


In diesem Blog möchte ich schrittweise erklären, wie man eine explorative Datenanalyse durchführen kann. Dafür benutze ich einerseits den bekannten Titanic-Datensatz. Diesen kann man hierrunterladen. Außerdem werde ich für meine Analyse ausschließlich Alteryx verwenden, da es wesentlich komfortabler für die Datenvorbereitung ist als zum Beispiel Python.
Was ist explorative Datenanalyse (EDA)?
Die explorative Datenanalyse ist ein Schritt im Datenanalyseprozess, der dabei hilft, einen Datensatz besser kennenzulernen. Um einen ersten Eindruck über die Daten zu bekommen, werden dafür Methoden der Visualisierung als auch statistische Maße verwendet. Diese helfen dabei wesentliche Fragen zu beantworten wie…:
- Wie ist die Verteilung meiner Variablen? (Schief-verteilt, normalverteilt, hügelförmig, binomial ….)
- Wie sind die Zusammenhänge einzelner Variablen
- Gibt es Ausreißer oder ungewöhnliche Punkte?
- Wie verhalten sich die Daten im Zeitverlauf? Gibt es ein Muster?
Das Ziel der EDA sollte es sein, Zusammenhänge in den Daten zu finden, Hypothesen zu generieren und Ursachen für mögliche Entwicklungen zu identifizieren.
Komponenten einer EDA
Für eine explorative Datenanalyse kann man drei Schritte festhalten: Verständnis der Variablen, Bereinigung der Daten und anschließend die Analyse der Zusammenhänge zwischen den Variablen. Dann beginnen wir mit der EDA.
1. Variablen verstehen
Im ersten Schritt geht es darum, die Variablen zu verstehen. Wenn man nicht die Spalten und deren Inhalt nicht versteht, dann helfen gefundene Zusammenhänge nicht weiter.
Um die Variablen zu verstehen, sollten wir erstmal die Frage beantworten, wie viele Zeilen und wie viele Spalten unser Datensatz eigentlich umfasst. Darüber Hinaus hilft es auch zu wissen, welche Variablen wir eigentlich zur Verfügung haben. An die Information Anzahl der Zeilen und die Anzahl der Spalten kommt man ganz schnell über das Browse-Tool.

Das Browse-Tool zeigt an, dass in diesem Datensatz 1309 Zeilen und 14 Felder (Variablen) vorkommen. Jetzt möchte ich einen genaueren Blick auf die Daten werfen. Dafür eignet sich in Alteryx die Data Investigation Tool-Palette.

Diese Tool-Palette stellt mehrere Tools zur Verfügung, die dabei helfen, die einzelnen Spalten besser zu verstehen. Ein Tool davon ist das „Field Summary“-Tool.
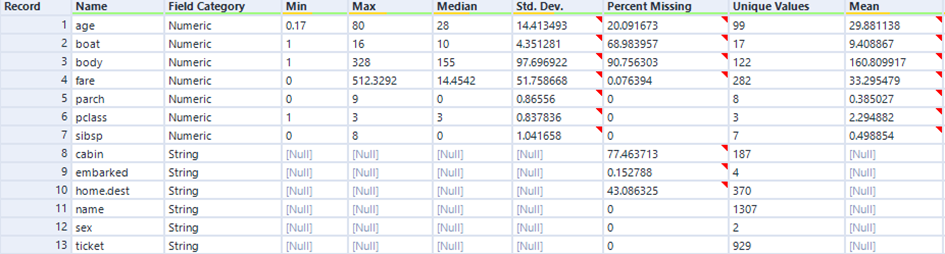
Das „Field-Summary“ Tool fasst essenzielle Informationen für das Datenverständnis zusammen. Ein Output für diesen Datensatz ist folgender:
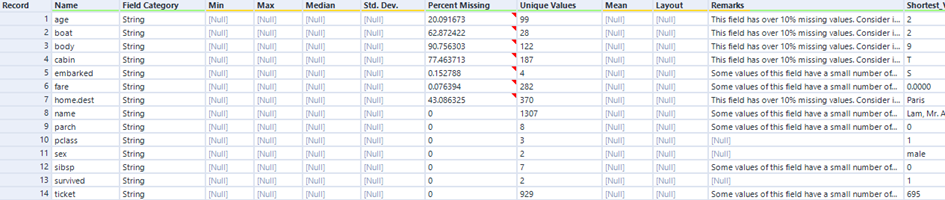
Wir erkennen direkt, welche 14 Variablen in unserem Datensatz sind. Wir beobachten auch, dass alle Variablen als String gespeichert werden, was wir im Laufe der Analyse verändern sollten. Da alle Variablen vom Datentyp String sind, werden die Spalten Min, Max, Median und Std. Dev. mit Nulls gefüllt. Bei den ersten sieben Variablen der Liste fehlen Daten. Während bei „fare“ und „embarked“ nur weniger als 1% fehlen, sind es bei „cabin“ und „body“ über 75%. Ich werde in Schritt 2 auf die fehlenden Daten eingehen. Bei der Spalte „Unique Values“ fallen mir direkt 2 Dinge auf:
(1) Die Variablen „sex“ und „survived” haben nur zwei Ausprägungen, daher wird es sich um boolische Variablen handeln. Demzufolge wird „sex“ vermutlich die Ausprägung 1,0 (M,W) haben und „survived“ wahrscheinlich 1 für überlebt und 0 für verstorben.
(2) Wir wissen durch das Browse-Tool, dass wir 1307 Zeilen im Datensatz haben. Wir können hier erkennen, dass die Variable „name“, die vermutlich die Information über den jeweiligen Passagier enthält, 1307 individuelle Ausprägungen hat. Da die Anzahl der Zeilen gleich der Anzahl der Passagiere entspricht, können wir die wichtige Frage „Was bedeutet eine Zeile?“ beantworten, nämlich eine Zeile entspricht einem Passagier.
Bevor ich nun zu Schritt 2 übergehe, passe ich die Datentypen mit einem Select-Tool an.
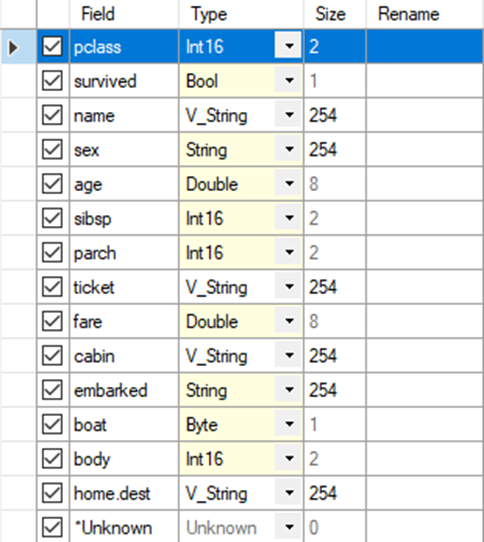
Das Select-Tool kann benutzt werden, um Spalten zu entfernen, Spalten umzubenennen oder den Datentyp von Spalten zu ändern. Ich muss hier anmerken, dass ich mir jede einzelne Spalte geprüft habe, um zu verstehen, was die jeweilige Spalte eigentlich aussagt. Erst wenn man das weiß, kann man den Datentyp optimal anpassen. Nun werden bei den numerischen Spalten im Field Summary-Tool auch die entsprechenden Statistiken angezeigt.
2. Bereinigung der Daten
a. Entfernen redundanter Variablen
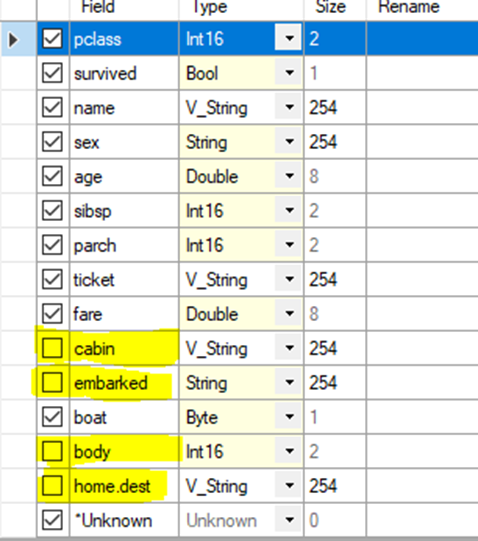
Ich werde mich hier von den Feldern „embarked“ und „body“ trennen. Zwar könnte bezüglich „body“ die Frage interessant sein, wie viele Leichen nicht geborgen werden konnten, aber dennoch entferne ich diese Spalten aus meinem Datensatz.
b. Variablenauswahl
Da in der Spalte Cabin 77% der Daten fehlen und ich keinen großen Wert sehe, diese Spalte zu behalten, werde ich diese auch entfernen. Mit 43% fehlenden Daten entferne ich auch „home.dest“.
Da „boat“ nur einen Wert enthält, wenn der entsprechende Passagier überlebt hat, und diese Spalte Antworten auf interessante Fragen liefern kann, werde ich diese Spalte beibehalten.
Ich verwende mein Select-Tool, das ich bereits für die Veränderung der Datentypen genutzt habe, und entferne die Haken bei den Spalten, die ich nicht mehr weiter betrachten möchte.
c. Zeilen mit Nulls entfernen
Für diese Operation eignet sich das Data Cleansing-Tool.
Das Data Cleansing Tool bietet verschiedene Möglichkeiten an Spalten zu bearbeiten.
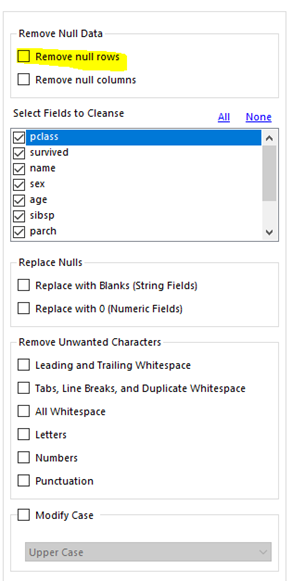
Im Moment interessiert es aber nur, die Null rows zu entfernen.
Da wir nun den Datensatz bereinigt und angepasst haben, können wir uns auf die Suche nach den ersten Zusammenhängen begeben.
3. Die Analyse von Beziehungen zwischen Variablen
Heat Map/ Highlight Table
Fangen wir mit einer Heatmap an. Dafür verwenden wir das Contingency Table Tool.
Dieses erlaubt uns aus 2 bis 4 Variablen verschiedene Visualisierungen zu erstellen. Stellen wir uns also die erste Frage: Hat tatsächlich die dritte Klasse die schlechtesten Überlebenschancen?
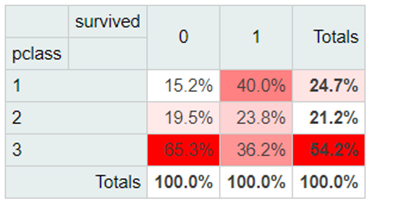
Man kann hier deutlich erkennen, dass sich alle Passagiere zu 54,2% aus Menschen der dritten Klasse zusammensetzen. Darüber hinaus stammen 2 von 3 Verstorbenen aus der dritten Klasse. Das muss allerdings nicht heißen, dass die Überlebenswahrscheinlichkeit in der dritten Klasse besonders gering war. Es könnte auch einfach bedeuten, dass die meisten Passagiere sich ein Dritte-Klasse-Ticket gebucht haben. Für die Frage der Überlebenschancen dient folgende Highlight-Tabelle:
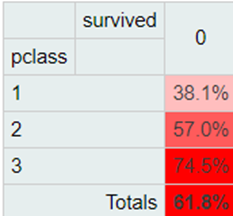
In der dritten Passagierklasse ist man mit einer doppelt so hohen Wahrscheinlichkeit verunglückt, wie in der ersten Klasse.
Korrelationsmatrix mit Scatterplot
In Alteryx gibt es das Association Analysis Tool, das Korrelationsmatrixen und Scatterplots erstellt.
Der I-Output liefert eine interaktive Korrelationsmatrix. Klickt man auf ein Feld in dieser Matrix, passt sich der Scatterplot auf der rechten Seite an.
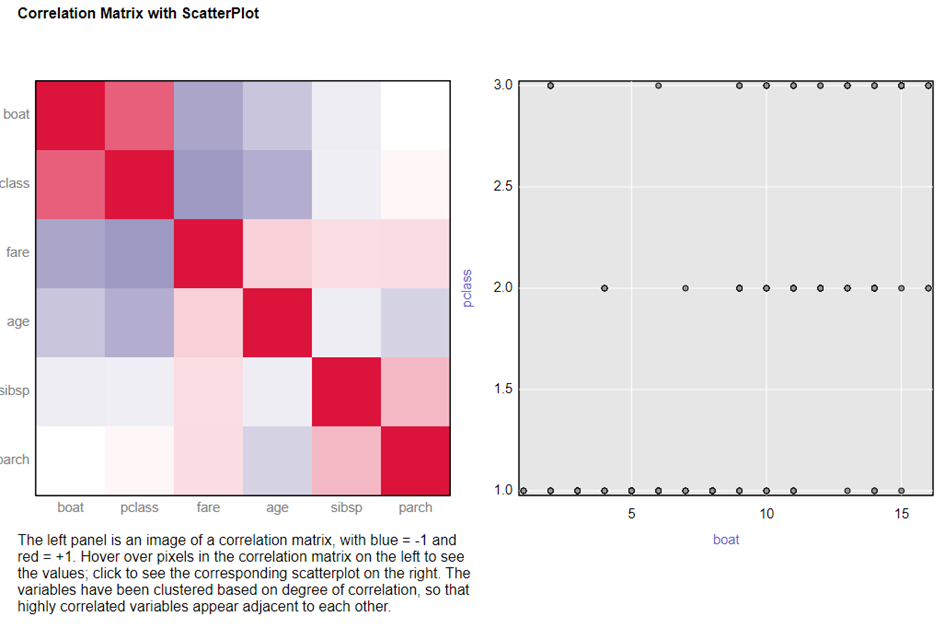
Je dunkler die Farben sind, desto höher ist die Korrelation. Blau steht für eine negative und Rot für eine positive Korrelation. Hier kann man etwas sehr interessantes beobachten: Eine relative hohe positive Korrelation zwischen der Passagierklasse und der Bootsnummer. Scheinbar gibt es wenige aus der zweiten und dritten Klasse, die „niedrigere“ Bootsnummern erwischt haben. Wollten die Vermögenden etwa unter sich sein?
Wenn die Bootsnummer die Reihenfolge angibt, wann die Boote ins Wasser gelassen wurden, dann scheinen die ersten Rettungsboote fast ausschließlich mit Passagieren der ersten Klasse gefüllt zu sein. Das könnte viele Gründe haben: Vielleicht wurden die Boote, die bei der ersten Klasse stationiert waren, als erstes ins Wasser gelassen. Vielleicht landete die Information, dass das Schiff sinken würde, zuerst bei den Passagieren der ersten Klasse. Vielleicht waren einige Offiziere empfänglich für eine Geldspende. Es gibt viele mögliche Erklärungen für diese Gruppierung, aber keine kann man mit Sicherheit bestätigen. Fakt ist, dass es diese Gruppierung gibt.
Histogramm
Wie ist die Altersverteilung der Überlebenden im Vergleich zu der Altersverteilung der nicht Überlebenden. Dafür verwenden wir das Filter-Tool und das Histogramm Tool.
Mit dem Filter-Tool kann man den Datensatz aufteilen nach einem bestimmten Kriterium. Hier Habe ich das Kriterium „survived is true“ gewählt. Im T-Output wandern dann nur Daten der überlebenden Passagiere und durch den F-Output fließen nur Daten der verstorbenen Passagiere.
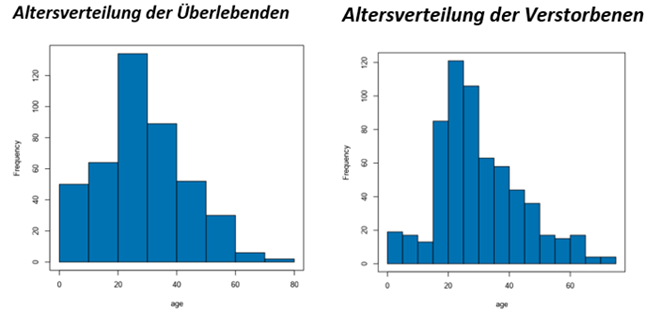
Zwar wirkt die Verteilung aufgrund der Linkausrichtung ähnlich, doch kann man deutlich erkennen, dass der relative Abstand zwischen den 0-20 jährigen und den 20-30 Jährigen geschrumpft ist. Man könnte das zum Beispiel so interpretieren, dass den 0 bis 19 Jährigen tatsächlich der Vortritt gelassen wurde.
Es gibt noch viele weitere Möglichkeiten der visuellen Analyse, doch würden weitere den Rahmen dieses Blogbeitrages sprengen.
Ich hoffe, ich konnte dir einen guten Einblick in die explorative Datenanalyse mit Alteryx verschaffen.