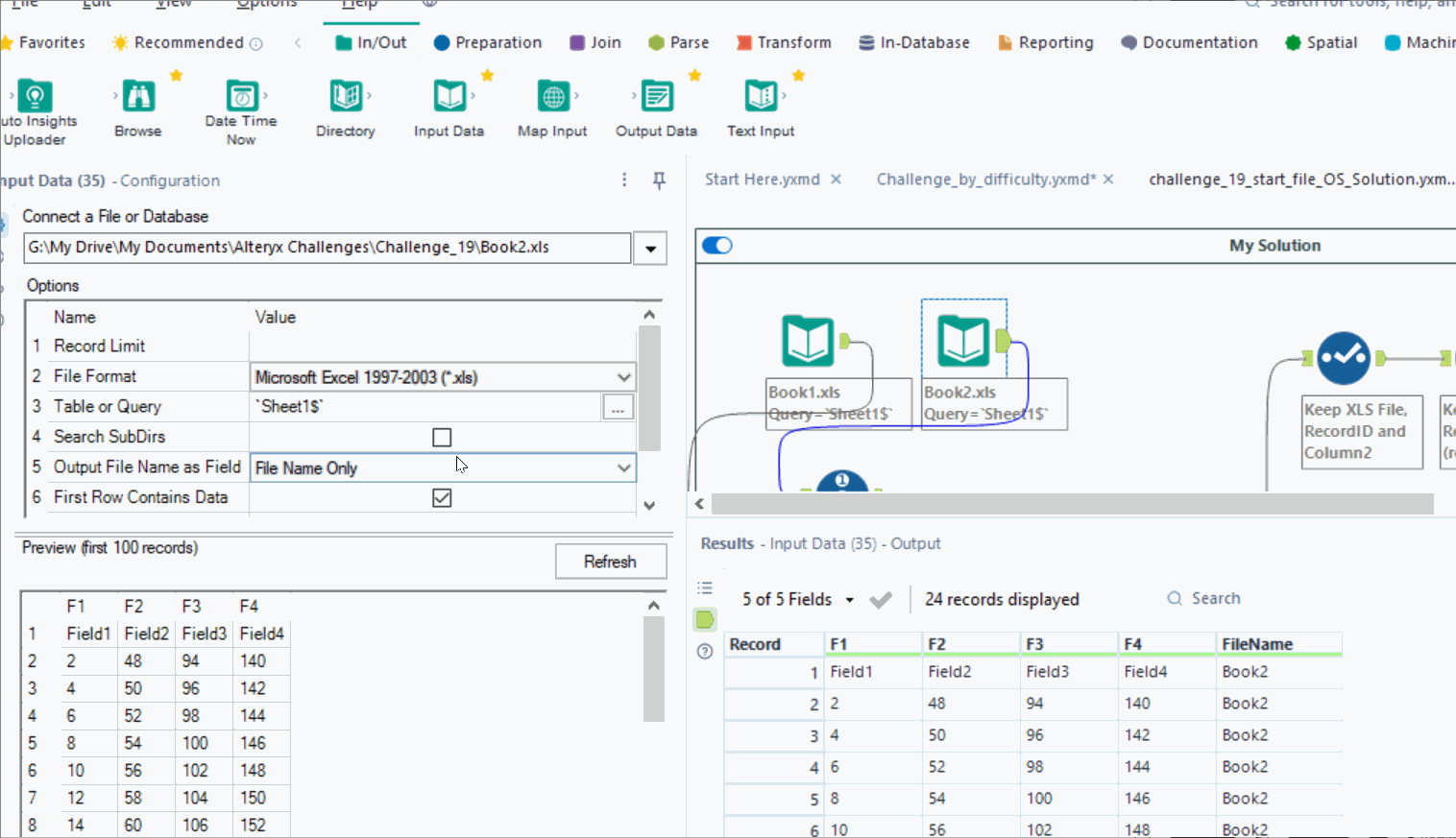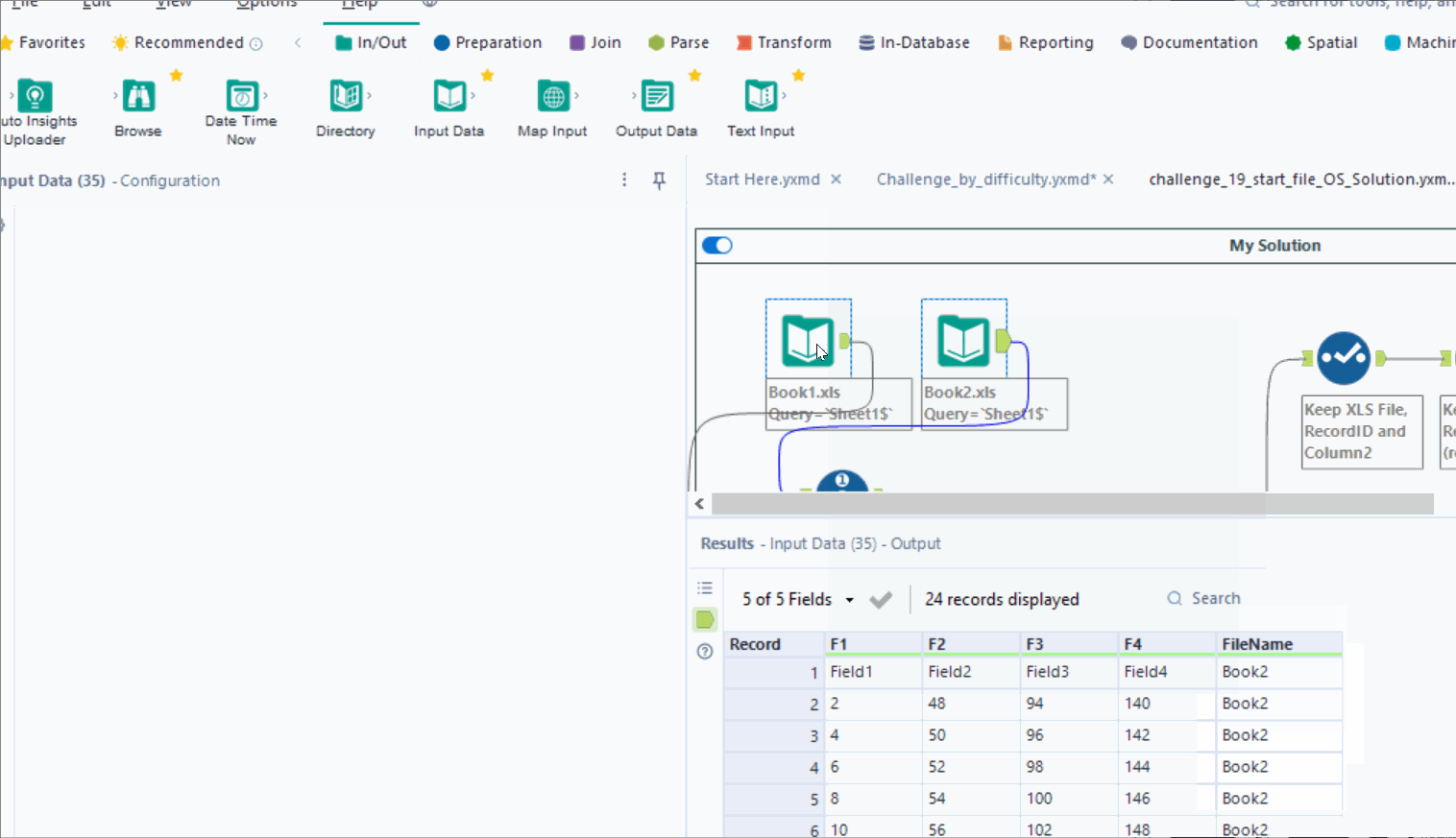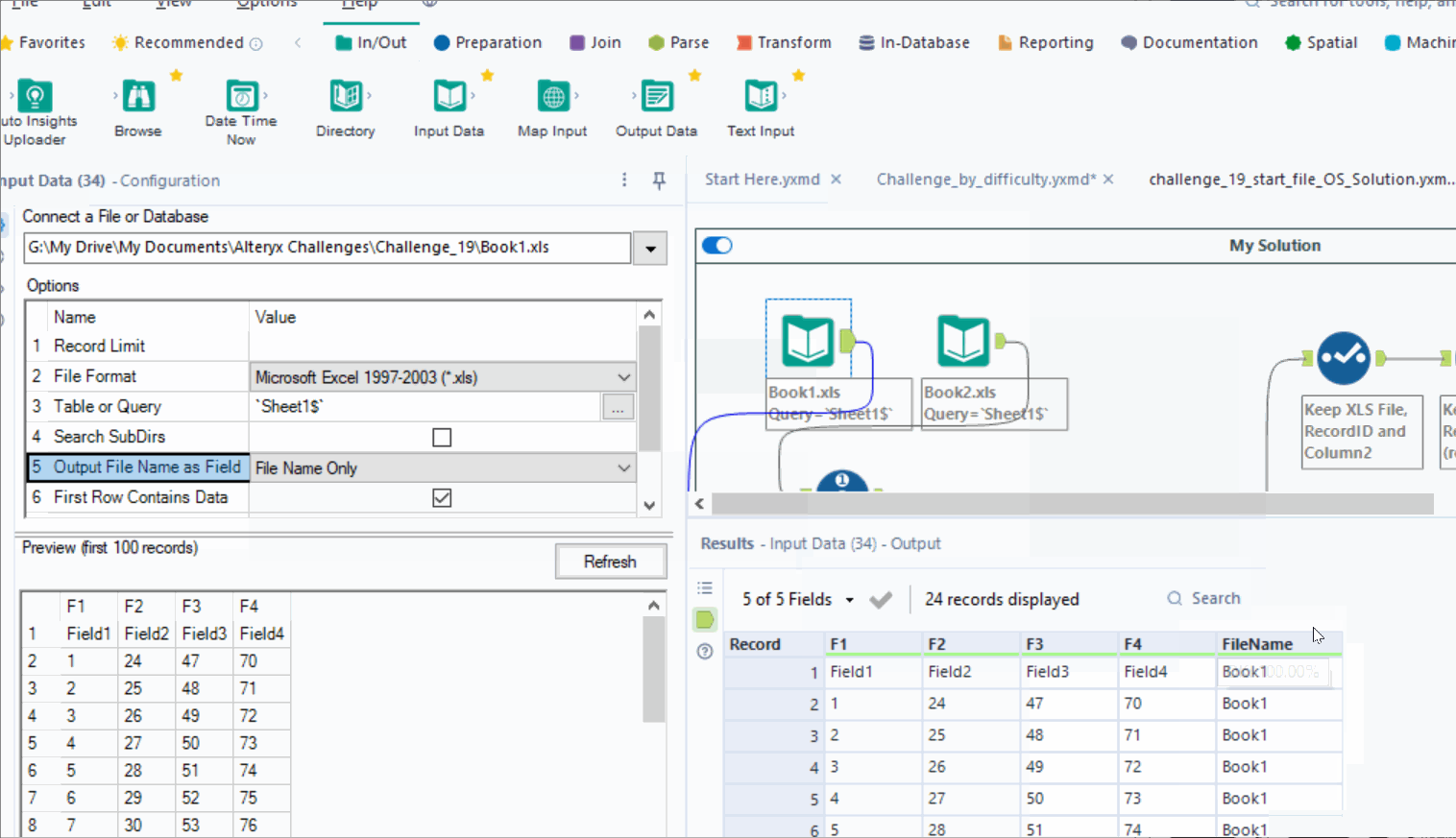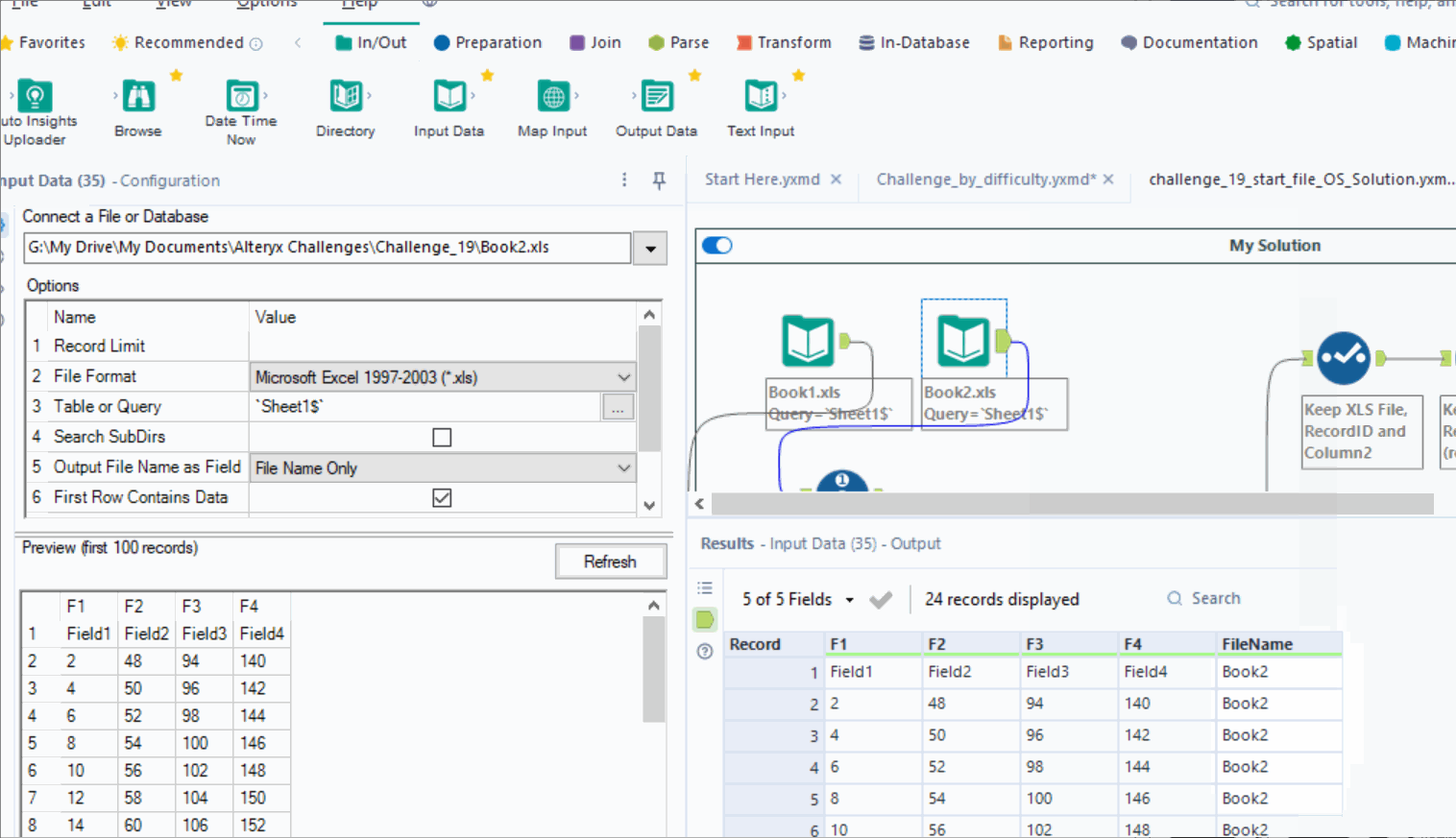
The inefficiency then spiraled from there. I used a RecordID tool on both inputs to create a row count for each file. I stacked the data with a union and filtered RecordID by the rows needed: 2 and 8. I separated the columns so I could manipulate the columns independently of each other. I filtered again and finally joined on the file name and finally had a solution. If that seemed convoluted to you, it’s because it was. And worse still, it was unnecessary complication. My solution takes 1.5-2.6 sec to run.
The Alteryx Community Solution
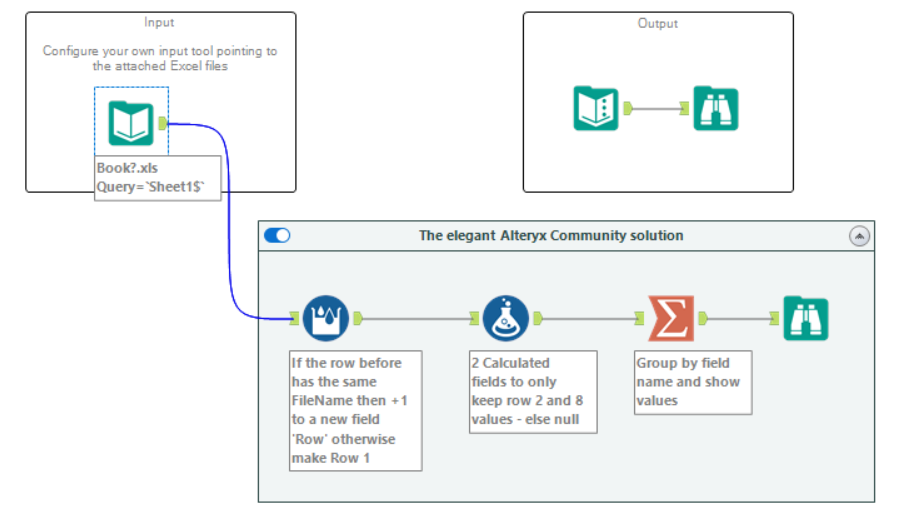
The difference between the solutions is very stark. The clearest difference is the number of tools they have used: 5, compared to mine with 12 tools. The aspect of this solution I like the most is the dexterous use of the tools to accomplish many things at once. From the Input to the Summarize, each tool is used with necessity in mind. The Alteryx Community solution takes 1.0-1.6 sec to run.
Takeaways
The difference in run time may not seem big now but if given 100’s of files, as the use case of this challenge suggested, the difference is certain to expand. I am a sucker for complication. My mother always used to tell me, if instructed to touch my right ear, I shouldn’t try to touch it with the opposite arm over my head. In other words, keep it simple, stupid. That may be a running theme while working with data,
On a personal, but related, side note, I have used the Multi-row Calculation tool before, in Challenge 9, Analytic Ranking, but I evidently do not know how to use it properly. So, you can expect to see a blog about how to use the Multi-row Calculation tool very soon.
TLDR: I did Alteryx Challenge 19, but the Alteryx community solution was simpler. I learnt a lesson in simplicity.