Today's Challenge: Scrape and Visualise
Day 4 presented us with a challenging task: to scrape data from a website and transform it into compelling visualisations. While the requirements were straightforward, the data preparation phase was anything but.
The Task: Visualising London Marathon's Historical Results (2014-2023)
The Requirements:
- We had to input the first two letters of participants' surnames into the website's search box, which had to be the same as ours (for me "Do".
- We had to bravely venture into the depths of data, downloading the historical results for each page, for each year.
The Journey:
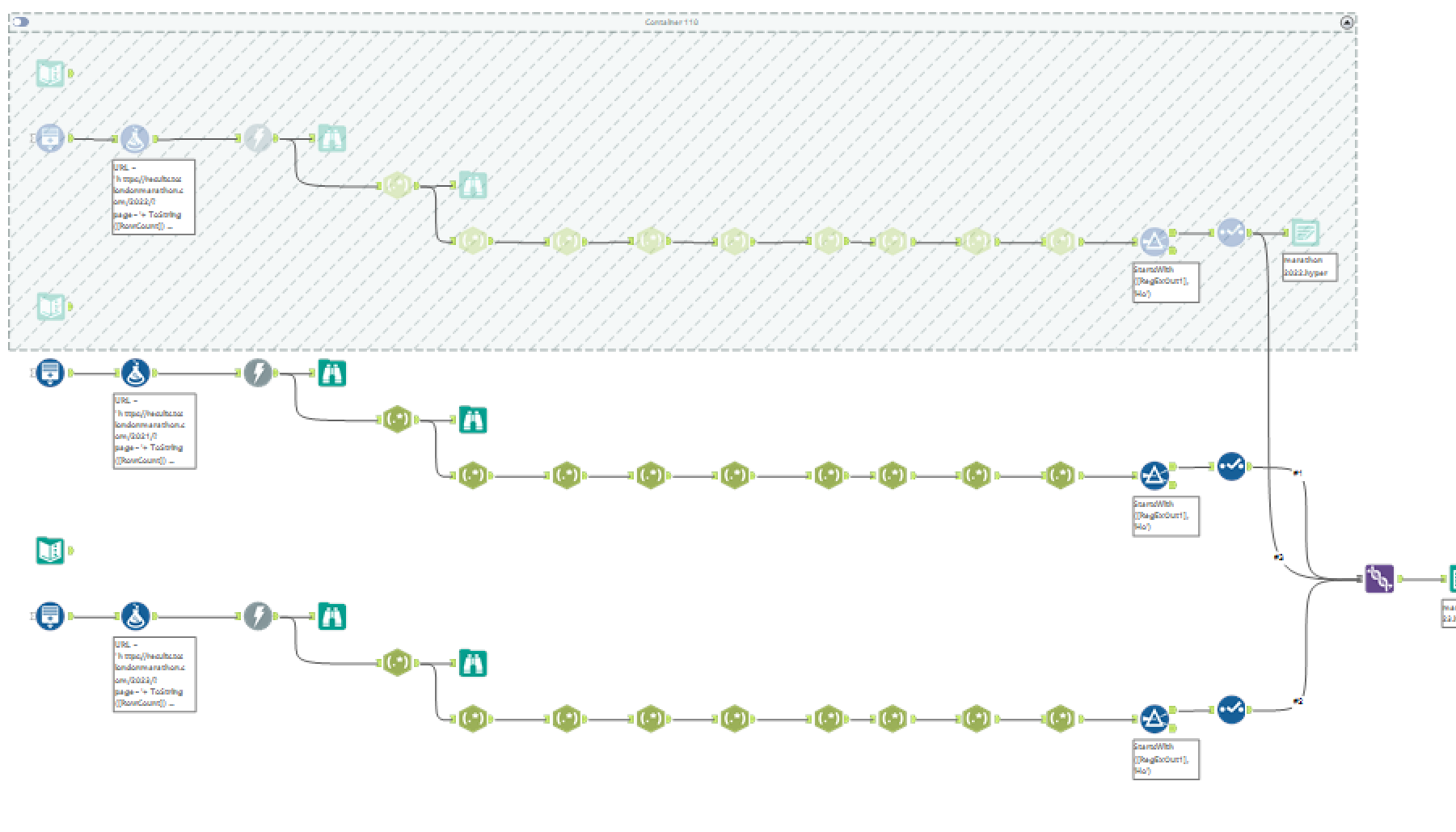
My journey began with the task of scraping data using Alteryx. However, like in any challenging endeavor, I soon encountered a significant obstacle: I was unable to retrieve data for all participants whose last names began with "Do."
Facing this roadblock, I turned to ChatGPT, which has consistently been a helpful tool for me. I asked ChatGPT to generate a Python script to assist me in my mission. While it wasn't without its share of challenges, it took a few iterations for ChatGPT to provide me with a functional script. However, it's worth noting that this script was initially tailored for just one year's worth of data. Below is a glimpse of the code:

But I didn't give up. I wanted to try both Alteryx and ChatGPT. After some experimenting, I got Alteryx to work, and it collected data for multiple years.
Comparing ChatGPT and Alteryx, I found that ChatGPT was faster but better suited for single URLs. Alteryx, on the other hand, handled multiple URLs well, so I chose to use it for this task.
Below is the workflow: