Wikipedia is full of interesting and structured data, so why not get it to use in a visualisation? In this blog post I go through my first experience scraping Wikipedia

This week we have played around ways to use APIs in Alteryx. If you have never heard about APIs or don’t know exactly what it means, API is the acronym for Application Programming Interface.
In other words, they are a kind of structured way to help an application “to talk” with another (a more complete explanation here).
After trying several APIs without finding something cool to build, I remembered that I was with a bunch of Wikipedia’s links to scrape. I got them from Wikipedia itself, from a page with a list of Brazilian samba musicians.
Scraping the list, I got 242 rows, each one containing the name of a singer and also a link to his/her page in Wikipedia. My idea was to complement this data with date and place of birth, as well as date and place of death.
First step: How to connect to Wikipedia
As it was my first time working with Wikipedia, I started the project with a very basic task: researching ways to connect to Wikipedia. 🙂
With a little help from Google and Anna Noble (who have recently gone to a presentation about the subject) I discovered that there is an API to do that.
Actually the API requests data from Wikidata, not exactly from the Wikipedia pages you see when you search on the website. Wikidata, as they explain in its toolkit page, is a project kept by the same group responsible for Wikipedia (the Wikimedia) that aims to gather data from all Wikipedias and many other projects in a single location.
As a result sometimes you will not find exactly the same information in both, Wikipedia and Wikimedia, however if you would like to be a good Samaritan, you can add the data additional data found in Wikipedia to the entry in Wikidata.
Back to the tutorial, the first thing to connect to Wikidata is to call the API, what you can do from the URL:
https://www.wikidata.org/w/api.php?
Second Step: Picking the right format
When calling the API using the mentioned address the answer received is in HTML, which is not the best format to work with data.
For this reason, a good second step is to add a command saying that you would like to see the data in Jason format, not in HTML. It can be done adding “format=json” to the end of the original request, like in the URL below.
https://www.wikidata.org/w/api.php?format=json
Third step: Understanding the data
When you access pages about people in Wikipedia they usually have the same structure: which Wikipedia you are searching, then ‘wiki’, then the name of the person.

Wikidata will use exactly the same name as seen in Wikipedia (they are “titles”), which make easier to structure the calls. For instance, the call to the Wikipedia page above in Wikidata is
https://www.wikidata.org/w/api.php?action=wbgetentities&sites=ptwiki&titles=Adalto_Magalha
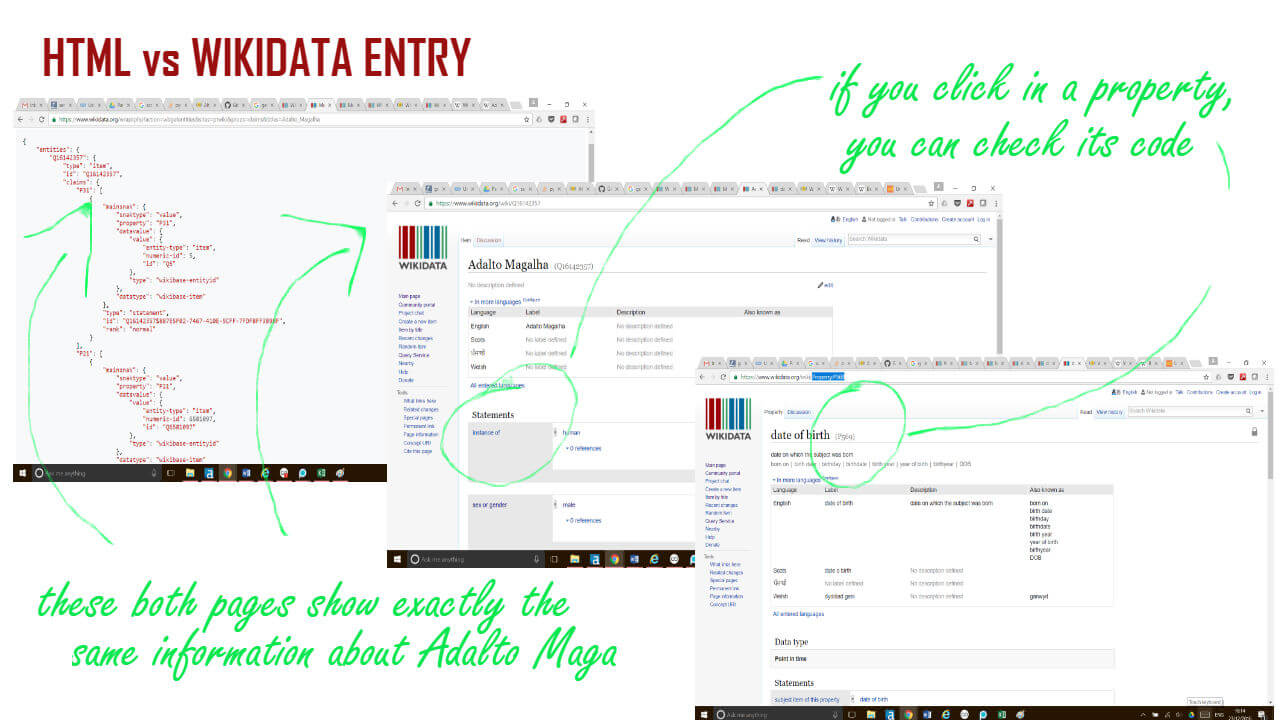
And the resulting HTML is what you see in the image below:

Notice that I’m orienting my search to “ptwiki”, once the content I’m interested in is almost all published by Brazilians, in Portuguese. If you are interested in content in other languages, you should edit this part.
For each title, Wikipedia will attribute an ID, which is the unique reference for each entry. It means that each one of the singers I am looking for will have an ID, as well as each city or country.
It is important to notice because in the answer to the request, the names of places will not appear, but rather the ID used to register the entry in the database.
So, don’t panic if you don’t find the name of the city where the person was born the same way you see in Wikipedia. The information is still there, but now as an ID formed by the letter “Q” + a series of numbers.
For instance, the city I was born, Belo Horizonte, is registered as Q42800. Brazil, the country where I’m from, is Q155. Noel Rosa, one of my favourite samba compositors is Q281078.
Fourth step: Discovering which are the properties you are interested in
Now that we already know how to call the API and get the data and also how the ID system works, another important step is to figure out where exactly is the information we are looking for, or, saying in a better way, which are the properties we are interested in.
The same way Wikidata gives an ID to each entry, each one of those entries will have properties. For instance, if the entry is a person, she/he can have a sex or gender, a day of birth, a place of birth, a country of citizenship etc.
If the entry is a city, it can be part of a country, have a population, a coordinate location, a time zone etc…
Do you remember that IDs are identified by Wikidata as strings formed by “Q”+ a series of numbers? In a similar way, each property is identified by a “P” followed by numbers.
For instance, I can share here the properties I used to do my search:
- Date of birth is Property:P569
- Place of birth is Property:P19
- Date of death is Property:570
- Place of death is Property: P20 and
- Country of Citizenship is Property: P27
Fifth step: Requesting data about places
Once I filtered the result of my request to get only the properties needed, it was necessary to send a second request to Wikidata to get the name of the places (countries and cities). After all, it doesn’t seem a good idea to create a visualisation showing that someone was born in Q155, isn’t it?
This second request was slightly different from the first one I showed. In the first one I had the pages’ titles. Now instead of titles I have IDs and would like to know which is the title related to each ID.
Luckily, there are no secrets to do that. The only thing to be altered is the end of the statement, changing “titles” to “ids”.
https://www.wikidata.org/w/api.php?action=wbgetentities&ids=
FINAL TIP: One thing that makes the process much easier is to keep a page showing the result of a request in HTML as well as the Wikidata’s page for the entry. Each helped me a lot to get a grasp of how Wikidata is structured, as well as discover exactly the number for each property.
Well, I hope to write a second blog post in the same topic, touching on the way I used Alteryx to get and to clean the data, but it will happen only after Christmas. So Happy Christmas everyone and share your knowledge about scraping below!